 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXray-Visual Models: Scaling Vision models on Industry Scale Data
Feb 18, 2026We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
EnsembleCI: Ensemble Learning for Carbon Intensity Forecasting
May 04, 2025



Carbon intensity (CI) measures the average carbon emissions generated per unit of electricity, making it a crucial metric for quantifying and managing the environmental impact. Accurate CI predictions are vital for minimizing carbon footprints, yet the state-of-the-art method (CarbonCast) falls short due to its inability to address regional variability and lack of adaptability. To address these limitations, we introduce EnsembleCI, an adaptive, end-to-end ensemble learning-based approach for CI forecasting. EnsembleCI combines weighted predictions from multiple sublearners, offering enhanced flexibility and regional adaptability. In evaluations across 11 regional grids, EnsembleCI consistently surpasses CarbonCast, achieving the lowest mean absolute percentage error (MAPE) in almost all grids and improving prediction accuracy by an average of 19.58%. While performance still varies across grids due to inherent regional diversity, EnsembleCI reduces variability and exhibits greater robustness in long-term forecasting compared to CarbonCast and identifies region-specific key features, underscoring its interpretability and practical relevance. These findings position EnsembleCI as a more accurate and reliable solution for CI forecasting. EnsembleCI source code and data used in this paper are available at https://github.com/emmayly/EnsembleCI.
Scalable Primitives for Generalized Sensor Fusion in Autonomous Vehicles
Dec 01, 2021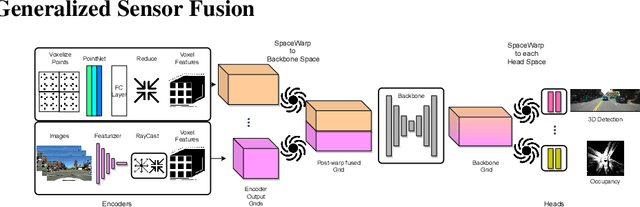
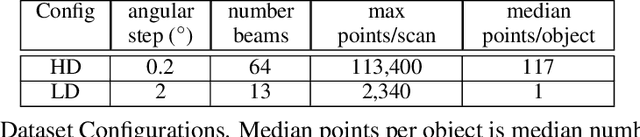
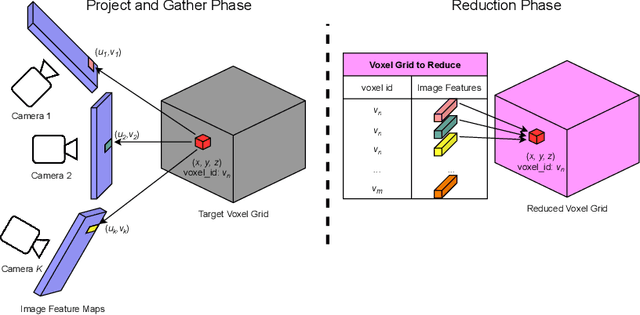

In autonomous driving, there has been an explosion in the use of deep neural networks for perception, prediction and planning tasks. As autonomous vehicles (AVs) move closer to production, multi-modal sensor inputs and heterogeneous vehicle fleets with different sets of sensor platforms are becoming increasingly common in the industry. However, neural network architectures typically target specific sensor platforms and are not robust to changes in input, making the problem of scaling and model deployment particularly difficult. Furthermore, most players still treat the problem of optimizing software and hardware as entirely independent problems. We propose a new end to end architecture, Generalized Sensor Fusion (GSF), which is designed in such a way that both sensor inputs and target tasks are modular and modifiable. This enables AV system designers to easily experiment with different sensor configurations and methods and opens up the ability to deploy on heterogeneous fleets using the same models that are shared across a large engineering organization. Using this system, we report experimental results where we demonstrate near-parity of an expensive high-density (HD) LiDAR sensor with a cheap low-density (LD) LiDAR plus camera setup in the 3D object detection task. This paves the way for the industry to jointly design hardware and software architectures as well as large fleets with heterogeneous configurations.
