 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRUST-Bench: A Comprehensive Benchmark for C-to-safe-Rust Transpilation
Apr 21, 2025C-to-Rust transpilation is essential for modernizing legacy C code while enhancing safety and interoperability with modern Rust ecosystems. However, no dataset currently exists for evaluating whether a system can transpile C into safe Rust that passes a set of test cases. We introduce CRUST-Bench, a dataset of 100 C repositories, each paired with manually-written interfaces in safe Rust as well as test cases that can be used to validate correctness of the transpilation. By considering entire repositories rather than isolated functions, CRUST-Bench captures the challenges of translating complex projects with dependencies across multiple files. The provided Rust interfaces provide explicit specifications that ensure adherence to idiomatic, memory-safe Rust patterns, while the accompanying test cases enforce functional correctness. We evaluate state-of-the-art large language models (LLMs) on this task and find that safe and idiomatic Rust generation is still a challenging problem for various state-of-the-art methods and techniques. We also provide insights into the errors LLMs usually make in transpiling code from C to safe Rust. The best performing model, OpenAI o1, is able to solve only 15 tasks in a single-shot setting. Improvements on CRUST-Bench would lead to improved transpilation systems that can reason about complex scenarios and help in migrating legacy codebases from C into languages like Rust that ensure memory safety. You can find the dataset and code at https://github.com/anirudhkhatry/CRUST-bench.
Dynamic Model Predictive Shielding for Provably Safe Reinforcement Learning
May 22, 2024Among approaches for provably safe reinforcement learning, Model Predictive Shielding (MPS) has proven effective at complex tasks in continuous, high-dimensional state spaces, by leveraging a backup policy to ensure safety when the learned policy attempts to take risky actions. However, while MPS can ensure safety both during and after training, it often hinders task progress due to the conservative and task-oblivious nature of backup policies. This paper introduces Dynamic Model Predictive Shielding (DMPS), which optimizes reinforcement learning objectives while maintaining provable safety. DMPS employs a local planner to dynamically select safe recovery actions that maximize both short-term progress as well as long-term rewards. Crucially, the planner and the neural policy play a synergistic role in DMPS. When planning recovery actions for ensuring safety, the planner utilizes the neural policy to estimate long-term rewards, allowing it to observe beyond its short-term planning horizon. Conversely, the neural policy under training learns from the recovery plans proposed by the planner, converging to policies that are both high-performing and safe in practice. This approach guarantees safety during and after training, with bounded recovery regret that decreases exponentially with planning horizon depth. Experimental results demonstrate that DMPS converges to policies that rarely require shield interventions after training and achieve higher rewards compared to several state-of-the-art baselines.
Synapse: Learning Preferential Concepts from Visual Demonstrations
Mar 25, 2024This paper addresses the problem of preference learning, which aims to learn user-specific preferences (e.g., "good parking spot", "convenient drop-off location") from visual input. Despite its similarity to learning factual concepts (e.g., "red cube"), preference learning is a fundamentally harder problem due to its subjective nature and the paucity of person-specific training data. We address this problem using a new framework called Synapse, which is a neuro-symbolic approach designed to efficiently learn preferential concepts from limited demonstrations. Synapse represents preferences as neuro-symbolic programs in a domain-specific language (DSL) that operates over images, and leverages a novel combination of visual parsing, large language models, and program synthesis to learn programs representing individual preferences. We evaluate Synapse through extensive experimentation including a user case study focusing on mobility-related concepts in mobile robotics and autonomous driving. Our evaluation demonstrates that Synapse significantly outperforms existing baselines as well as its own ablations. The code and other details can be found on the project website https://amrl.cs.utexas.edu/synapse .
