 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot
Apr 15, 2026Scientific peer review faces mounting strain as submission volumes surge, making it increasingly difficult to sustain review quality, consistency, and timeliness. Recent advances in AI have led the community to consider its use in peer review, yet a key unresolved question is whether AI can generate technically sound reviews at real-world conference scale. Here we report the first large-scale field deployment of AI-assisted peer review: every main-track submission at AAAI-26 received one clearly identified AI review from a state-of-the-art system. The system combined frontier models, tool use, and safeguards in a multi-stage process to generate reviews for all 22,977 full-review papers in less than a day. A large-scale survey of AAAI-26 authors and program committee members showed that participants not only found AI reviews useful, but actually preferred them to human reviews on key dimensions such as technical accuracy and research suggestions. We also introduce a novel benchmark and find that our system substantially outperforms a simple LLM-generated review baseline at detecting a variety of scientific weaknesses. Together, these results show that state-of-the-art AI methods can already make meaningful contributions to scientific peer review at conference scale, opening a path toward the next generation of synergistic human-AI teaming for evaluating research.
SocialNav-SUB: Benchmarking VLMs for Scene Understanding in Social Robot Navigation
Sep 10, 2025Robot navigation in dynamic, human-centered environments requires socially-compliant decisions grounded in robust scene understanding. Recent Vision-Language Models (VLMs) exhibit promising capabilities such as object recognition, common-sense reasoning, and contextual understanding-capabilities that align with the nuanced requirements of social robot navigation. However, it remains unclear whether VLMs can accurately understand complex social navigation scenes (e.g., inferring the spatial-temporal relations among agents and human intentions), which is essential for safe and socially compliant robot navigation. While some recent works have explored the use of VLMs in social robot navigation, no existing work systematically evaluates their ability to meet these necessary conditions. In this paper, we introduce the Social Navigation Scene Understanding Benchmark (SocialNav-SUB), a Visual Question Answering (VQA) dataset and benchmark designed to evaluate VLMs for scene understanding in real-world social robot navigation scenarios. SocialNav-SUB provides a unified framework for evaluating VLMs against human and rule-based baselines across VQA tasks requiring spatial, spatiotemporal, and social reasoning in social robot navigation. Through experiments with state-of-the-art VLMs, we find that while the best-performing VLM achieves an encouraging probability of agreeing with human answers, it still underperforms simpler rule-based approach and human consensus baselines, indicating critical gaps in social scene understanding of current VLMs. Our benchmark sets the stage for further research on foundation models for social robot navigation, offering a framework to explore how VLMs can be tailored to meet real-world social robot navigation needs. An overview of this paper along with the code and data can be found at https://larg.github.io/socialnav-sub .
Joint Verification and Refinement of Language Models for Safety-Constrained Planning
Oct 18, 2024Although pre-trained language models can generate executable plans (e.g., programmatic policies) for solving robot tasks, the generated plans may violate task-relevant logical specifications due to the models' black-box nature. A significant gap remains between the language models' outputs and verifiable executions of plans. We develop a method to generate executable plans and formally verify them against task-relevant safety specifications. Given a high-level task description in natural language, the proposed method queries a language model to generate plans in the form of executable robot programs. It then converts the generated plan into an automaton-based representation, allowing formal verification of the automaton against the specifications. We prove that given a set of verified plans, the composition of these plans also satisfies the safety specifications. This proof ensures the safety of complex, multi-component plans, obviating the computation complexity of verifying the composed plan. We then propose an automated fine-tuning process that refines the language model to generate specification-compliant plans without the need for human labeling. The empirical results show a 30 percent improvement in the probability of generating plans that meet task specifications after fine-tuning.
Robo-Instruct: Simulator-Augmented Instruction Alignment For Finetuning CodeLLMs
May 30, 2024Large language models (LLMs) have shown great promise at generating robot programs from natural language given domain-specific robot application programming interfaces (APIs). However, the performance gap between proprietary LLMs and smaller open-weight LLMs remains wide. This raises a question: Can we fine-tune smaller open-weight LLMs for generating domain-specific robot programs to close the performance gap with proprietary LLMs? While Self-Instruct is a promising solution by generating a diverse set of training data, it cannot verify the correctness of these programs. In contrast, a robot simulator with a well-defined world can identify execution errors but limits the diversity of programs that it can verify. In this work, we introduce Robo-Instruct, which brings the best of both worlds -- it promotes the diversity of Self-Instruct while providing the correctness of simulator-based checking. Robo-Instruct introduces RoboSim to synthesize a consistent world state on the fly by inferring properties relevant to the program being checked, and simulating actions accordingly. Furthermore, the instructions and programs generated by Self-Instruct may be subtly inconsistent -- such as the program missing a step implied by the instruction. Robo-Instruct further addresses this with InstAlign, an instruction-program alignment procedure that revises the task instruction to reflect the actual results of the generated program. Given a few seed task descriptions and the robot APIs, Robo-Instruct is capable of generating a training dataset using only a small open-weight model. This dataset can then be used to fine-tune small open-weight language models, enabling them to match or even exceed the performance of several proprietary LLMs, such as GPT-3.5-Turbo and Gemini-Pro.
On a Foundation Model for Operating Systems
Dec 13, 2023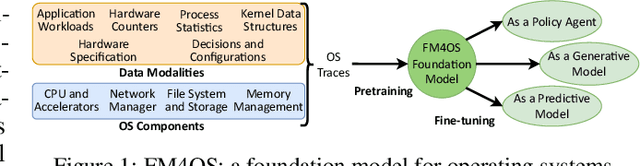
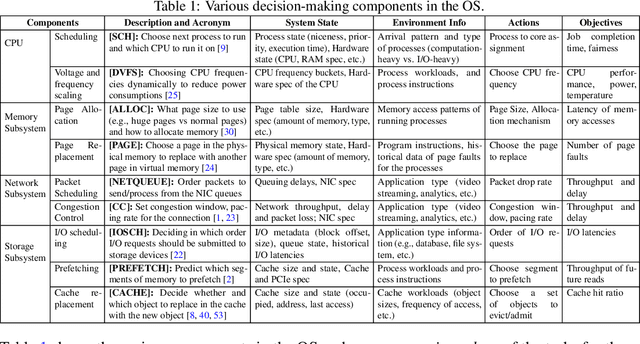
This paper lays down the research agenda for a domain-specific foundation model for operating systems (OSes). Our case for a foundation model revolves around the observations that several OS components such as CPU, memory, and network subsystems are interrelated and that OS traces offer the ideal dataset for a foundation model to grasp the intricacies of diverse OS components and their behavior in varying environments and workloads. We discuss a wide range of possibilities that then arise, from employing foundation models as policy agents to utilizing them as generators and predictors to assist traditional OS control algorithms. Our hope is that this paper spurs further research into OS foundation models and creating the next generation of operating systems for the evolving computing landscape.
Efficient 2D Graph SLAM for Sparse Sensing
Dec 04, 2023



