 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO Nano: a Highly Compact You Only Look Once Convolutional Neural Network for Object Detection
Oct 03, 2019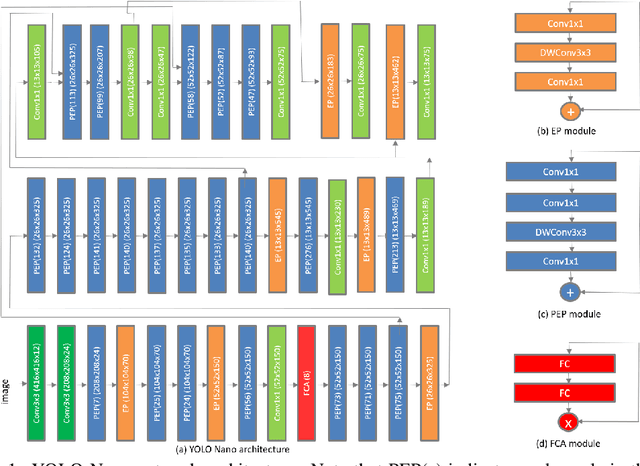
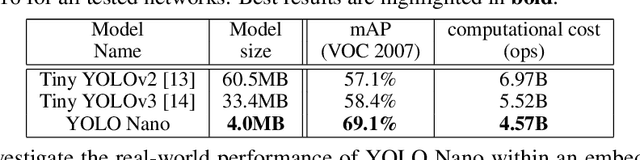
Object detection remains an active area of research in the field of computer vision, and considerable advances and successes has been achieved in this area through the design of deep convolutional neural networks for tackling object detection. Despite these successes, one of the biggest challenges to widespread deployment of such object detection networks on edge and mobile scenarios is the high computational and memory requirements. As such, there has been growing research interest in the design of efficient deep neural network architectures catered for edge and mobile usage. In this study, we introduce YOLO Nano, a highly compact deep convolutional neural network for the task of object detection. A human-machine collaborative design strategy is leveraged to create YOLO Nano, where principled network design prototyping, based on design principles from the YOLO family of single-shot object detection network architectures, is coupled with machine-driven design exploration to create a compact network with highly customized module-level macroarchitecture and microarchitecture designs tailored for the task of embedded object detection. The proposed YOLO Nano possesses a model size of ~4.0MB (>15.1x and >8.3x smaller than Tiny YOLOv2 and Tiny YOLOv3, respectively) and requires 4.57B operations for inference (>34% and ~17% lower than Tiny YOLOv2 and Tiny YOLOv3, respectively) while still achieving an mAP of ~69.1% on the VOC 2007 dataset (~12% and ~10.7% higher than Tiny YOLOv2 and Tiny YOLOv3, respectively). Experiments on inference speed and power efficiency on a Jetson AGX Xavier embedded module at different power budgets further demonstrate the efficacy of YOLO Nano for embedded scenarios.
EdgeSegNet: A Compact Network for Semantic Segmentation
May 10, 2019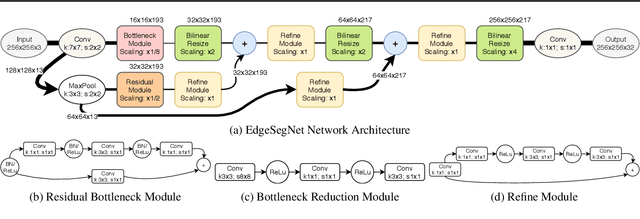

In this study, we introduce EdgeSegNet, a compact deep convolutional neural network for the task of semantic segmentation. A human-machine collaborative design strategy is leveraged to create EdgeSegNet, where principled network design prototyping is coupled with machine-driven design exploration to create networks with customized module-level macroarchitecture and microarchitecture designs tailored for the task. Experimental results showed that EdgeSegNet can achieve semantic segmentation accuracy comparable with much larger and computationally complex networks (>20x} smaller model size than RefineNet) as well as achieving an inference speed of ~38.5 FPS on an NVidia Jetson AGX Xavier. As such, the proposed EdgeSegNet is well-suited for low-power edge scenarios.