On a Foundation Model for Operating Systems
Dec 13, 2023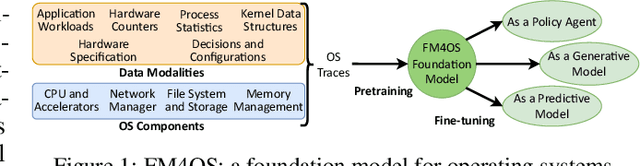
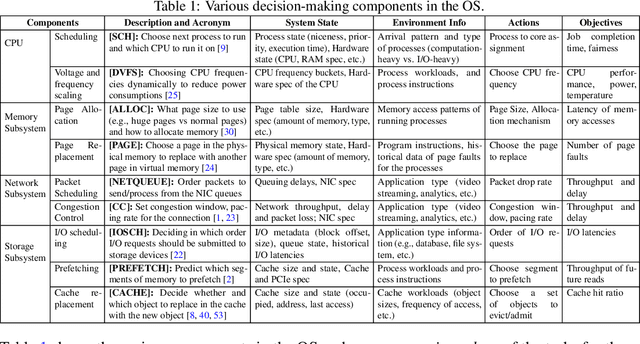
This paper lays down the research agenda for a domain-specific foundation model for operating systems (OSes). Our case for a foundation model revolves around the observations that several OS components such as CPU, memory, and network subsystems are interrelated and that OS traces offer the ideal dataset for a foundation model to grasp the intricacies of diverse OS components and their behavior in varying environments and workloads. We discuss a wide range of possibilities that then arise, from employing foundation models as policy agents to utilizing them as generators and predictors to assist traditional OS control algorithms. Our hope is that this paper spurs further research into OS foundation models and creating the next generation of operating systems for the evolving computing landscape.
Coeditor: Leveraging Contextual Changes for Multi-round Code Auto-editing
May 29, 2023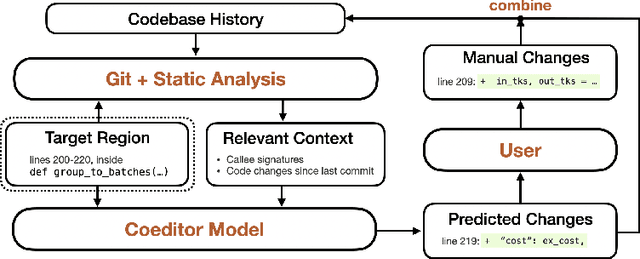
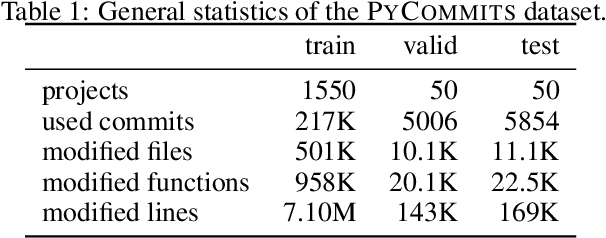
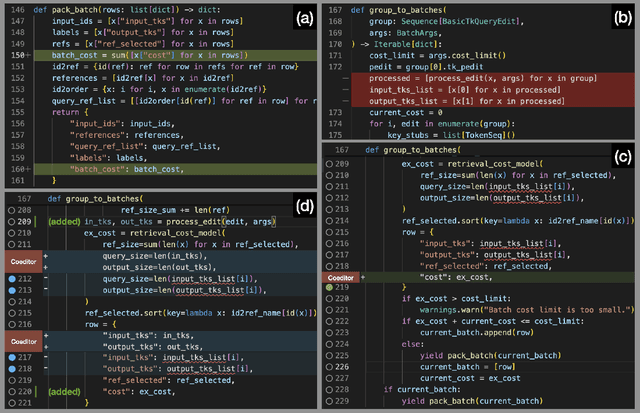

Developers often dedicate significant time to maintaining and refactoring existing code. However, most prior work on generative models for code focuses solely on creating new code, neglecting the unique requirements of editing existing code. In this work, we explore a multi-round code auto-editing setting, aiming to predict edits to a code region based on recent changes within the same codebase. Our model, Coeditor, is a fine-tuned CodeT5 model with enhancements specifically designed for code editing tasks. We encode code changes using a line diff format and employ static analysis to form large customized model contexts, ensuring appropriate information for prediction. We collect a code editing dataset from the commit histories of 1650 open-source Python projects for training and evaluation. In a simplified single-round, single-edit task, Coeditor significantly outperforms the best code completion approach -- nearly doubling its exact-match accuracy, despite using a much smaller model -- demonstrating the benefits of incorporating editing history for code completion. In a multi-round, multi-edit setting, we observe substantial gains by iteratively prompting the model with additional user edits. We open-source our code, data, and model weights to encourage future research and release a VSCode extension powered by our model for interactive usage.