COVIDNet-CT: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest CT Images
Sep 08, 2020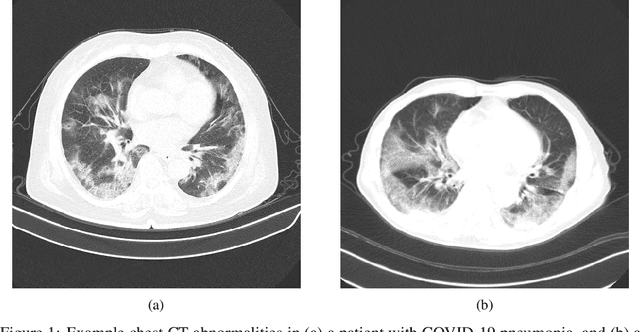

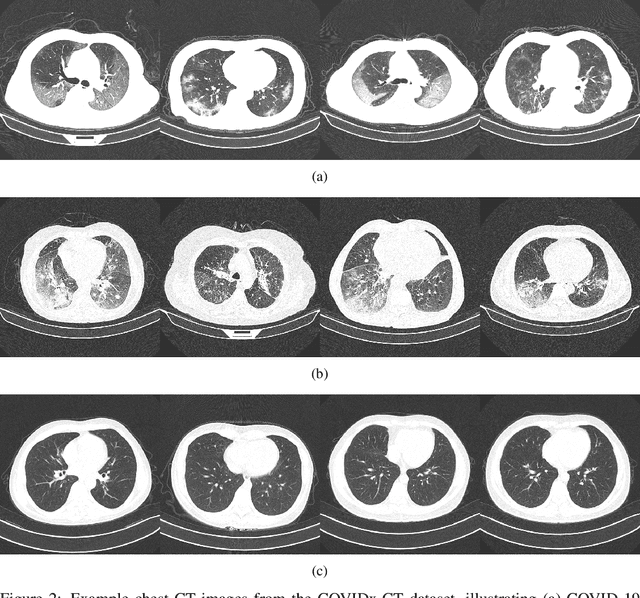
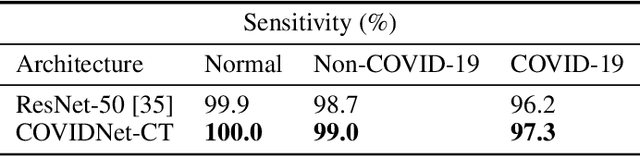
The coronavirus disease 2019 (COVID-19) pandemic continues to have a tremendous impact on patients and healthcare systems around the world. In the fight against this novel disease, there is a pressing need for rapid and effective screening tools to identify patients infected with COVID-19, and to this end CT imaging has been proposed as one of the key screening methods which may be used as a complement to RT-PCR testing, particularly in situations where patients undergo routine CT scans for non-COVID-19 related reasons, patients with worsening respiratory status or developing complications that require expedited care, and patients suspected to be COVID-19-positive but have negative RT-PCR test results. Motivated by this, in this study we introduce COVIDNet-CT, a deep convolutional neural network architecture that is tailored for detection of COVID-19 cases from chest CT images via a machine-driven design exploration approach. Additionally, we introduce COVIDx-CT, a benchmark CT image dataset derived from CT imaging data collected by the China National Center for Bioinformation comprising 104,009 images across 1,489 patient cases. Furthermore, in the interest of reliability and transparency, we leverage an explainability-driven performance validation strategy to investigate the decision-making behaviour of COVIDNet-CT, and in doing so ensure that COVIDNet-CT makes predictions based on relevant indicators in CT images. Both COVIDNet-CT and the COVIDx-CT dataset are available to the general public in an open-source and open access manner as part of the COVID-Net initiative. While COVIDNet-CT is not yet a production-ready screening solution, we hope that releasing the model and dataset will encourage researchers, clinicians, and citizen data scientists alike to leverage and build upon them.
