 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVQI: A Multi-task, Hardware-integrated Artificial Intelligence System for Automated Visual Inspection in Electronics Manufacturing
Dec 14, 2023

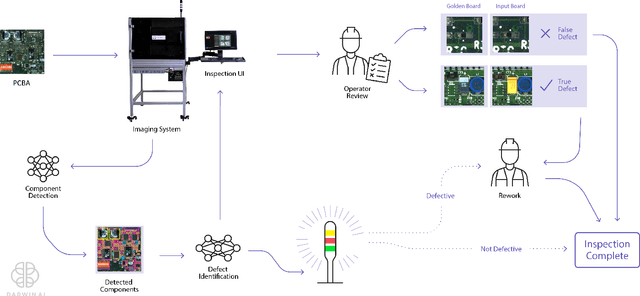
As electronics manufacturers continue to face pressure to increase production efficiency amid difficulties with supply chains and labour shortages, many printed circuit board assembly (PCBA) manufacturers have begun to invest in automation and technological innovations to remain competitive. One such method is to leverage artificial intelligence (AI) to greatly augment existing manufacturing processes. In this paper, we present the DarwinAI Visual Quality Inspection (DVQI) system, a hardware-integration artificial intelligence system for the automated inspection of printed circuit board assembly defects in an electronics manufacturing environment. The DVQI system enables multi-task inspection via minimal programming and setup for manufacturing engineers while improving cycle time relative to manual inspection. We also present a case study of the deployed DVQI system's performance and impact for a top electronics manufacturer.
PCBDet: An Efficient Deep Neural Network Object Detection Architecture for Automatic PCB Component Detection on the Edge
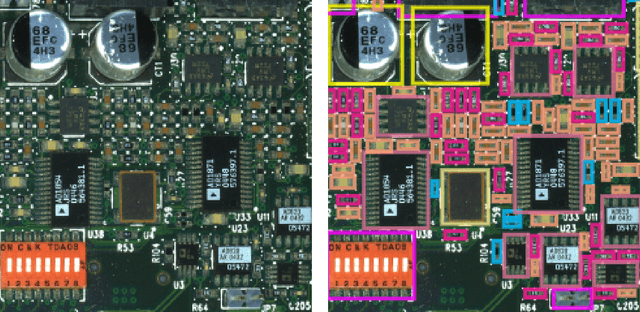
Jan 23, 2023There can be numerous electronic components on a given PCB, making the task of visual inspection to detect defects very time-consuming and prone to error, especially at scale. There has thus been significant interest in automatic PCB component detection, particularly leveraging deep learning. However, deep neural networks typically require high computational resources, possibly limiting their feasibility in real-world use cases in manufacturing, which often involve high-volume and high-throughput detection with constrained edge computing resource availability. As a result of an exploration of efficient deep neural network architectures for this use case, we introduce PCBDet, an attention condenser network design that provides state-of-the-art inference throughput while achieving superior PCB component detection performance compared to other state-of-the-art efficient architecture designs. Experimental results show that PCBDet can achieve up to 2$\times$ inference speed-up on an ARM Cortex A72 processor when compared to an EfficientNet-based design while achieving $\sim$2-4\% higher mAP on the FICS-PCB benchmark dataset.