Satisfiability-Aided Language Models Using Declarative Prompting
May 17, 2023Prior work has combined chain-of-thought prompting in large language models (LLMs) with programmatic representations to perform effective and transparent reasoning. While such an approach works very well for tasks that only require forward reasoning (e.g., straightforward arithmetic), it is less effective for constraint solving problems that require more sophisticated planning and search. In this paper, we propose a new satisfiability-aided language modeling (SATLM) approach for improving the reasoning capabilities of LLMs. We use an LLM to generate a declarative task specification rather than an imperative program and leverage an off-the-shelf automated theorem prover to derive the final answer. This approach has two key advantages. The declarative specification is closer to the problem description than the reasoning steps are, so the LLM can parse it out of the description more accurately. Furthermore, by offloading the actual reasoning task to an automated theorem prover, our approach can guarantee the correctness of the answer with respect to the parsed specification and avoid planning errors in the solving process. We evaluate SATLM on 6 different datasets and show that it consistently outperforms program-aided LMs in an imperative paradigm. In particular, SATLM outperforms program-aided LMs by 23% on a challenging subset of the GSM arithmetic reasoning dataset; SATLM also achieves a new SoTA on LSAT, surpassing previous models that are trained on the full training set.
ImageEye: Batch Image Processing Using Program Synthesis
Apr 10, 2023



This paper presents a new synthesis-based approach for batch image processing. Unlike existing tools that can only apply global edits to the entire image, our method can apply fine-grained edits to individual objects within the image. For example, our method can selectively blur or crop specific objects that have a certain property. To facilitate such fine-grained image editing tasks, we propose a neuro-symbolic domain-specific language (DSL) that combines pre-trained neural networks for image classification with other language constructs that enable symbolic reasoning. Our method can automatically learn programs in this DSL from user demonstrations by utilizing a novel synthesis algorithm. We have implemented the proposed technique in a tool called ImageEye and evaluated it on 50 image editing tasks. Our evaluation shows that ImageEye is able to automate 96% of these tasks.
TypeT5: Seq2seq Type Inference using Static Analysis
Mar 16, 2023There has been growing interest in automatically predicting missing type annotations in programs written in Python and JavaScript. While prior methods have achieved impressive accuracy when predicting the most common types, they often perform poorly on rare or complex types. In this paper, we present a new type inference method that treats type prediction as a code infilling task by leveraging CodeT5, a state-of-the-art seq2seq pre-trained language model for code. Our method uses static analysis to construct dynamic contexts for each code element whose type signature is to be predicted by the model. We also propose an iterative decoding scheme that incorporates previous type predictions in the model's input context, allowing information exchange between related code elements. Our evaluation shows that the proposed approach, TypeT5, not only achieves a higher overall accuracy (particularly on rare and complex types) but also produces more coherent results with fewer type errors -- while enabling easy user intervention.
PLUNDER: Probabilistic Program Synthesis for Learning from Unlabeled and Noisy Demonstrations
Mar 02, 2023
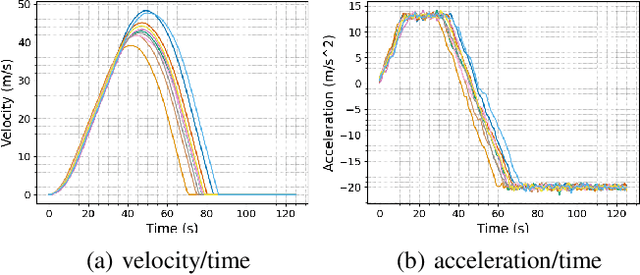


Learning from demonstration (LfD) is a widely researched paradigm for teaching robots to perform novel tasks. LfD works particularly well with program synthesis since the resulting programmatic policy is data efficient, interpretable, and amenable to formal verification. However, existing synthesis approaches to LfD rely on precise and labeled demonstrations and are incapable of reasoning about the uncertainty inherent in human decision-making. In this paper, we propose PLUNDER, a new LfD approach that integrates a probabilistic program synthesizer in an expectation-maximization (EM) loop to overcome these limitations. PLUNDER only requires unlabeled low-level demonstrations of the intended task (e.g., remote-controlled motion trajectories), which liberates end-users from providing explicit labels and facilitates a more intuitive LfD experience. PLUNDER also generates a probabilistic policy that captures actuation errors and the uncertainties inherent in human decision making. Our experiments compare PLUNDER with state-of the-art LfD techniques and demonstrate its advantages across different robotic tasks.
