 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards computer-aided severity assessment: training and validation of deep neural networks for geographic extent and opacity extent scoring of chest X-rays for SARS-CoV-2 lung disease severity
May 27, 2020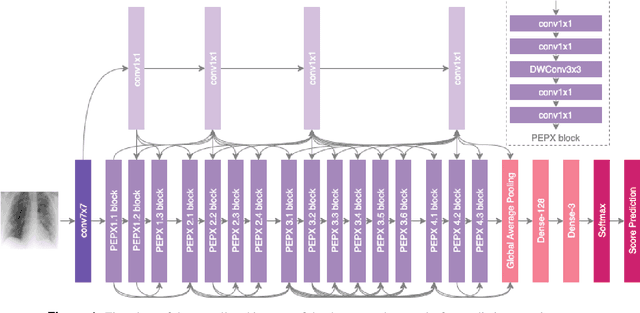
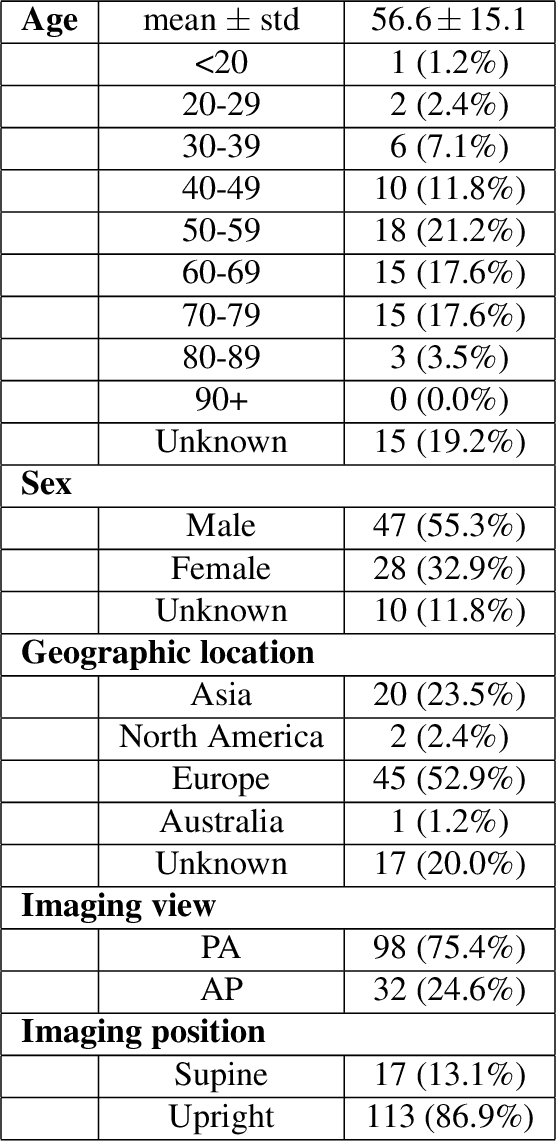
Background: A critical step in effective care and treatment planning for severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) is the assessment of the severity of disease progression. Chest x-rays (CXRs) are often used to assess SARS-CoV-2 severity, with two important assessment metrics being extent of lung involvement and degree of opacity. In this proof-of-concept study, we assess the feasibility of computer-aided scoring of CXRs of SARS-CoV-2 lung disease severity using a deep learning system. Materials and Methods: Data consisted of 130 CXRs from SARS-CoV-2 positive patient cases from the Cohen study. Geographic extent and opacity extent were scored by two board-certified expert chest radiologists (with 20+ years of experience) and a 2nd-year radiology resident. The deep neural networks used in this study are based on a COVID-Net network architecture. 100 versions of the network were independently learned (50 to perform geographic extent scoring and 50 to perform opacity extent scoring) using random subsets of CXRs from the Cohen study, and evaluated the networks using stratified Monte Carlo cross-validation experiments. Findings: The deep neural networks yielded R$^2$ of 0.673 $\pm$ 0.004 and 0.636 $\pm$ 0.002 between predicted scores and radiologist scores for geographic extent and opacity extent, respectively, in stratified Monte Carlo cross-validation experiments. The best performing networks achieved R$^2$ of 0.865 and 0.746 between predicted scores and radiologist scores for geographic extent and opacity extent, respectively. Interpretation: The results are promising and suggest that the use of deep neural networks on CXRs could be an effective tool for computer-aided assessment of SARS-CoV-2 lung disease severity, although additional studies are needed before adoption for routine clinical use.
