 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid-BERT: Reducing Complexity via Successive Core-set based Token Selection
Mar 27, 2022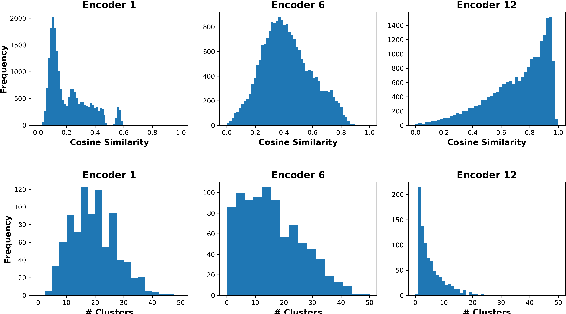
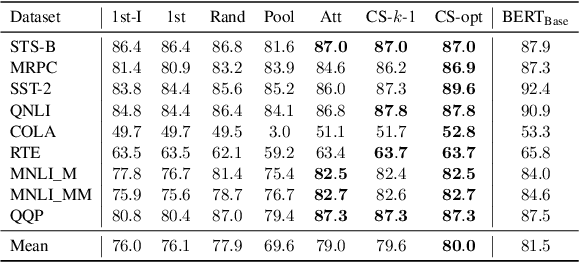
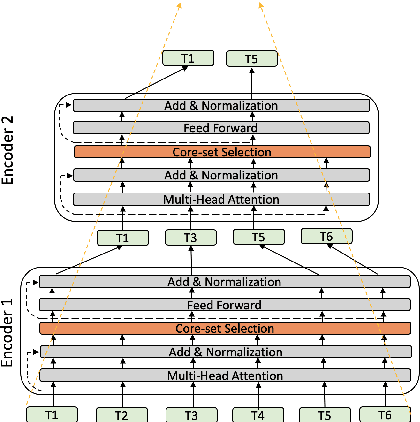
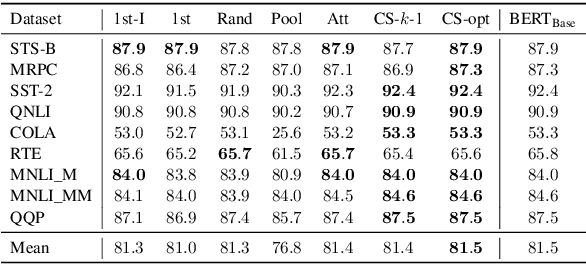
Transformer-based language models such as BERT have achieved the state-of-the-art performance on various NLP tasks, but are computationally prohibitive. A recent line of works use various heuristics to successively shorten sequence length while transforming tokens through encoders, in tasks such as classification and ranking that require a single token embedding for prediction. We present a novel solution to this problem, called Pyramid-BERT where we replace previously used heuristics with a {\em core-set} based token selection method justified by theoretical results. The core-set based token selection technique allows us to avoid expensive pre-training, gives a space-efficient fine tuning, and thus makes it suitable to handle longer sequence lengths. We provide extensive experiments establishing advantages of pyramid BERT over several baselines and existing works on the GLUE benchmarks and Long Range Arena datasets.