EmotionNet Nano: An Efficient Deep Convolutional Neural Network Design for Real-time Facial Expression Recognition
Jun 29, 2020
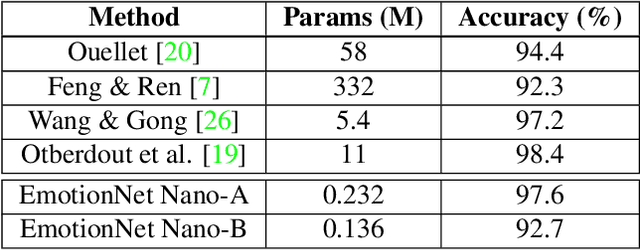
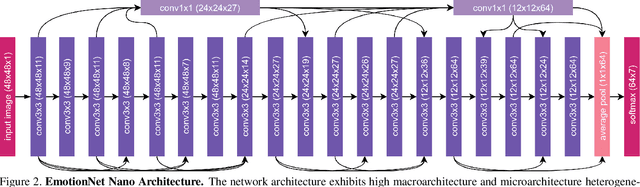
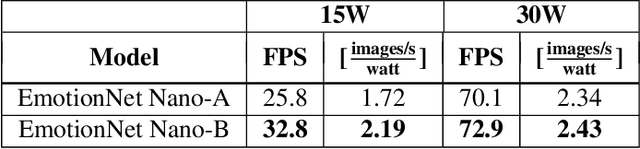
While recent advances in deep learning have led to significant improvements in facial expression classification (FEC), a major challenge that remains a bottleneck for the widespread deployment of such systems is their high architectural and computational complexities. This is especially challenging given the operational requirements of various FEC applications, such as safety, marketing, learning, and assistive living, where real-time requirements on low-cost embedded devices is desired. Motivated by this need for a compact, low latency, yet accurate system capable of performing FEC in real-time on low-cost embedded devices, this study proposes EmotionNet Nano, an efficient deep convolutional neural network created through a human-machine collaborative design strategy, where human experience is combined with machine meticulousness and speed in order to craft a deep neural network design catered towards real-time embedded usage. Two different variants of EmotionNet Nano are presented, each with a different trade-off between architectural and computational complexity and accuracy. Experimental results using the CK+ facial expression benchmark dataset demonstrate that the proposed EmotionNet Nano networks demonstrated accuracies comparable to state-of-the-art in FEC networks, while requiring significantly fewer parameters (e.g., 23$\times$ fewer at a higher accuracy). Furthermore, we demonstrate that the proposed EmotionNet Nano networks achieved real-time inference speeds (e.g. $>25$ FPS and $>70$ FPS at 15W and 30W, respectively) and high energy efficiency (e.g. $>1.7$ images/sec/watt at 15W) on an ARM embedded processor, thus further illustrating the efficacy of EmotionNet Nano for deployment on embedded devices.