PuckNet: Estimating hockey puck location from broadcast video
Dec 11, 2019

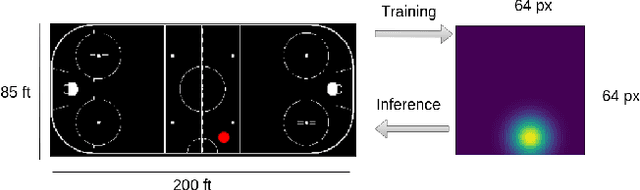
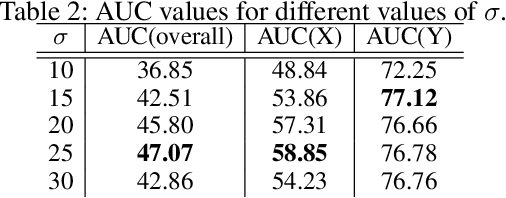
Puck location in ice hockey is essential for hockey analysts for determining the location of play and analyzing game events. However, because of the difficulty involved in obtaining accurate annotations due to the extremely low visibility and commonly occurring occlusions of the puck, the problem is very challenging. The problem becomes even more challenging in broadcast videos with changing camera angles. We introduce a novel methodology for determining puck location from approximate puck location annotations in broadcast video. Our method uniquely leverages the existing puck location information that is publicly available in existing hockey event data and uses the corresponding one-second broadcast video clips as input to the network. The rationale behind using video as input instead of static images is that with video, the temporal information can be utilized to handle puck occlusions. The network outputs a heatmap representing the probability of the puck location using a 3D CNN based architecture. The network is able to regress the puck location from broadcast hockey video clips with varying camera angles. Experimental results demonstrate the capability of the method, achieving 47.07% AUC on the test dataset. The network is also able to estimate the puck location in defensive/offensive zones with an accuracy of greater than 80%.
Do Explanations Reflect Decisions? A Machine-centric Strategy to Quantify the Performance of Explainability Algorithms
Oct 29, 2019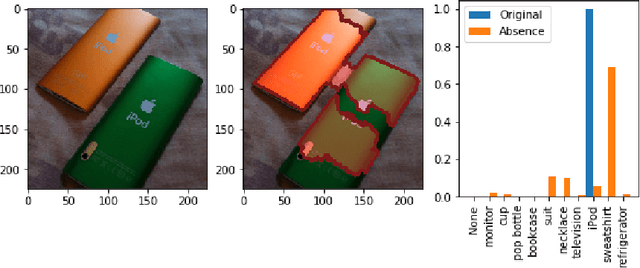
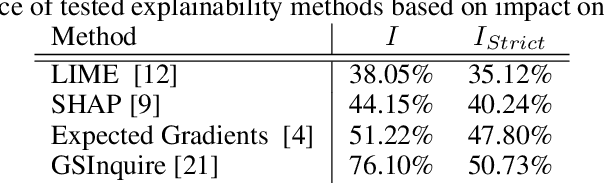
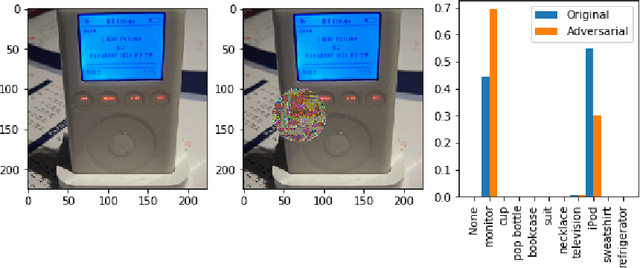

There has been a significant surge of interest recently around the concept of explainable artificial intelligence (XAI), where the goal is to produce an interpretation for a decision made by a machine learning algorithm. Of particular interest is the interpretation of how deep neural networks make decisions, given the complexity and `black box' nature of such networks. Given the infancy of the field, there has been very limited exploration into the assessment of the performance of explainability methods, with most evaluations centered around subjective visual interpretation of the produced interpretations. In this study, we explore a more machine-centric strategy for quantifying the performance of explainability methods on deep neural networks via the notion of decision-making impact analysis. We introduce two quantitative performance metrics: i) Impact Score, which assesses the percentage of critical factors with either strong confidence reduction impact or decision changing impact, and ii) Impact Coverage, which assesses the percentage coverage of adversarially impacted factors in the input. A comprehensive analysis using this approach was conducted on several state-of-the-art explainability methods (LIME, SHAP, Expected Gradients, GSInquire) on a ResNet-50 deep convolutional neural network using a subset of ImageNet for the task of image classification. Experimental results show that the critical regions identified by LIME within the tested images had the lowest impact on the decision-making process of the network (~38%), with progressive increase in decision-making impact for SHAP (~44%), Expected Gradients (~51%), and GSInquire (~76%). While by no means perfect, the hope is that the proposed machine-centric strategy helps push the conversation forward towards better metrics for evaluating explainability methods and improve trust in deep neural networks.