AttoNets: Compact and Efficient Deep Neural Networks for the Edge via Human-Machine Collaborative Design
Apr 15, 2019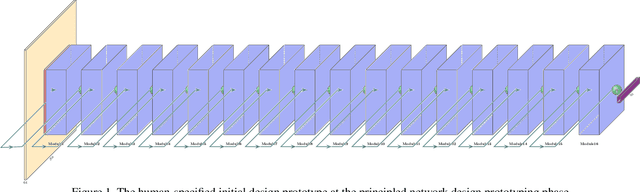
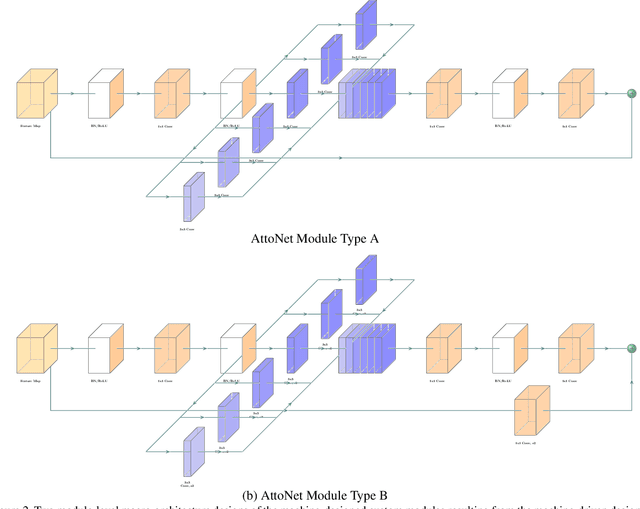
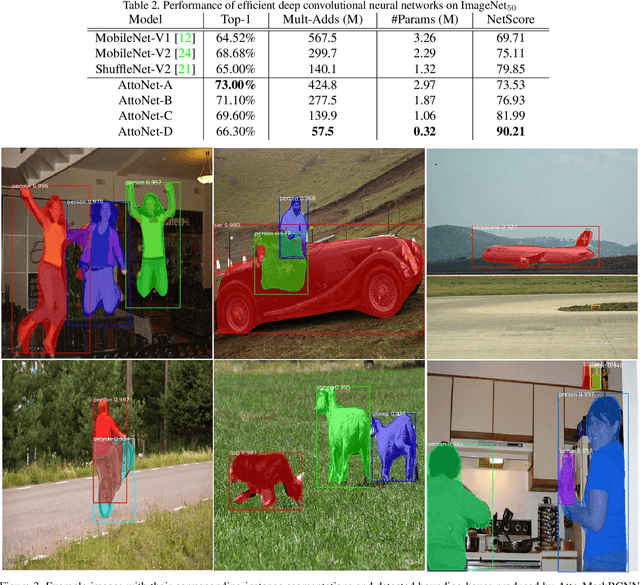
While deep neural networks have achieved state-of-the-art performance across a large number of complex tasks, it remains a big challenge to deploy such networks for practical, on-device edge scenarios such as on mobile devices, consumer devices, drones, and vehicles. In this study, we take a deeper exploration into a human-machine collaborative design approach for creating highly efficient deep neural networks through a synergy between principled network design prototyping and machine-driven design exploration. The efficacy of human-machine collaborative design is demonstrated through the creation of AttoNets, a family of highly efficient deep neural networks for on-device edge deep learning. Each AttoNet possesses a human-specified network-level macro-architecture comprising of custom modules with unique machine-designed module-level macro-architecture and micro-architecture designs, all driven by human-specified design requirements. Experimental results for the task of object recognition showed that the AttoNets created via human-machine collaborative design has significantly fewer parameters and computational costs than state-of-the-art networks designed for efficiency while achieving noticeably higher accuracy (with the smallest AttoNet achieving ~1.8% higher accuracy while requiring ~10x fewer multiply-add operations and parameters than MobileNet-V1). Furthermore, the efficacy of the AttoNets is demonstrated for the task of instance-level object segmentation and object detection, where an AttoNet-based Mask R-CNN network was constructed with significantly fewer parameters and computational costs (~5x fewer multiply-add operations and ~2x fewer parameters) than a ResNet-50 based Mask R-CNN network.
FermiNets: Learning generative machines to generate efficient neural networks via generative synthesis
Sep 17, 2018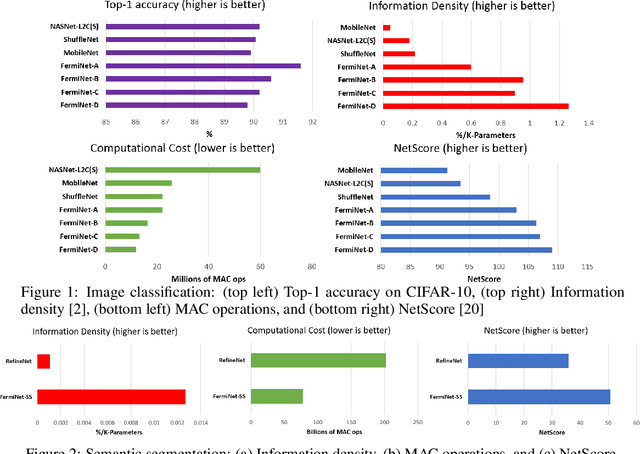

The tremendous potential exhibited by deep learning is often offset by architectural and computational complexity, making widespread deployment a challenge for edge scenarios such as mobile and other consumer devices. To tackle this challenge, we explore the following idea: Can we learn generative machines to automatically generate deep neural networks with efficient network architectures? In this study, we introduce the idea of generative synthesis, which is premised on the intricate interplay between a generator-inquisitor pair that work in tandem to garner insights and learn to generate highly efficient deep neural networks that best satisfies operational requirements. What is most interesting is that, once a generator has been learned through generative synthesis, it can be used to generate not just one but a large variety of different, unique highly efficient deep neural networks that satisfy operational requirements. Experimental results for image classification, semantic segmentation, and object detection tasks illustrate the efficacy of generative synthesis in producing generators that automatically generate highly efficient deep neural networks (which we nickname FermiNets) with higher model efficiency and lower computational costs (reaching >10x more efficient and fewer multiply-accumulate operations than several tested state-of-the-art networks), as well as higher energy efficiency (reaching >4x improvements in image inferences per joule consumed on a Nvidia Tegra X2 mobile processor). As such, generative synthesis can be a powerful, generalized approach for accelerating and improving the building of deep neural networks for on-device edge scenarios.