TinyDefectNet: Highly Compact Deep Neural Network Architecture for High-Throughput Manufacturing Visual Quality Inspection
Nov 29, 2021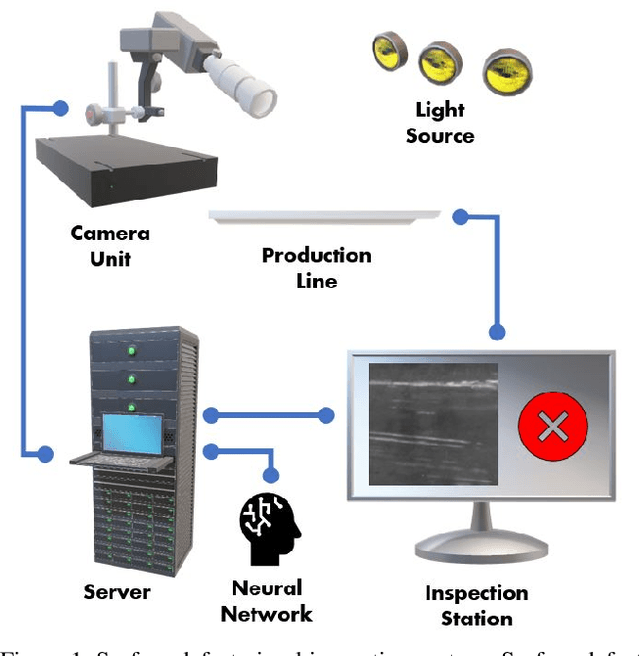
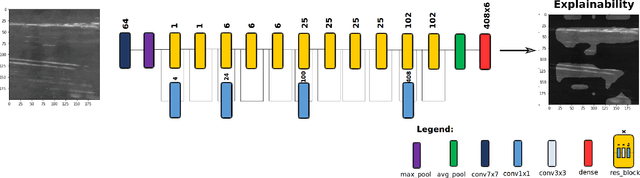

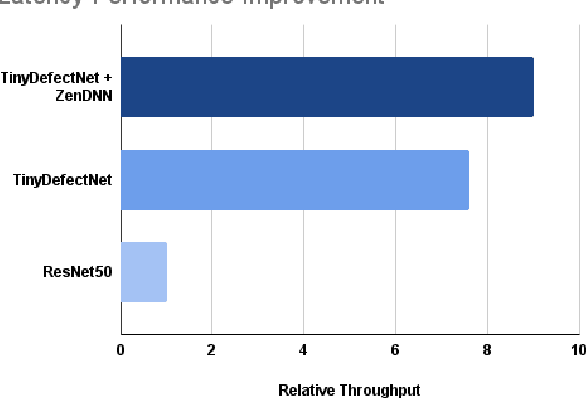
A critical aspect in the manufacturing process is the visual quality inspection of manufactured components for defects and flaws. Human-only visual inspection can be very time-consuming and laborious, and is a significant bottleneck especially for high-throughput manufacturing scenarios. Given significant advances in the field of deep learning, automated visual quality inspection can lead to highly efficient and reliable detection of defects and flaws during the manufacturing process. However, deep learning-driven visual inspection methods often necessitate significant computational resources, thus limiting throughput and act as a bottleneck to widespread adoption for enabling smart factories. In this study, we investigated the utilization of a machine-driven design exploration approach to create TinyDefectNet, a highly compact deep convolutional network architecture tailored for high-throughput manufacturing visual quality inspection. TinyDefectNet comprises of just ~427K parameters and has a computational complexity of ~97M FLOPs, yet achieving a detection accuracy of a state-of-the-art architecture for the task of surface defect detection on the NEU defect benchmark dataset. As such, TinyDefectNet can achieve the same level of detection performance at 52$\times$ lower architectural complexity and 11x lower computational complexity. Furthermore, TinyDefectNet was deployed on an AMD EPYC 7R32, and achieved 7.6x faster throughput using the native Tensorflow environment and 9x faster throughput using AMD ZenDNN accelerator library. Finally, explainability-driven performance validation strategy was conducted to ensure correct decision-making behaviour was exhibited by TinyDefectNet to improve trust in its usage by operators and inspectors.