State of Compact Architecture Search For Deep Neural Networks
Oct 15, 2019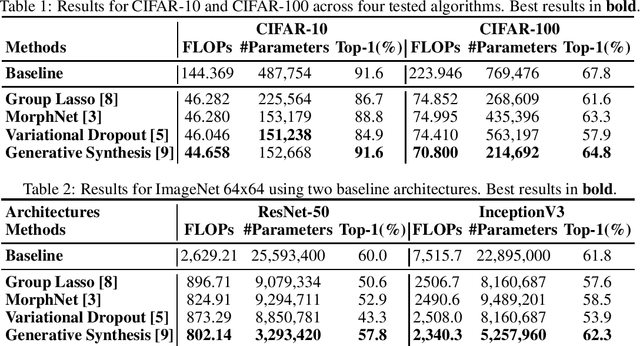
The design of compact deep neural networks is a crucial task to enable widespread adoption of deep neural networks in the real-world, particularly for edge and mobile scenarios. Due to the time-consuming and challenging nature of manually designing compact deep neural networks, there has been significant recent research interest into algorithms that automatically search for compact network architectures. A particularly interesting class of compact architecture search algorithms are those that are guided by baseline network architectures. Such algorithms have been shown to be significantly more computationally efficient than unguided methods. In this study, we explore the current state of compact architecture search for deep neural networks through both theoretical and empirical analysis of four different state-of-the-art compact architecture search algorithms: i) group lasso regularization, ii) variational dropout, iii) MorphNet, and iv) Generative Synthesis. We examine these methods in detail based on a number of different factors such as efficiency, effectiveness, and scalability. Furthermore, empirical evaluations are conducted to compare the efficacy of these compact architecture search algorithms across three well-known benchmark datasets. While by no means an exhaustive exploration, we hope that this study helps provide insights into the interesting state of this relatively new area of research in terms of diversity and real, tangible gains already achieved in architecture design improvements. Furthermore, the hope is that this study would help in pushing the conversation forward towards a deeper theoretical and empirical understanding where the research community currently stands in the landscape of compact architecture search for deep neural networks, and the practical challenges and considerations in leveraging such approaches for operational usage.
Squeeze-and-Attention Networks for Semantic Segmentation
Sep 10, 2019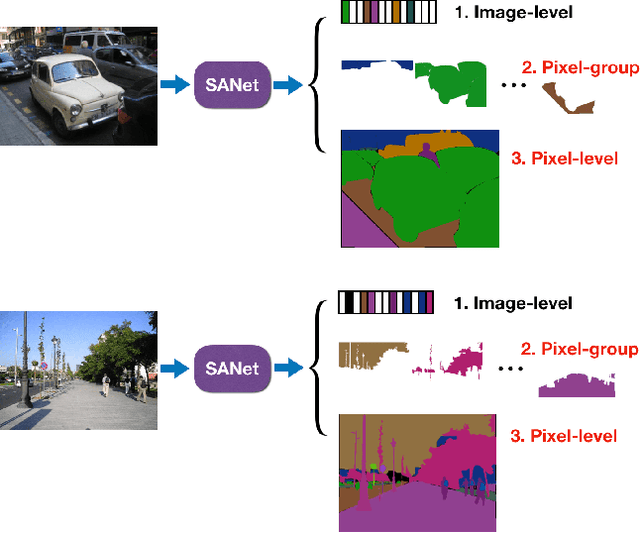
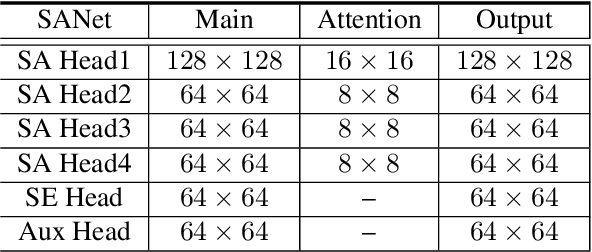

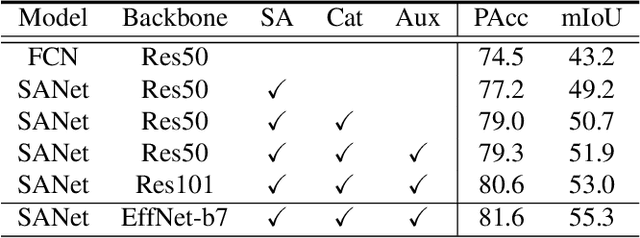
