 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning based Reset Policy for CDCL SAT Solvers
Apr 04, 2024



Restart policy is an important technique used in modern Conflict-Driven Clause Learning (CDCL) solvers, wherein some parts of the solver state are erased at certain intervals during the run of the solver. In most solvers, variable activities are preserved across restart boundaries, resulting in solvers continuing to search parts of the assignment tree that are not far from the one immediately prior to a restart. To enable the solver to search possibly "distant" parts of the assignment tree, we study the effect of resets, a variant of restarts which not only erases the assignment trail, but also randomizes the activity scores of the variables of the input formula after reset, thus potentially enabling a better global exploration of the search space. In this paper, we model the problem of whether to trigger reset as a multi-armed bandit (MAB) problem, and propose two reinforcement learning (RL) based adaptive reset policies using the Upper Confidence Bound (UCB) and Thompson sampling algorithms. These two algorithms balance the exploration-exploitation tradeoff by adaptively choosing arms (reset vs. no reset) based on their estimated rewards during the solver's run. We implement our reset policies in four baseline SOTA CDCL solvers and compare the baselines against the reset versions on Satcoin benchmarks and SAT Competition instances. Our results show that RL-based reset versions outperform the corresponding baseline solvers on both Satcoin and the SAT competition instances, suggesting that our RL policy helps to dynamically and profitably adapt the reset frequency for any given input instance. We also introduce the concept of a partial reset, where at least a constant number of variable activities are retained across reset boundaries. Building on previous results, we show that there is an exponential separation between O(1) vs. $\Omega(n)$-length partial resets.
Battlesnake Challenge: A Multi-agent Reinforcement Learning Playground with Human-in-the-loop
Jul 20, 2020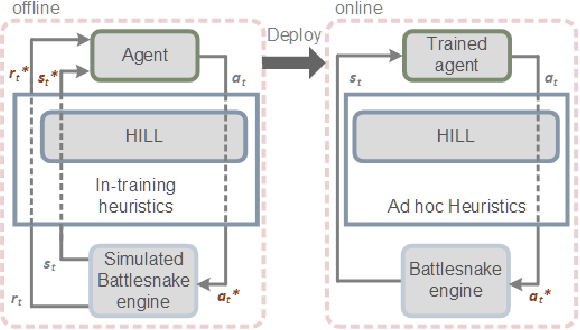
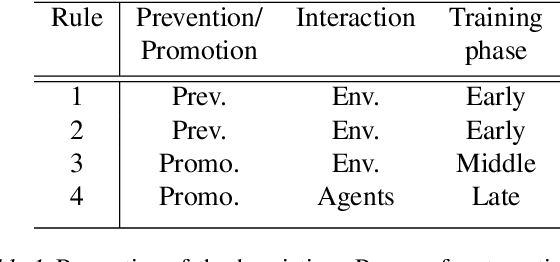
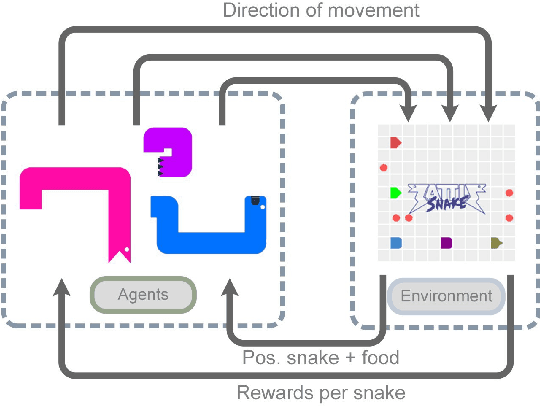
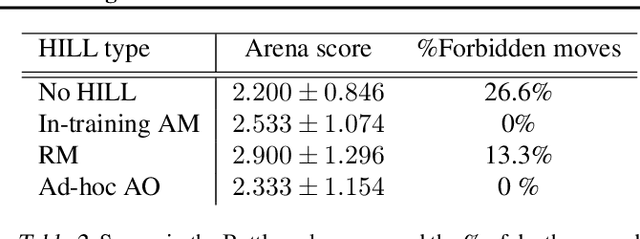
We present the Battlesnake Challenge, a framework for multi-agent reinforcement learning with Human-In-the-Loop Learning (HILL). It is developed upon Battlesnake, a multiplayer extension of the traditional Snake game in which 2 or more snakes compete for the final survival. The Battlesnake Challenge consists of an offline module for model training and an online module for live competitions. We develop a simulated game environment for the offline multi-agent model training and identify a set of baseline heuristics that can be instilled to improve learning. Our framework is agent-agnostic and heuristics-agnostic such that researchers can design their own algorithms, train their models, and demonstrate in the online Battlesnake competition. We validate the framework and baseline heuristics with our preliminary experiments. Our results show that agents with the proposed HILL methods consistently outperform agents without HILL. Besides, heuristics of reward manipulation had the best performance in the online competition. We open source our framework at https://github.com/awslabs/sagemaker-battlesnake-ai.