Guiding Safe Exploration with Weakest Preconditions
Sep 28, 2022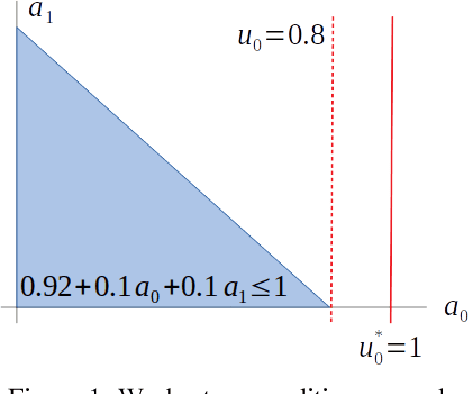
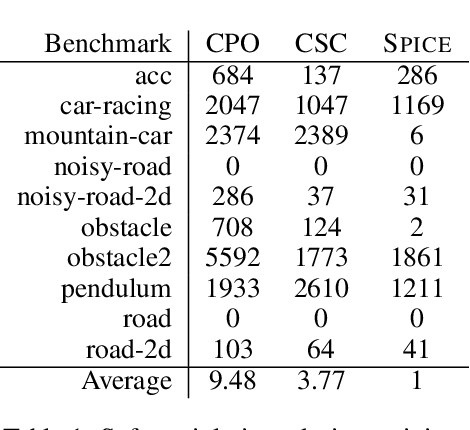
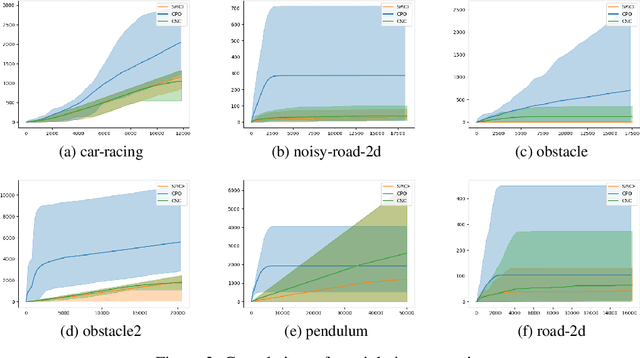
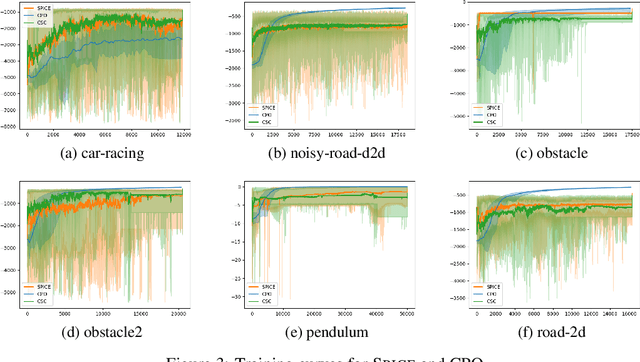
In reinforcement learning for safety-critical settings, it is often desirable for the agent to obey safety constraints at all points in time, including during training. We present a novel neurosymbolic approach called SPICE to solve this safe exploration problem. SPICE uses an online shielding layer based on symbolic weakest preconditions to achieve a more precise safety analysis than existing tools without unduly impacting the training process. We evaluate the approach on a suite of continuous control benchmarks and show that it can achieve comparable performance to existing safe learning techniques while incurring fewer safety violations. Additionally, we present theoretical results showing that SPICE converges to the optimal safe policy under reasonable assumptions.