State of Compact Architecture Search For Deep Neural Networks
Oct 15, 2019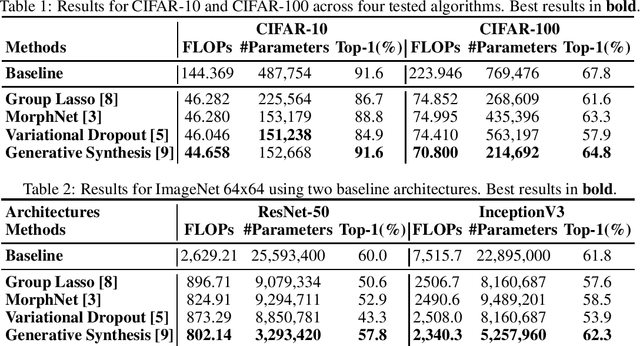
The design of compact deep neural networks is a crucial task to enable widespread adoption of deep neural networks in the real-world, particularly for edge and mobile scenarios. Due to the time-consuming and challenging nature of manually designing compact deep neural networks, there has been significant recent research interest into algorithms that automatically search for compact network architectures. A particularly interesting class of compact architecture search algorithms are those that are guided by baseline network architectures. Such algorithms have been shown to be significantly more computationally efficient than unguided methods. In this study, we explore the current state of compact architecture search for deep neural networks through both theoretical and empirical analysis of four different state-of-the-art compact architecture search algorithms: i) group lasso regularization, ii) variational dropout, iii) MorphNet, and iv) Generative Synthesis. We examine these methods in detail based on a number of different factors such as efficiency, effectiveness, and scalability. Furthermore, empirical evaluations are conducted to compare the efficacy of these compact architecture search algorithms across three well-known benchmark datasets. While by no means an exhaustive exploration, we hope that this study helps provide insights into the interesting state of this relatively new area of research in terms of diversity and real, tangible gains already achieved in architecture design improvements. Furthermore, the hope is that this study would help in pushing the conversation forward towards a deeper theoretical and empirical understanding where the research community currently stands in the landscape of compact architecture search for deep neural networks, and the practical challenges and considerations in leveraging such approaches for operational usage.
YOLO Nano: a Highly Compact You Only Look Once Convolutional Neural Network for Object Detection
Oct 03, 2019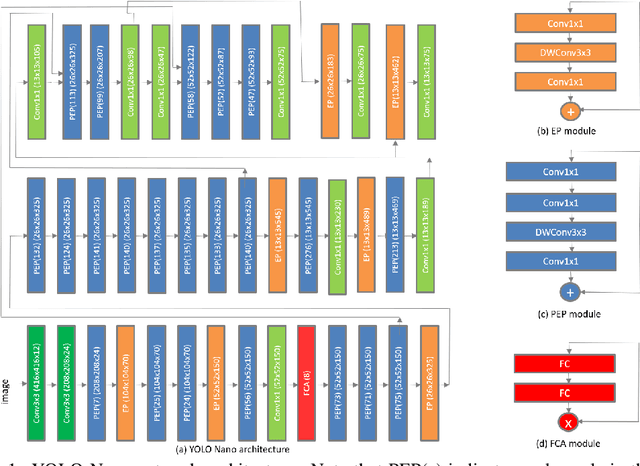
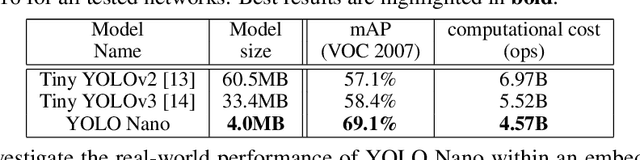
Object detection remains an active area of research in the field of computer vision, and considerable advances and successes has been achieved in this area through the design of deep convolutional neural networks for tackling object detection. Despite these successes, one of the biggest challenges to widespread deployment of such object detection networks on edge and mobile scenarios is the high computational and memory requirements. As such, there has been growing research interest in the design of efficient deep neural network architectures catered for edge and mobile usage. In this study, we introduce YOLO Nano, a highly compact deep convolutional neural network for the task of object detection. A human-machine collaborative design strategy is leveraged to create YOLO Nano, where principled network design prototyping, based on design principles from the YOLO family of single-shot object detection network architectures, is coupled with machine-driven design exploration to create a compact network with highly customized module-level macroarchitecture and microarchitecture designs tailored for the task of embedded object detection. The proposed YOLO Nano possesses a model size of ~4.0MB (>15.1x and >8.3x smaller than Tiny YOLOv2 and Tiny YOLOv3, respectively) and requires 4.57B operations for inference (>34% and ~17% lower than Tiny YOLOv2 and Tiny YOLOv3, respectively) while still achieving an mAP of ~69.1% on the VOC 2007 dataset (~12% and ~10.7% higher than Tiny YOLOv2 and Tiny YOLOv3, respectively). Experiments on inference speed and power efficiency on a Jetson AGX Xavier embedded module at different power budgets further demonstrate the efficacy of YOLO Nano for embedded scenarios.