Squeeze-and-Attention Networks for Semantic Segmentation
Sep 10, 2019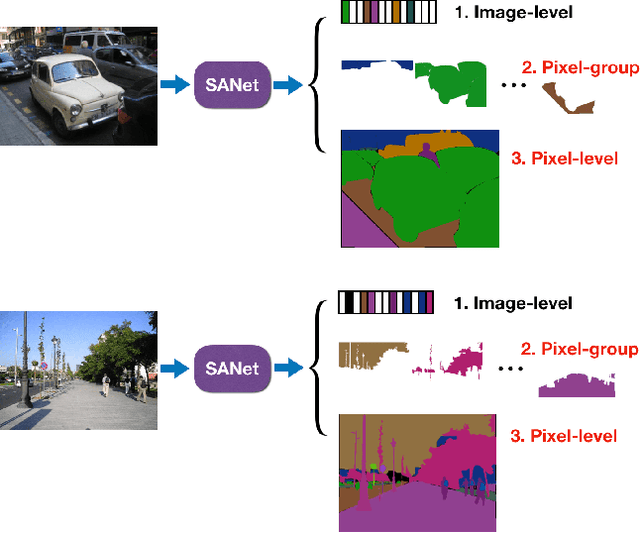
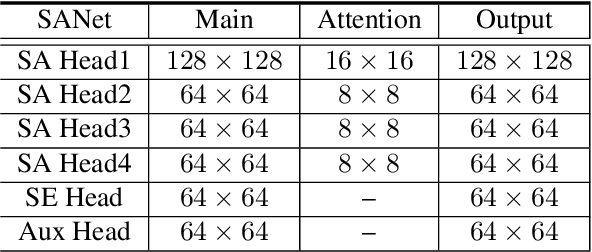

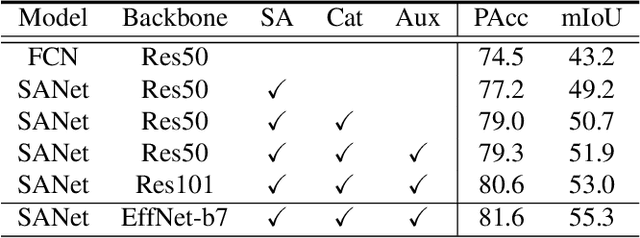
Squeeze-and-excitation (SE) module enhances the representational power of convolution layers by adaptively re-calibrating channel-wise feature responses. However, the limitation of SE in terms of attention characterization lies in the loss of spatial information cues, making it less well suited for perception tasks with very high spatial inter-dependencies such as semantic segmentation. In this paper, we propose a novel squeeze-and-attention network (SANet) architecture that leverages a simple but effective squeeze-and-attention (SA) module to account for two distinctive characteristics of segmentation: i) pixel-group attention, and ii) pixel-wise prediction. Specifically, the proposed SA modules impose pixel-group attention on conventional convolution by introducing an 'attention' convolutional channel, thus taking into account spatial-channel inter-dependencies in an efficient manner. The final segmentation results are produced by merging outputs from four hierarchical stages of a SANet to integrate multi-scale contexts for obtaining enhanced pixel-wise prediction. Empirical experiments using two challenging public datasets validate the effectiveness of the proposed SANets, which achieved 83.2% mIoU (without COCO pre-training) on PASCAL VOC and a state-of-the-art mIoU of 54.4% on PASCAL Context.
Affine Variational Autoencoders: An Efficient Approach for Improving Generalization and Robustness to Distribution Shift
May 13, 2019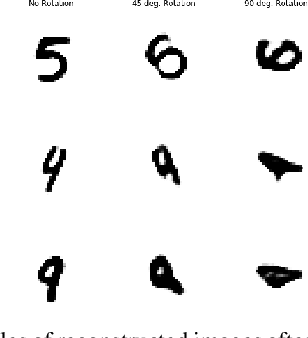

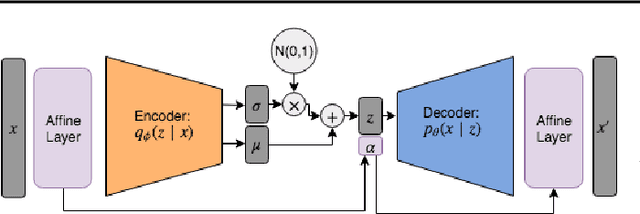
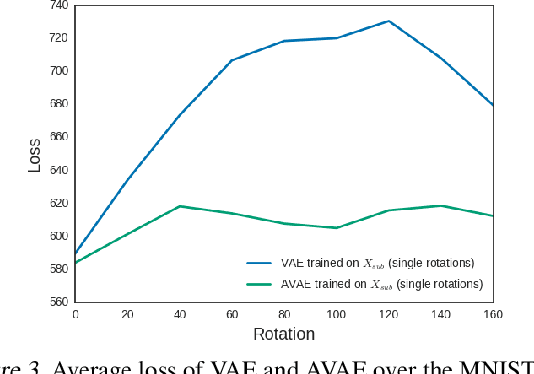
In this study, we propose the Affine Variational Autoencoder (AVAE), a variant of Variational Autoencoder (VAE) designed to improve robustness by overcoming the inability of VAEs to generalize to distributional shifts in the form of affine perturbations. By optimizing an affine transform to maximize ELBO, the proposed AVAE transforms an input to the training distribution without the need to increase model complexity to model the full distribution of affine transforms. In addition, we introduce a training procedure to create an efficient model by learning a subset of the training distribution, and using the AVAE to improve generalization and robustness to distributional shift at test time. Experiments on affine perturbations demonstrate that the proposed AVAE significantly improves generalization and robustness to distributional shift in the form of affine perturbations without an increase in model complexity.