Towards computer-aided severity assessment: training and validation of deep neural networks for geographic extent and opacity extent scoring of chest X-rays for SARS-CoV-2 lung disease severity
May 27, 2020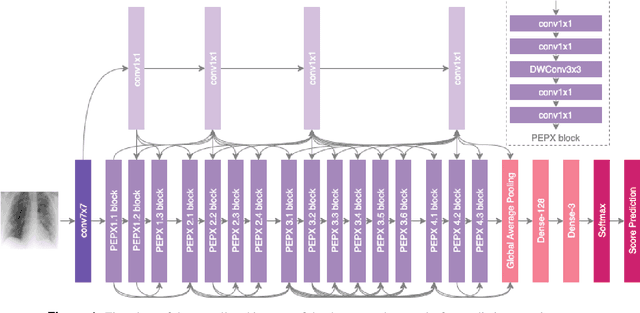
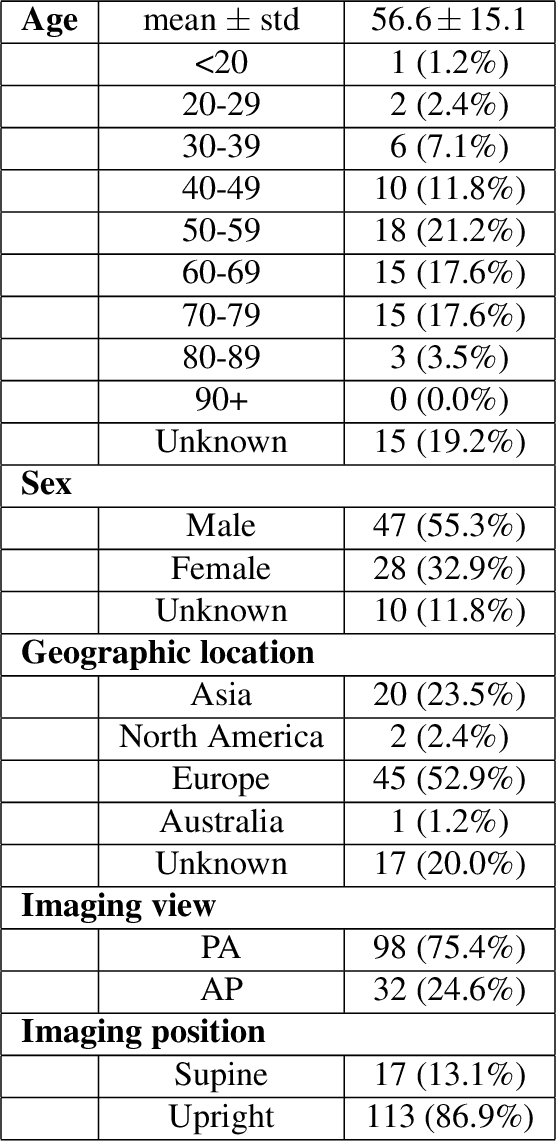
Background: A critical step in effective care and treatment planning for severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) is the assessment of the severity of disease progression. Chest x-rays (CXRs) are often used to assess SARS-CoV-2 severity, with two important assessment metrics being extent of lung involvement and degree of opacity. In this proof-of-concept study, we assess the feasibility of computer-aided scoring of CXRs of SARS-CoV-2 lung disease severity using a deep learning system. Materials and Methods: Data consisted of 130 CXRs from SARS-CoV-2 positive patient cases from the Cohen study. Geographic extent and opacity extent were scored by two board-certified expert chest radiologists (with 20+ years of experience) and a 2nd-year radiology resident. The deep neural networks used in this study are based on a COVID-Net network architecture. 100 versions of the network were independently learned (50 to perform geographic extent scoring and 50 to perform opacity extent scoring) using random subsets of CXRs from the Cohen study, and evaluated the networks using stratified Monte Carlo cross-validation experiments. Findings: The deep neural networks yielded R$^2$ of 0.673 $\pm$ 0.004 and 0.636 $\pm$ 0.002 between predicted scores and radiologist scores for geographic extent and opacity extent, respectively, in stratified Monte Carlo cross-validation experiments. The best performing networks achieved R$^2$ of 0.865 and 0.746 between predicted scores and radiologist scores for geographic extent and opacity extent, respectively. Interpretation: The results are promising and suggest that the use of deep neural networks on CXRs could be an effective tool for computer-aided assessment of SARS-CoV-2 lung disease severity, although additional studies are needed before adoption for routine clinical use.