Human-Machine Collaborative Design for Accelerated Design of Compact Deep Neural Networks for Autonomous Driving
Sep 12, 2019



An effective deep learning development process is critical for widespread industrial adoption, particularly in the automotive sector. A typical industrial deep learning development cycle involves customizing and re-designing an off-the-shelf network architecture to meet the operational requirements of the target application, leading to considerable trial and error work by a machine learning practitioner. This approach greatly impedes development with a long turnaround time and the unsatisfactory quality of the created models. As a result, a development platform that can aid engineers in greatly accelerating the design and production of compact, optimized deep neural networks is highly desirable. In this joint industrial case study, we study the efficacy of the GenSynth AI-assisted AI design platform for accelerating the design of custom, optimized deep neural networks for autonomous driving through human-machine collaborative design. We perform a quantitative examination by evaluating 10 different compact deep neural networks produced by GenSynth for the purpose of object detection via a NASNet-based user network prototype design, targeted at a low-cost GPU-based accelerated embedded system. Furthermore, we quantitatively assess the talent hours and GPU processing hours used by the GenSynth process and three other approaches based on the typical industrial development process. In addition, we quantify the annual cloud cost savings for comprehensive testing using networks produced by GenSynth. Finally, we assess the usability and merits of the GenSynth process through user feedback. The findings of this case study showed that GenSynth is easy to use and can be effective at accelerating the design and production of compact, customized deep neural network.
FermiNets: Learning generative machines to generate efficient neural networks via generative synthesis
Sep 17, 2018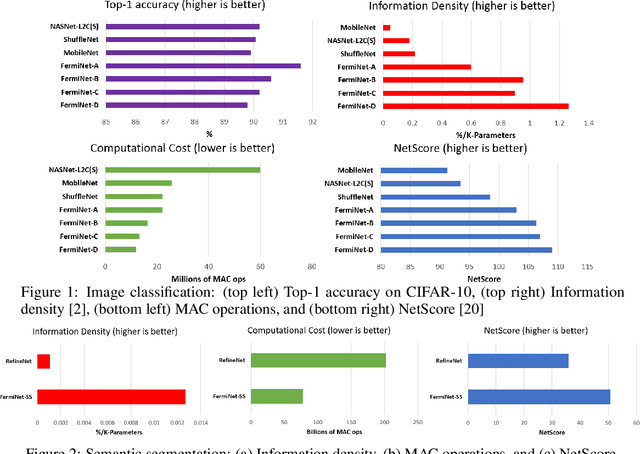

The tremendous potential exhibited by deep learning is often offset by architectural and computational complexity, making widespread deployment a challenge for edge scenarios such as mobile and other consumer devices. To tackle this challenge, we explore the following idea: Can we learn generative machines to automatically generate deep neural networks with efficient network architectures? In this study, we introduce the idea of generative synthesis, which is premised on the intricate interplay between a generator-inquisitor pair that work in tandem to garner insights and learn to generate highly efficient deep neural networks that best satisfies operational requirements. What is most interesting is that, once a generator has been learned through generative synthesis, it can be used to generate not just one but a large variety of different, unique highly efficient deep neural networks that satisfy operational requirements. Experimental results for image classification, semantic segmentation, and object detection tasks illustrate the efficacy of generative synthesis in producing generators that automatically generate highly efficient deep neural networks (which we nickname FermiNets) with higher model efficiency and lower computational costs (reaching >10x more efficient and fewer multiply-accumulate operations than several tested state-of-the-art networks), as well as higher energy efficiency (reaching >4x improvements in image inferences per joule consumed on a Nvidia Tegra X2 mobile processor). As such, generative synthesis can be a powerful, generalized approach for accelerating and improving the building of deep neural networks for on-device edge scenarios.
Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection
Feb 19, 2018
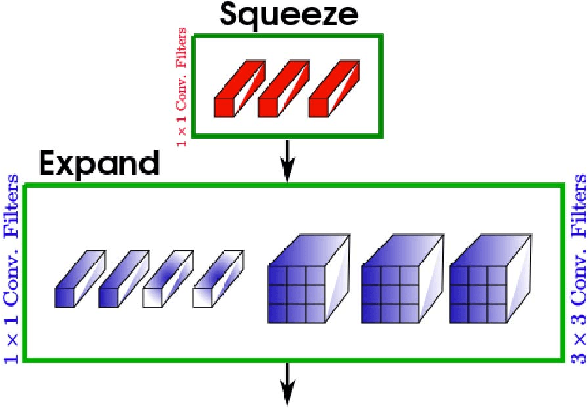
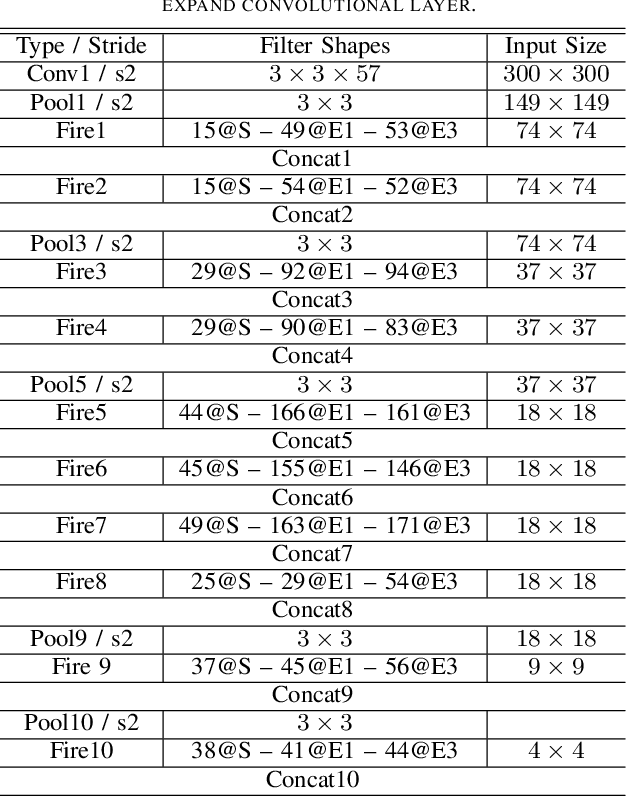

Object detection is a major challenge in computer vision, involving both object classification and object localization within a scene. While deep neural networks have been shown in recent years to yield very powerful techniques for tackling the challenge of object detection, one of the biggest challenges with enabling such object detection networks for widespread deployment on embedded devices is high computational and memory requirements. Recently, there has been an increasing focus in exploring small deep neural network architectures for object detection that are more suitable for embedded devices, such as Tiny YOLO and SqueezeDet. Inspired by the efficiency of the Fire microarchitecture introduced in SqueezeNet and the object detection performance of the single-shot detection macroarchitecture introduced in SSD, this paper introduces Tiny SSD, a single-shot detection deep convolutional neural network for real-time embedded object detection that is composed of a highly optimized, non-uniform Fire sub-network stack and a non-uniform sub-network stack of highly optimized SSD-based auxiliary convolutional feature layers designed specifically to minimize model size while maintaining object detection performance. The resulting Tiny SSD possess a model size of 2.3MB (~26X smaller than Tiny YOLO) while still achieving an mAP of 61.3% on VOC 2007 (~4.2% higher than Tiny YOLO). These experimental results show that very small deep neural network architectures can be designed for real-time object detection that are well-suited for embedded scenarios.