Squeeze-and-excitation (SE) module enhances the representational power of convolution layers by adaptively re-calibrating channel-wise feature responses. However, the limitation of SE in terms of attention characterization lies in the loss of spatial information cues, making it less well suited for perception tasks with very high spatial inter-dependencies such as semantic segmentation. In this paper, we propose a novel squeeze-and-attention network (SANet) architecture that leverages a simple but effective squeeze-and-attention (SA) module to account for two distinctive characteristics of segmentation: i) pixel-group attention, and ii) pixel-wise prediction. Specifically, the proposed SA modules impose pixel-group attention on conventional convolution by introducing an 'attention' convolutional channel, thus taking into account spatial-channel inter-dependencies in an efficient manner. The final segmentation results are produced by merging outputs from four hierarchical stages of a SANet to integrate multi-scale contexts for obtaining enhanced pixel-wise prediction. Empirical experiments using two challenging public datasets validate the effectiveness of the proposed SANets, which achieved 83.2% mIoU (without COCO pre-training) on PASCAL VOC and a state-of-the-art mIoU of 54.4% on PASCAL Context.
EdgeSegNet: A Compact Network for Semantic Segmentation
May 10, 2019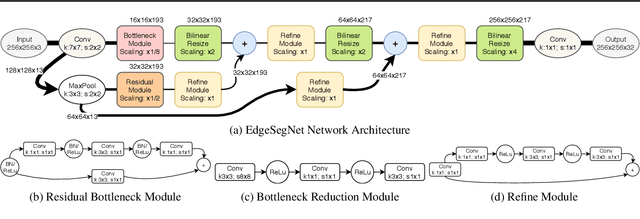

In this study, we introduce EdgeSegNet, a compact deep convolutional neural network for the task of semantic segmentation. A human-machine collaborative design strategy is leveraged to create EdgeSegNet, where principled network design prototyping is coupled with machine-driven design exploration to create networks with customized module-level macroarchitecture and microarchitecture designs tailored for the task. Experimental results showed that EdgeSegNet can achieve semantic segmentation accuracy comparable with much larger and computationally complex networks (>20x} smaller model size than RefineNet) as well as achieving an inference speed of ~38.5 FPS on an NVidia Jetson AGX Xavier. As such, the proposed EdgeSegNet is well-suited for low-power edge scenarios.
