 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridStitch: Pixel and Timestep Level Model Stitching for Diffusion Acceleration
Mar 08, 2026Diffusion models have demonstrated a remarkable ability in Text-to-Image (T2I) generation applications. Despite the advanced generation output, they suffer from heavy computation overhead, especially for large models that contain tens of billions of parameters. Prior work has illustrated that replacing part of the denoising steps with a smaller model still maintains the generation quality. However, these methods only focus on saving computation for some timesteps, ignoring the difference in compute demand within one timestep. In this work, we propose HybridStitch, a new T2I generation paradigm that treats generation like editing. Specifically, we introduce a hybrid stage that jointly incorporates both the large model and the small model. HybridStitch separates the entire image into two regions: one that is relatively easy to render, enabling an early transition to the smaller model, and another that is more complex and therefore requires refinement by the large model. HybridStitch employs the small model to construct a coarse sketch while exploiting the large model to edit and refine the complex regions. According to our evaluation, HybridStitch achieves 1.83$\times$ speedup on Stable Diffusion 3, which is faster than all existing mixture of model methods.
A Knowledge Noise Mitigation Framework for Knowledge-based Visual Question Answering
Sep 11, 2025
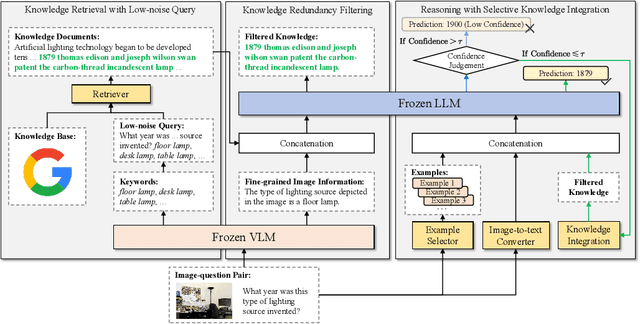
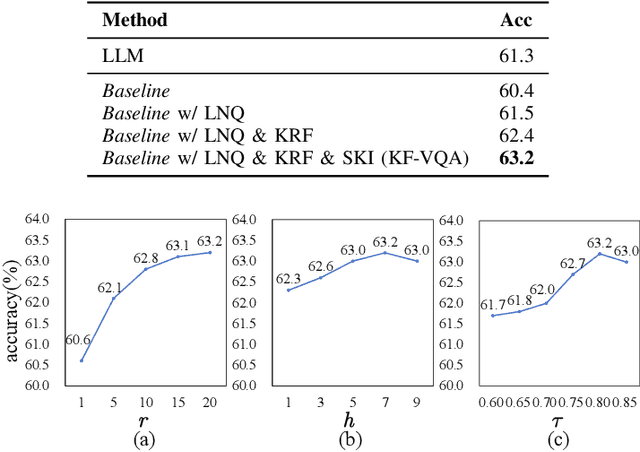

Knowledge-based visual question answering (KB-VQA) requires a model to understand images and utilize external knowledge to provide accurate answers. Existing approaches often directly augment models with retrieved information from knowledge sources while ignoring substantial knowledge redundancy, which introduces noise into the answering process. To address this, we propose a training-free framework with knowledge focusing for KB-VQA, that mitigates the impact of noise by enhancing knowledge relevance and reducing redundancy. First, for knowledge retrieval, our framework concludes essential parts from the image-question pairs, creating low-noise queries that enhance the retrieval of highly relevant knowledge. Considering that redundancy still persists in the retrieved knowledge, we then prompt large models to identify and extract answer-beneficial segments from knowledge. In addition, we introduce a selective knowledge integration strategy, allowing the model to incorporate knowledge only when it lacks confidence in answering the question, thereby mitigating the influence of redundant information. Our framework enables the acquisition of accurate and critical knowledge, and extensive experiments demonstrate that it outperforms state-of-the-art methods.
EnsembleCI: Ensemble Learning for Carbon Intensity Forecasting
May 04, 2025



Carbon intensity (CI) measures the average carbon emissions generated per unit of electricity, making it a crucial metric for quantifying and managing the environmental impact. Accurate CI predictions are vital for minimizing carbon footprints, yet the state-of-the-art method (CarbonCast) falls short due to its inability to address regional variability and lack of adaptability. To address these limitations, we introduce EnsembleCI, an adaptive, end-to-end ensemble learning-based approach for CI forecasting. EnsembleCI combines weighted predictions from multiple sublearners, offering enhanced flexibility and regional adaptability. In evaluations across 11 regional grids, EnsembleCI consistently surpasses CarbonCast, achieving the lowest mean absolute percentage error (MAPE) in almost all grids and improving prediction accuracy by an average of 19.58%. While performance still varies across grids due to inherent regional diversity, EnsembleCI reduces variability and exhibits greater robustness in long-term forecasting compared to CarbonCast and identifies region-specific key features, underscoring its interpretability and practical relevance. These findings position EnsembleCI as a more accurate and reliable solution for CI forecasting. EnsembleCI source code and data used in this paper are available at https://github.com/emmayly/EnsembleCI.
Towards Sustainable Large Language Model Serving
Dec 31, 2024