StressedNets: Efficient Feature Representations via Stress-induced Evolutionary Synthesis of Deep Neural Networks
Jan 16, 2018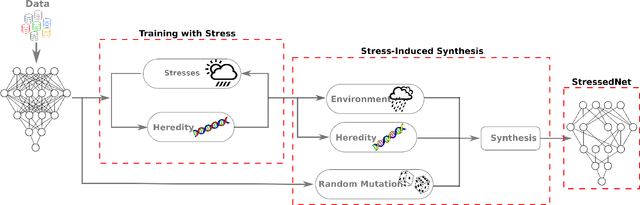
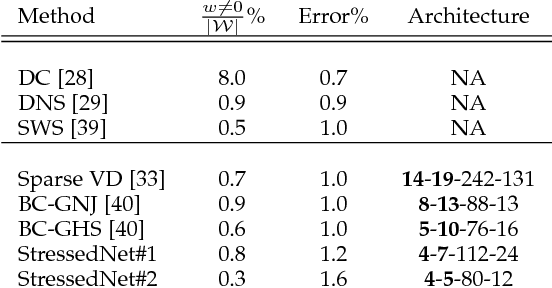

The computational complexity of leveraging deep neural networks for extracting deep feature representations is a significant barrier to its widespread adoption, particularly for use in embedded devices. One particularly promising strategy to addressing the complexity issue is the notion of evolutionary synthesis of deep neural networks, which was demonstrated to successfully produce highly efficient deep neural networks while retaining modeling performance. Here, we further extend upon the evolutionary synthesis strategy for achieving efficient feature extraction via the introduction of a stress-induced evolutionary synthesis framework, where stress signals are imposed upon the synapses of a deep neural network during training to induce stress and steer the synthesis process towards the production of more efficient deep neural networks over successive generations and improved model fidelity at a greater efficiency. The proposed stress-induced evolutionary synthesis approach is evaluated on a variety of different deep neural network architectures (LeNet5, AlexNet, and YOLOv2) on different tasks (object classification and object detection) to synthesize efficient StressedNets over multiple generations. Experimental results demonstrate the efficacy of the proposed framework to synthesize StressedNets with significant improvement in network architecture efficiency (e.g., 40x for AlexNet and 33x for YOLOv2) and speed improvements (e.g., 5.5x inference speed-up for YOLOv2 on an Nvidia Tegra X1 mobile processor).
SquishedNets: Squishing SqueezeNet further for edge device scenarios via deep evolutionary synthesis
Nov 20, 2017
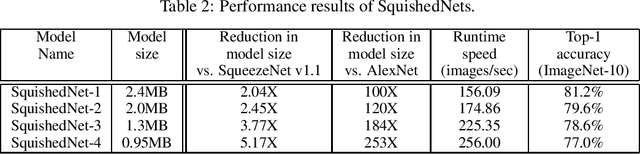
While deep neural networks have been shown in recent years to outperform other machine learning methods in a wide range of applications, one of the biggest challenges with enabling deep neural networks for widespread deployment on edge devices such as mobile and other consumer devices is high computational and memory requirements. Recently, there has been greater exploration into small deep neural network architectures that are more suitable for edge devices, with one of the most popular architectures being SqueezeNet, with an incredibly small model size of 4.8MB. Taking further advantage of the notion that many applications of machine learning on edge devices are often characterized by a low number of target classes, this study explores the utility of combining architectural modifications and an evolutionary synthesis strategy for synthesizing even smaller deep neural architectures based on the more recent SqueezeNet v1.1 macroarchitecture for applications with fewer target classes. In particular, architectural modifications are first made to SqueezeNet v1.1 to accommodate for a 10-class ImageNet-10 dataset, and then an evolutionary synthesis strategy is leveraged to synthesize more efficient deep neural networks based on this modified macroarchitecture. The resulting SquishedNets possess model sizes ranging from 2.4MB to 0.95MB (~5.17X smaller than SqueezeNet v1.1, or 253X smaller than AlexNet). Furthermore, the SquishedNets are still able to achieve accuracies ranging from 81.2% to 77%, and able to process at speeds of 156 images/sec to as much as 256 images/sec on a Nvidia Jetson TX1 embedded chip. These preliminary results show that a combination of architectural modifications and an evolutionary synthesis strategy can be a useful tool for producing very small deep neural network architectures that are well-suited for edge device scenarios.