TriResNet: A Deep Triple-stream Residual Network for Histopathology Grading
Jun 22, 2018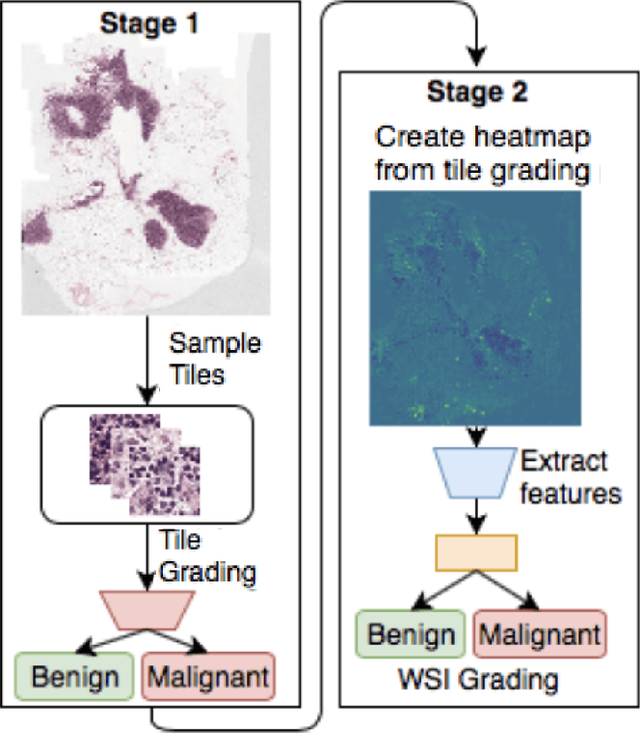
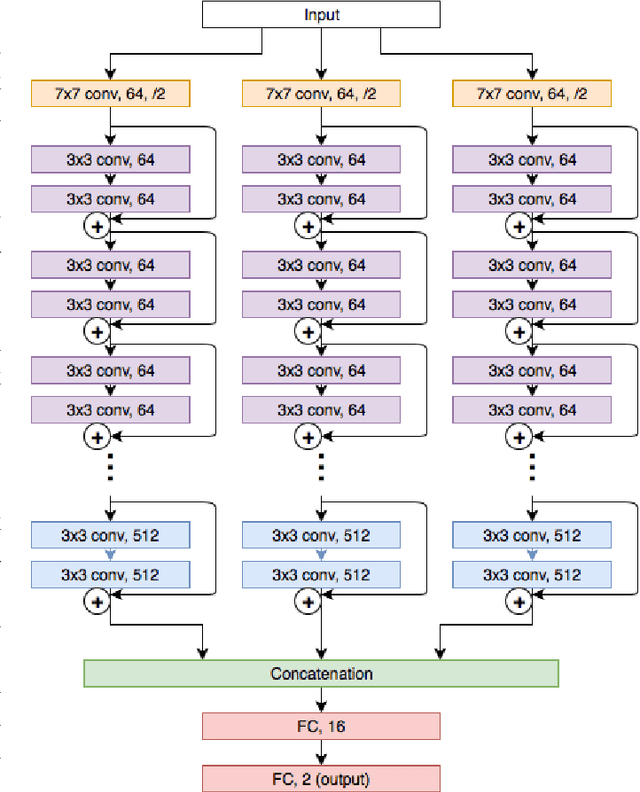
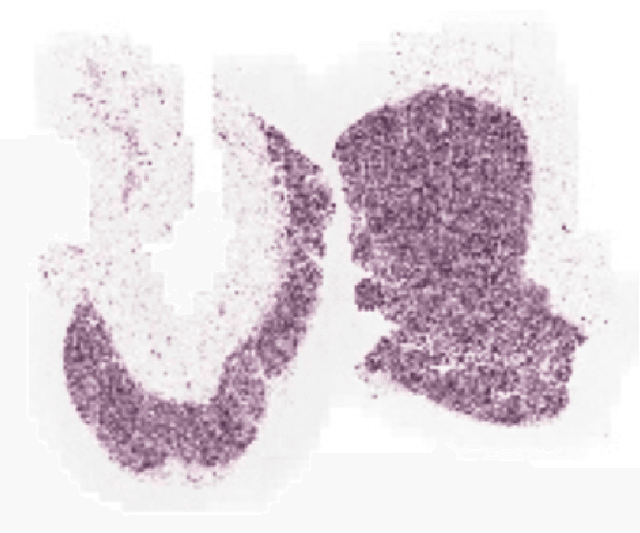
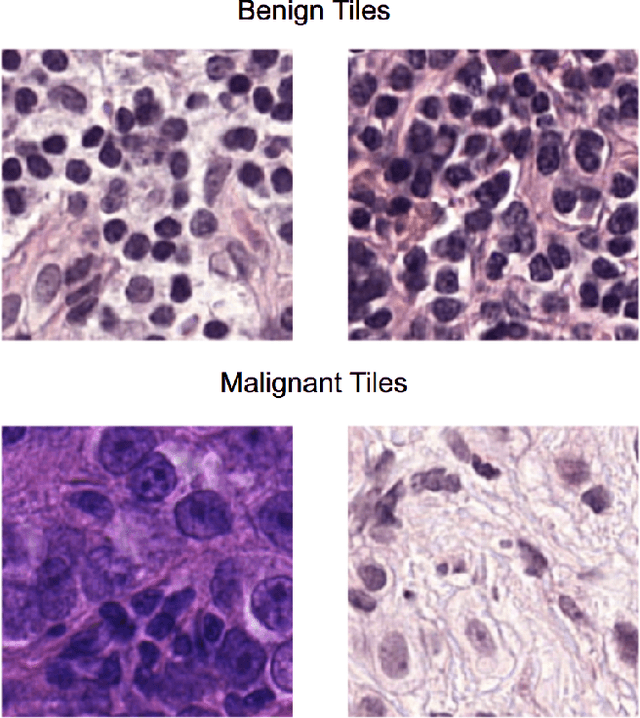
While microscopic analysis of histopathological slides is generally considered as the gold standard method for performing cancer diagnosis and grading, the current method for analysis is extremely time consuming and labour intensive as it requires pathologists to visually inspect tissue samples in a detailed fashion for the presence of cancer. As such, there has been significant recent interest in computer aided diagnosis systems for analysing histopathological slides for cancer grading to aid pathologists to perform cancer diagnosis and grading in a more efficient, accurate, and consistent manner. In this work, we investigate and explore a deep triple-stream residual network (TriResNet) architecture for the purpose of tile-level histopathology grading, which is the critical first step to computer-aided whole-slide histopathology grading. In particular, the design mentality behind the proposed TriResNet network architecture is to facilitate for the learning of a more diverse set of quantitative features to better characterize the complex tissue characteristics found in histopathology samples. Experimental results on two widely-used computer-aided histopathology benchmark datasets (CAMELYON16 dataset and Invasive Ductal Carcinoma (IDC) dataset) demonstrated that the proposed TriResNet network architecture was able to achieve noticeably improved accuracies when compared with two other state-of-the-art deep convolutional neural network architectures. Based on these promising results, the hope is that the proposed TriResNet network architecture could become a useful tool to aiding pathologists increase the consistency, speed, and accuracy of the histopathology grading process.