In this work, we study LLMs from a carbon emission perspective, addressing both operational and embodied emissions, and paving the way for sustainable LLM serving. We characterize the performance and energy of LLaMA with 1B, 3B, and 7B parameters using two Nvidia GPU types, a latest-generation RTX6000 Ada and an older-generation T4. We analytically model operational carbon emissions based on energy consumption and carbon intensities from three grid regions -- each representing a different energy source mix, and embodied carbon emissions based on chip area and memory size. Our characterization and modeling provide us with an in-depth understanding of the performance, energy, and carbon emissions of LLM serving. Our findings highlight the potential for optimizing sustainable LLM serving systems by considering both operational and embodied carbon emissions simultaneously.
EdgeRAG: Online-Indexed RAG for Edge Devices
Dec 30, 2024



Deploying Retrieval Augmented Generation (RAG) on resource-constrained edge devices is challenging due to limited memory and processing power. In this work, we propose EdgeRAG which addresses the memory constraint by pruning embeddings within clusters and generating embeddings on-demand during retrieval. To avoid the latency of generating embeddings for large tail clusters, EdgeRAG pre-computes and stores embeddings for these clusters, while adaptively caching remaining embeddings to minimize redundant computations and further optimize latency. The result from BEIR suite shows that EdgeRAG offers significant latency reduction over the baseline IVF index, but with similar generation quality while allowing all of our evaluated datasets to fit into the memory.
FreeRide: Harvesting Bubbles in Pipeline Parallelism
Sep 11, 2024



The occurrence of bubbles in pipeline parallelism is an inherent limitation that can account for more than 40% of the large language model (LLM) training time and is one of the main reasons for the underutilization of GPU resources in LLM training. Harvesting these bubbles for GPU side tasks can increase resource utilization and reduce training costs but comes with challenges. First, because bubbles are discontinuous with various shapes, programming side tasks becomes difficult while requiring excessive engineering effort. Second, a side task can compete with pipeline training for GPU resources and incur significant overhead. To address these challenges, we propose FreeRide, a system designed to harvest bubbles in pipeline parallelism for side tasks. FreeRide provides programmers with interfaces to implement side tasks easily, manages bubbles and side tasks during pipeline training, and controls access to GPU resources by side tasks to reduce overhead. We demonstrate that FreeRide achieves 7.8% average cost savings with a negligible overhead of about 1% in training LLMs while serving model training, graph analytics, and image processing side tasks.
Uncertainty-Aware Decarbonization for Datacenters
Jul 02, 2024This paper represents the first effort to quantify uncertainty in carbon intensity forecasting for datacenter decarbonization. We identify and analyze two types of uncertainty -- temporal and spatial -- and discuss their system implications. To address the temporal dynamics in quantifying uncertainty for carbon intensity forecasting, we introduce a conformal prediction-based framework. Evaluation results show that our technique robustly achieves target coverages in uncertainty quantification across various significance levels. We conduct two case studies using production power traces, focusing on temporal and spatial load shifting respectively. The results show that incorporating uncertainty into scheduling decisions can prevent a 5% and 14% increase in carbon emissions, respectively. These percentages translate to an absolute reduction of 2.1 and 10.4 tons of carbon emissions in a 20 MW datacenter cluster.
Efficient 2D Graph SLAM for Sparse Sensing
Dec 04, 2023



Simultaneous localization and mapping (SLAM) plays a vital role in mapping unknown spaces and aiding autonomous navigation. Virtually all state-of-the-art solutions today for 2D SLAM are designed for dense and accurate sensors such as laser range-finders (LiDARs). However, these sensors are not suitable for resource-limited nano robots, which become increasingly capable and ubiquitous nowadays, and these robots tend to mount economical and low-power sensors that can only provide sparse and noisy measurements. This introduces a challenging problem called SLAM with sparse sensing. This work addresses the problem by adopting the form of the state-of-the-art graph-based SLAM pipeline with a novel frontend and an improvement for loop closing in the backend, both of which are designed to work with sparse and uncertain range data. Experiments show that the maps constructed by our algorithm have superior quality compared to prior works on sparse sensing. Furthermore, our method is capable of running in real-time on a modern PC with an average processing time of 1/100th the input interval time.