YOLO Nano: a Highly Compact You Only Look Once Convolutional Neural Network for Object Detection
Oct 03, 2019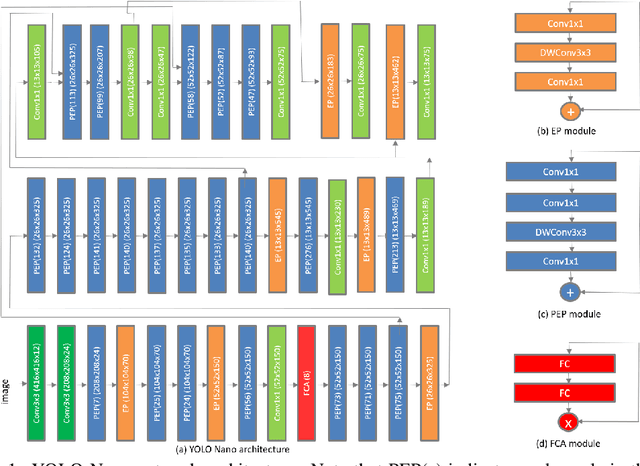
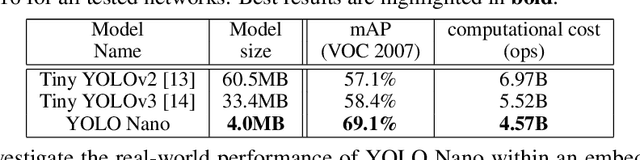
Object detection remains an active area of research in the field of computer vision, and considerable advances and successes has been achieved in this area through the design of deep convolutional neural networks for tackling object detection. Despite these successes, one of the biggest challenges to widespread deployment of such object detection networks on edge and mobile scenarios is the high computational and memory requirements. As such, there has been growing research interest in the design of efficient deep neural network architectures catered for edge and mobile usage. In this study, we introduce YOLO Nano, a highly compact deep convolutional neural network for the task of object detection. A human-machine collaborative design strategy is leveraged to create YOLO Nano, where principled network design prototyping, based on design principles from the YOLO family of single-shot object detection network architectures, is coupled with machine-driven design exploration to create a compact network with highly customized module-level macroarchitecture and microarchitecture designs tailored for the task of embedded object detection. The proposed YOLO Nano possesses a model size of ~4.0MB (>15.1x and >8.3x smaller than Tiny YOLOv2 and Tiny YOLOv3, respectively) and requires 4.57B operations for inference (>34% and ~17% lower than Tiny YOLOv2 and Tiny YOLOv3, respectively) while still achieving an mAP of ~69.1% on the VOC 2007 dataset (~12% and ~10.7% higher than Tiny YOLOv2 and Tiny YOLOv3, respectively). Experiments on inference speed and power efficiency on a Jetson AGX Xavier embedded module at different power budgets further demonstrate the efficacy of YOLO Nano for embedded scenarios.