AttoNets: Compact and Efficient Deep Neural Networks for the Edge via Human-Machine Collaborative Design
Apr 15, 2019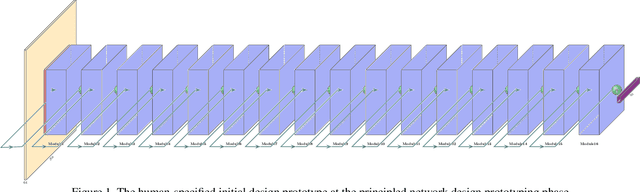
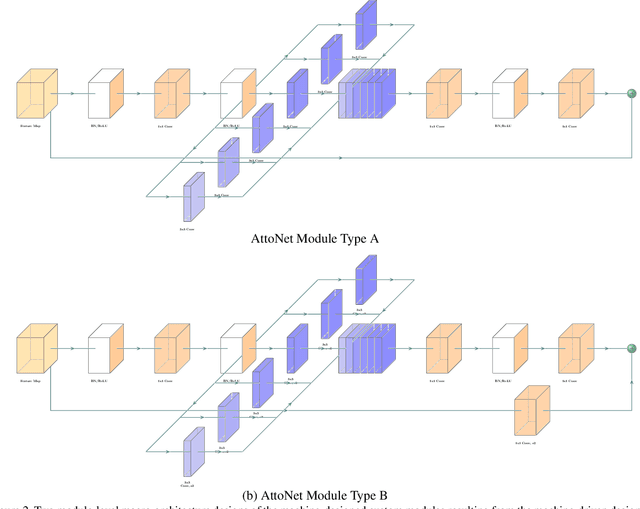
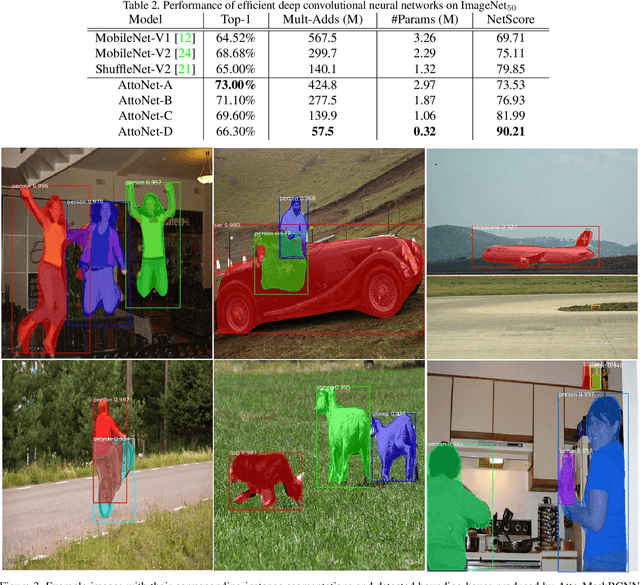
While deep neural networks have achieved state-of-the-art performance across a large number of complex tasks, it remains a big challenge to deploy such networks for practical, on-device edge scenarios such as on mobile devices, consumer devices, drones, and vehicles. In this study, we take a deeper exploration into a human-machine collaborative design approach for creating highly efficient deep neural networks through a synergy between principled network design prototyping and machine-driven design exploration. The efficacy of human-machine collaborative design is demonstrated through the creation of AttoNets, a family of highly efficient deep neural networks for on-device edge deep learning. Each AttoNet possesses a human-specified network-level macro-architecture comprising of custom modules with unique machine-designed module-level macro-architecture and micro-architecture designs, all driven by human-specified design requirements. Experimental results for the task of object recognition showed that the AttoNets created via human-machine collaborative design has significantly fewer parameters and computational costs than state-of-the-art networks designed for efficiency while achieving noticeably higher accuracy (with the smallest AttoNet achieving ~1.8% higher accuracy while requiring ~10x fewer multiply-add operations and parameters than MobileNet-V1). Furthermore, the efficacy of the AttoNets is demonstrated for the task of instance-level object segmentation and object detection, where an AttoNet-based Mask R-CNN network was constructed with significantly fewer parameters and computational costs (~5x fewer multiply-add operations and ~2x fewer parameters) than a ResNet-50 based Mask R-CNN network.
Progressive Label Distillation: Learning Input-Efficient Deep Neural Networks
Jan 26, 2019
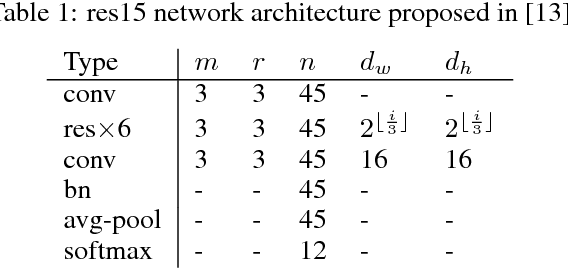
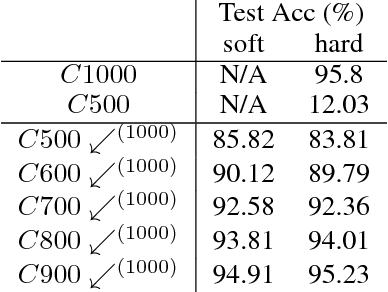
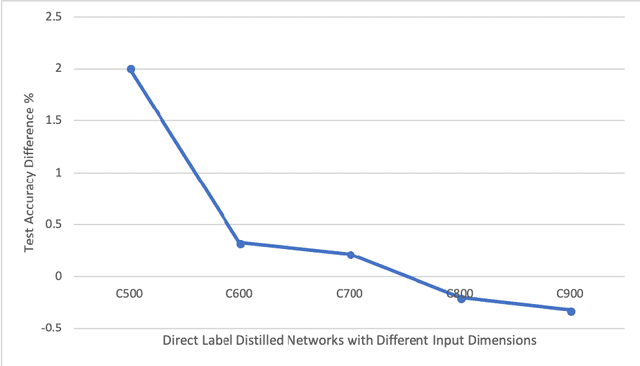
Much of the focus in the area of knowledge distillation has been on distilling knowledge from a larger teacher network to a smaller student network. However, there has been little research on how the concept of distillation can be leveraged to distill the knowledge encapsulated in the training data itself into a reduced form. In this study, we explore the concept of progressive label distillation, where we leverage a series of teacher-student network pairs to progressively generate distilled training data for learning deep neural networks with greatly reduced input dimensions. To investigate the efficacy of the proposed progressive label distillation approach, we experimented with learning a deep limited vocabulary speech recognition network based on generated 500ms input utterances distilled progressively from 1000ms source training data, and demonstrated a significant increase in test accuracy of almost 78% compared to direct learning.