DepthNet Nano: A Highly Compact Self-Normalizing Neural Network for Monocular Depth Estimation
Apr 17, 2020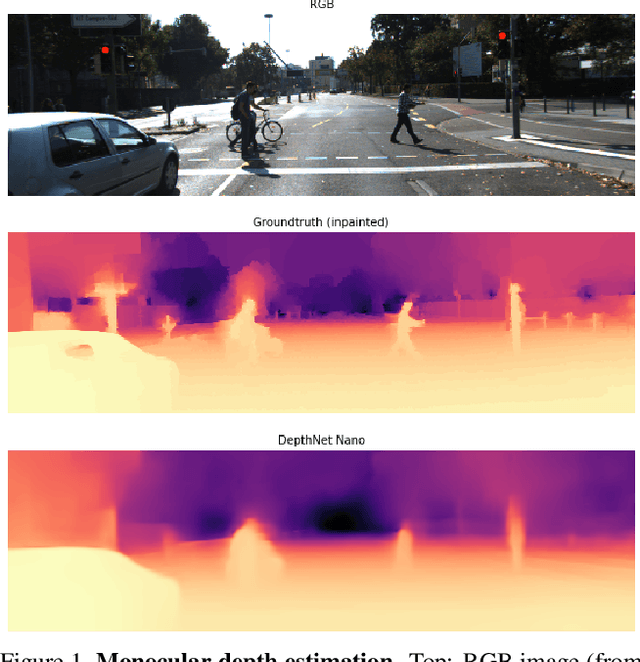
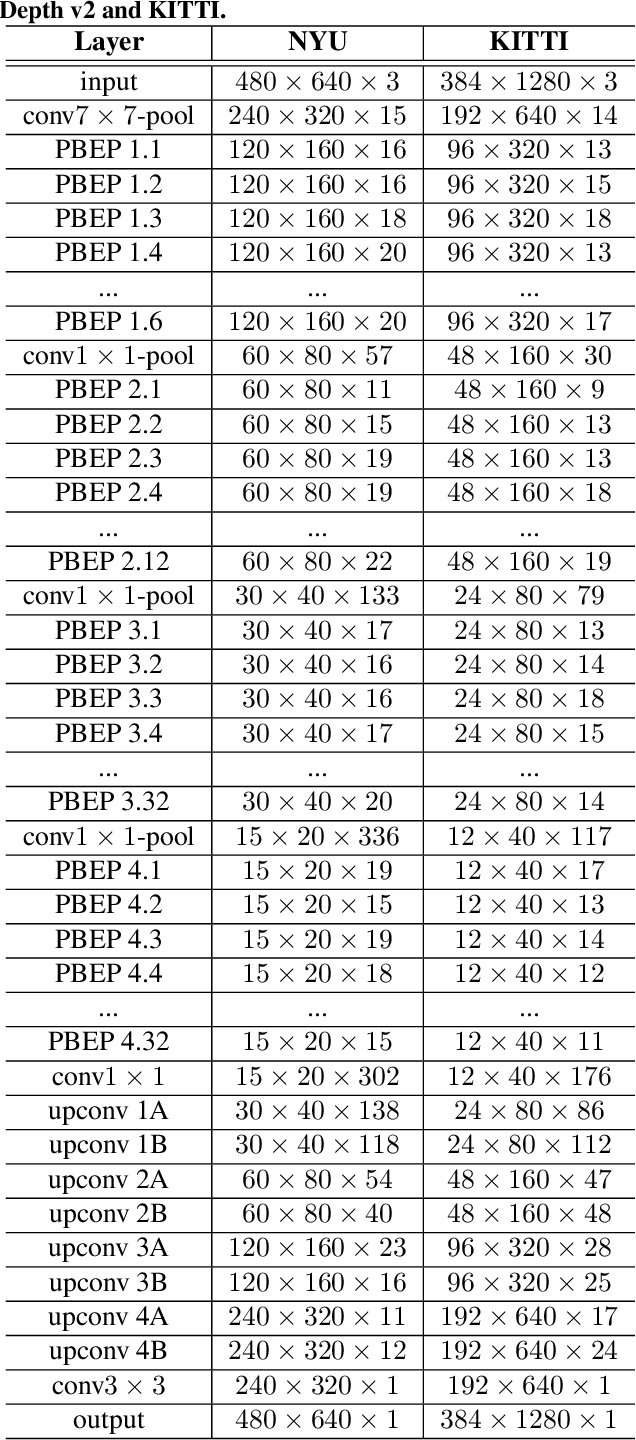
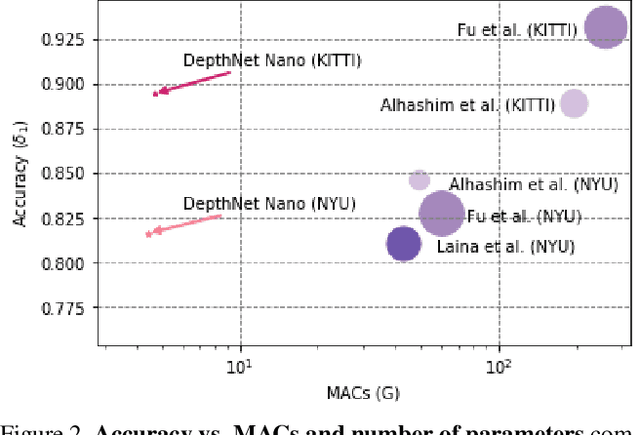

Depth estimation is an active area of research in the field of computer vision, and has garnered significant interest due to its rising demand in a large number of applications ranging from robotics and unmanned aerial vehicles to autonomous vehicles. A particularly challenging problem in this area is monocular depth estimation, where the goal is to infer depth from a single image. An effective strategy that has shown considerable promise in recent years for tackling this problem is the utilization of deep convolutional neural networks. Despite these successes, the memory and computational requirements of such networks have made widespread deployment in embedded scenarios very challenging. In this study, we introduce DepthNet Nano, a highly compact self normalizing network for monocular depth estimation designed using a human machine collaborative design strategy, where principled network design prototyping based on encoder-decoder design principles are coupled with machine-driven design exploration. The result is a compact deep neural network with highly customized macroarchitecture and microarchitecture designs, as well as self-normalizing characteristics, that are highly tailored for the task of embedded depth estimation. The proposed DepthNet Nano possesses a highly efficient network architecture (e.g., 24X smaller and 42X fewer MAC operations than Alhashim et al. on KITTI), while still achieving comparable performance with state-of-the-art networks on the NYU-Depth V2 and KITTI datasets. Furthermore, experiments on inference speed and energy efficiency on a Jetson AGX Xavier embedded module further illustrate the efficacy of DepthNet Nano at different resolutions and power budgets (e.g., ~14 FPS and >0.46 images/sec/watt at 384 X 1280 at a 30W power budget on KITTI).