Simultaneous localization and mapping (SLAM) plays a vital role in mapping unknown spaces and aiding autonomous navigation. Virtually all state-of-the-art solutions today for 2D SLAM are designed for dense and accurate sensors such as laser range-finders (LiDARs). However, these sensors are not suitable for resource-limited nano robots, which become increasingly capable and ubiquitous nowadays, and these robots tend to mount economical and low-power sensors that can only provide sparse and noisy measurements. This introduces a challenging problem called SLAM with sparse sensing. This work addresses the problem by adopting the form of the state-of-the-art graph-based SLAM pipeline with a novel frontend and an improvement for loop closing in the backend, both of which are designed to work with sparse and uncertain range data. Experiments show that the maps constructed by our algorithm have superior quality compared to prior works on sparse sensing. Furthermore, our method is capable of running in real-time on a modern PC with an average processing time of 1/100th the input interval time.
Deploying and Evaluating LLMs to Program Service Mobile Robots
Nov 18, 2023



Recent advancements in large language models (LLMs) have spurred interest in using them for generating robot programs from natural language, with promising initial results. We investigate the use of LLMs to generate programs for service mobile robots leveraging mobility, perception, and human interaction skills, and where accurate sequencing and ordering of actions is crucial for success. We contribute CodeBotler, an open-source robot-agnostic tool to program service mobile robots from natural language, and RoboEval, a benchmark for evaluating LLMs' capabilities of generating programs to complete service robot tasks. CodeBotler performs program generation via few-shot prompting of LLMs with an embedded domain-specific language (eDSL) in Python, and leverages skill abstractions to deploy generated programs on any general-purpose mobile robot. RoboEval evaluates the correctness of generated programs by checking execution traces starting with multiple initial states, and checking whether the traces satisfy temporal logic properties that encode correctness for each task. RoboEval also includes multiple prompts per task to test for the robustness of program generation. We evaluate several popular state-of-the-art LLMs with the RoboEval benchmark, and perform a thorough analysis of the modes of failures, resulting in a taxonomy that highlights common pitfalls of LLMs at generating robot programs. We release our code and benchmark at https://amrl.cs.utexas.edu/codebotler/.
Targeted Learning: A Hybrid Approach to Social Robot Navigation
Sep 23, 2023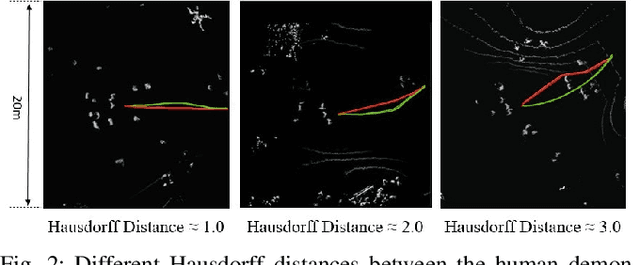



Empowering robots to navigate in a socially compliant manner is essential for the acceptance of robots moving in human-inhabited environments. Previously, roboticists have developed classical navigation systems with decades of empirical validation to achieve safety and efficiency. However, the many complex factors of social compliance make classical navigation systems hard to adapt to social situations, where no amount of tuning enables them to be both safe (people are too unpredictable) and efficient (the frozen robot problem). With recent advances in deep learning approaches, the common reaction has been to entirely discard classical navigation systems and start from scratch, building a completely new learning-based social navigation planner. In this work, we find that this reaction is unnecessarily extreme: using a large-scale real-world social navigation dataset, SCAND, we find that classical systems can be used safely and efficiently in a large number of social situations (up to 80%). We therefore ask if we can rethink this problem by leveraging the advantages of both classical and learning-based approaches. We propose a hybrid strategy in which we learn to switch between a classical geometric planner and a data-driven method. Our experiments on both SCAND and two physical robots show that the hybrid planner can achieve better social compliance in terms of a variety of metrics, compared to using either the classical or learning-based approach alone.