EdgeSpeechNets: Highly Efficient Deep Neural Networks for Speech Recognition on the Edge
Oct 18, 2018
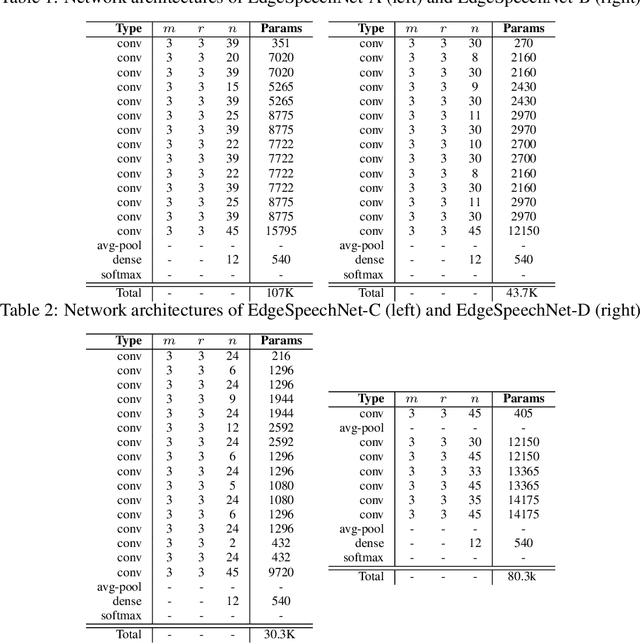
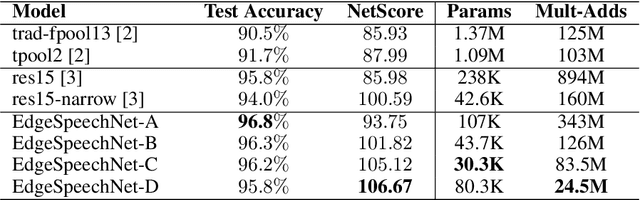
Despite showing state-of-the-art performance, deep learning for speech recognition remains challenging to deploy in on-device edge scenarios such as mobile and other consumer devices. Recently, there have been greater efforts in the design of small, low-footprint deep neural networks (DNNs) that are more appropriate for edge devices, with much of the focus on design principles for hand-crafting efficient network architectures. In this study, we explore a human-machine collaborative design strategy for building low-footprint DNN architectures for speech recognition through a marriage of human-driven principled network design prototyping and machine-driven design exploration. The efficacy of this design strategy is demonstrated through the design of a family of highly-efficient DNNs (nicknamed EdgeSpeechNets) for limited-vocabulary speech recognition. Experimental results using the Google Speech Commands dataset for limited-vocabulary speech recognition showed that EdgeSpeechNets have higher accuracies than state-of-the-art DNNs (with the best EdgeSpeechNet achieving ~97% accuracy), while achieving significantly smaller network sizes (as much as 7.8x smaller) and lower computational cost (as much as 36x fewer multiply-add operations, 10x lower prediction latency, and 16x smaller memory footprint on a Motorola Moto E phone), making them very well-suited for on-device edge voice interface applications.