COVID-Net: A Tailored Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest X-Ray Images
Apr 15, 2020



The COVID-19 pandemic continues to have a devastating effect on the health and well-being of the global population. A critical step in the fight against COVID-19 is effective screening of infected patients, with one of the key screening approaches being radiological imaging using chest radiography. Motivated by this, a number of artificial intelligence (AI) systems based on deep learning have been proposed and results have been shown to be quite promising in terms of accuracy in detecting patients infected with COVID-19 using chest radiography images. However, to the best of the authors' knowledge, these developed AI systems have been closed source and unavailable to the research community for deeper understanding and extension, and unavailable for public access and use. Therefore, in this study we introduce COVID-Net, a deep convolutional neural network design tailored for the detection of COVID-19 cases from chest X-ray (CXR) images that is open source and available to the general public. We also describe the CXR dataset leveraged to train COVID-Net, which we will refer to as COVIDx and is comprised of 13,800 chest radiography images across 13,725 patient patient cases from three open access data repositories, one of which we introduced. Furthermore, we investigate how COVID-Net makes predictions using an explainability method in an attempt to gain deeper insights into critical factors associated with COVID cases, which can aid clinicians in improved screening. By no means a production-ready solution, the hope is that the open access COVID-Net, along with the description on constructing the open source COVIDx dataset, will be leveraged and build upon by both researchers and citizen data scientists alike to accelerate the development of highly accurate yet practical deep learning solutions for detecting COVID-19 cases and accelerate treatment of those who need it the most.
Implications of Computer Vision Driven Assistive Technologies Towards Individuals with Visual Impairment
May 20, 2019
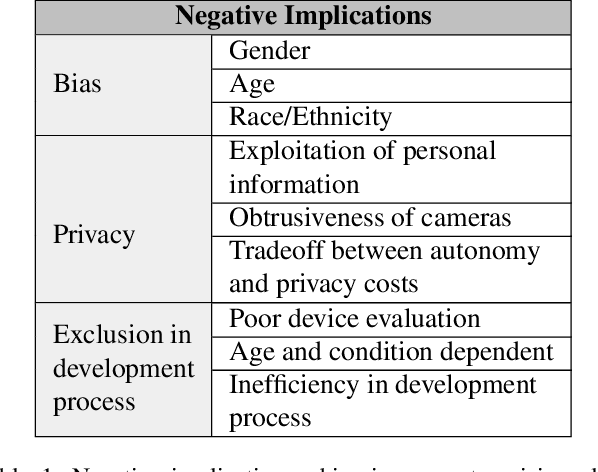
Computer vision based technology is becoming ubiquitous in society. One application area that has seen an increase in computer vision is assistive technologies, specifically for those with visual impairment. Research has shown the ability of computer vision models to achieve tasks such provide scene captions, detect objects and recognize faces. Although assisting individuals with visual impairment with these tasks increases their independence and autonomy, concerns over bias, privacy and potential usefulness arise. This paper addresses the positive and negative implications computer vision based assistive technologies have on individuals with visual impairment, as well as considerations for computer vision researchers and developers in order to mitigate the amount of negative implications.
Enabling Computer Vision Driven Assistive Devices for the Visually Impaired via Micro-architecture Design Exploration
May 20, 2019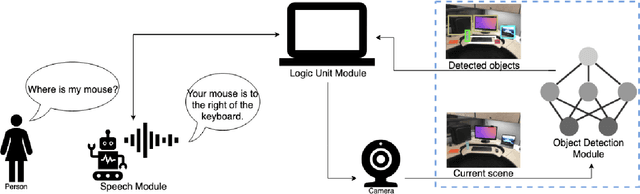

Recent improvements in object detection have shown potential to aid in tasks where previous solutions were not able to achieve. A particular area is assistive devices for individuals with visual impairment. While state-of-the-art deep neural networks have been shown to achieve superior object detection performance, their high computational and memory requirements make them cost prohibitive for on-device operation. Alternatively, cloud-based operation leads to privacy concerns, both not attractive to potential users. To address these challenges, this study investigates creating an efficient object detection network specifically for OLIV, an AI-powered assistant for object localization for the visually impaired, via micro-architecture design exploration. In particular, we formulate the problem of finding an optimal network micro-architecture as an numerical optimization problem, where we find the set of hyperparameters controlling the MobileNetV2-SSD network micro-architecture that maximizes a modified NetScore objective function for the MSCOCO-OLIV dataset of indoor objects. Experimental results show that such a micro-architecture design exploration strategy leads to a compact deep neural network with a balanced trade-off between accuracy, size, and speed, making it well-suited for enabling on-device computer vision driven assistive devices for the visually impaired.