A Computationally Efficient Pipeline Approach to Full Page Offline Handwritten Text Recognition
Oct 01, 2019
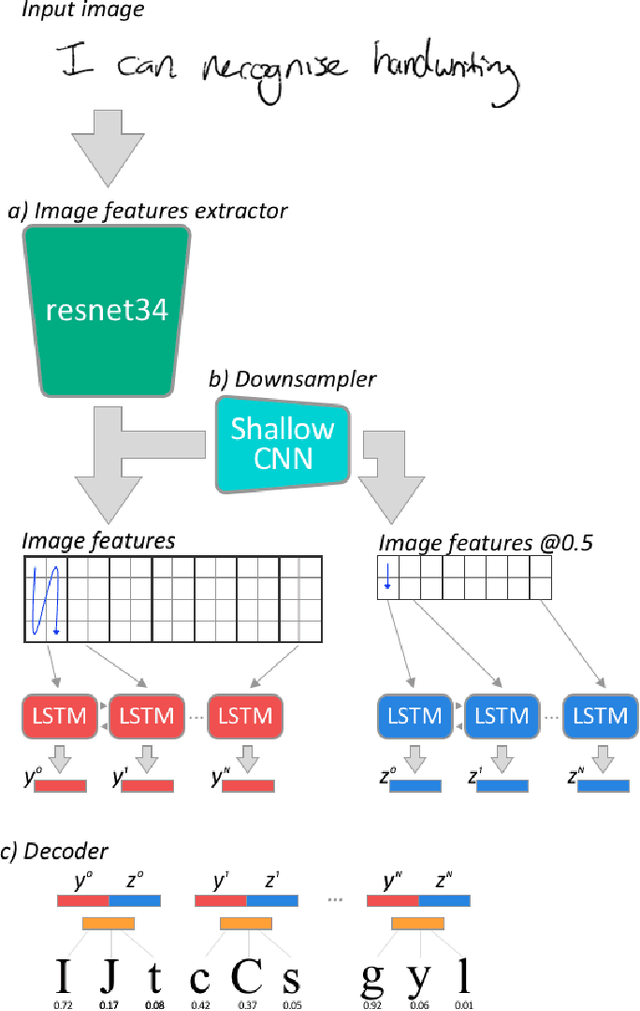

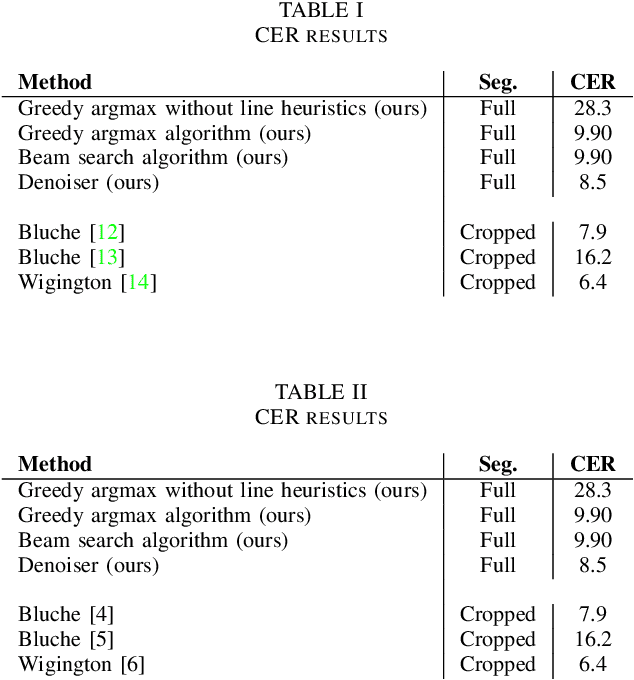
Offline handwriting recognition with deep neural networks is usually limited to words or lines due to large computational costs. In this paper, a less computationally expensive full page offline handwritten text recognition framework is introduced. This framework includes a pipeline that locates handwritten text with an object detection neural network and recognises the text within the detected regions using features extracted with a multi-scale convolutional neural network (CNN) fed into a bidirectional long short term memory (LSTM) network. This framework achieves comparable error rates to state of the art frameworks while using less memory and time. The results in this paper demonstrate the potential of this framework and future work can investigate production ready and deployable handwritten text recognisers.