 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueeze-and-Attention Networks for Semantic Segmentation
Paper and Code
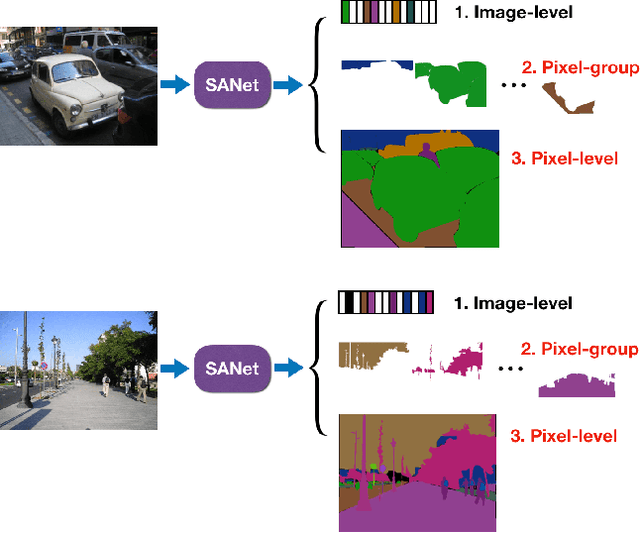
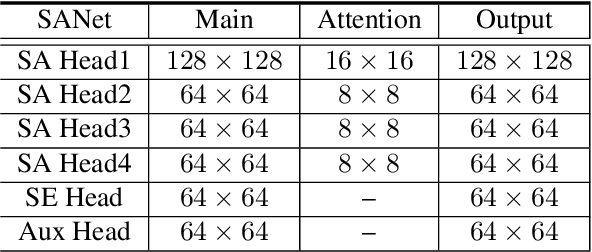

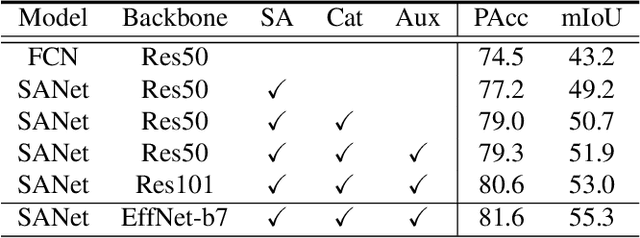
Squeeze-and-excitation (SE) module enhances the representational power of convolution layers by adaptively re-calibrating channel-wise feature responses. However, the limitation of SE in terms of attention characterization lies in the loss of spatial information cues, making it less well suited for perception tasks with very high spatial inter-dependencies such as semantic segmentation. In this paper, we propose a novel squeeze-and-attention network (SANet) architecture that leverages a simple but effective squeeze-and-attention (SA) module to account for two distinctive characteristics of segmentation: i) pixel-group attention, and ii) pixel-wise prediction. Specifically, the proposed SA modules impose pixel-group attention on conventional convolution by introducing an 'attention' convolutional channel, thus taking into account spatial-channel inter-dependencies in an efficient manner. The final segmentation results are produced by merging outputs from four hierarchical stages of a SANet to integrate multi-scale contexts for obtaining enhanced pixel-wise prediction. Empirical experiments using two challenging public datasets validate the effectiveness of the proposed SANets, which achieved 83.2% mIoU (without COCO pre-training) on PASCAL VOC and a state-of-the-art mIoU of 54.4% on PASCAL Context.