Tiny SSD: A Tiny Single-shot Detection Deep Convolutional Neural Network for Real-time Embedded Object Detection
Feb 19, 2018
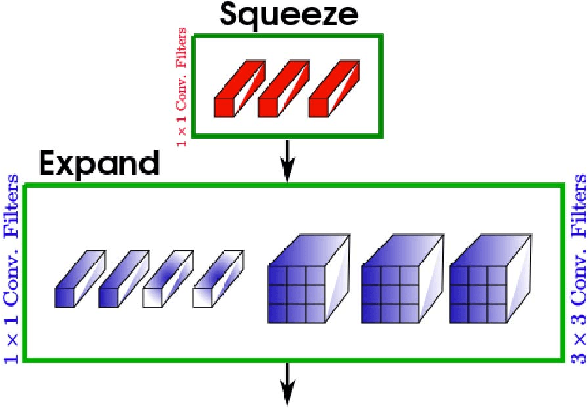
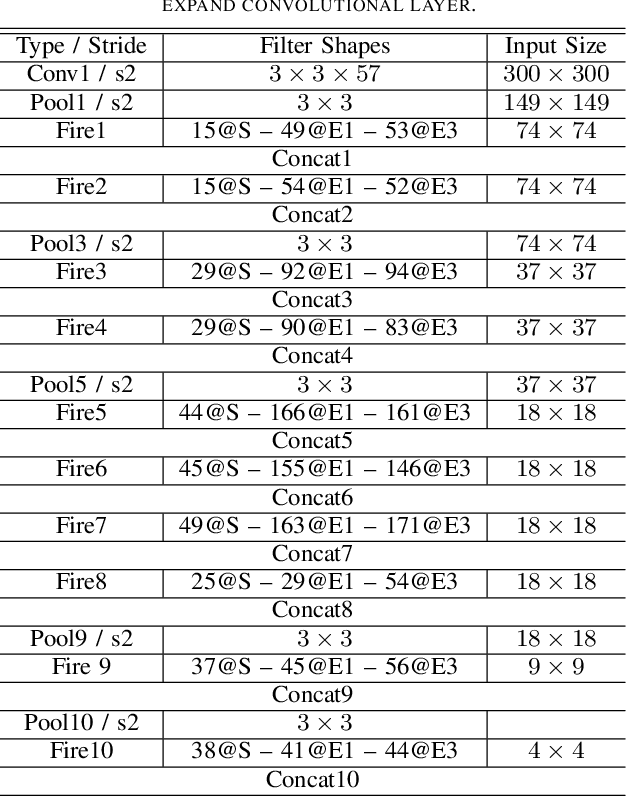

Object detection is a major challenge in computer vision, involving both object classification and object localization within a scene. While deep neural networks have been shown in recent years to yield very powerful techniques for tackling the challenge of object detection, one of the biggest challenges with enabling such object detection networks for widespread deployment on embedded devices is high computational and memory requirements. Recently, there has been an increasing focus in exploring small deep neural network architectures for object detection that are more suitable for embedded devices, such as Tiny YOLO and SqueezeDet. Inspired by the efficiency of the Fire microarchitecture introduced in SqueezeNet and the object detection performance of the single-shot detection macroarchitecture introduced in SSD, this paper introduces Tiny SSD, a single-shot detection deep convolutional neural network for real-time embedded object detection that is composed of a highly optimized, non-uniform Fire sub-network stack and a non-uniform sub-network stack of highly optimized SSD-based auxiliary convolutional feature layers designed specifically to minimize model size while maintaining object detection performance. The resulting Tiny SSD possess a model size of 2.3MB (~26X smaller than Tiny YOLO) while still achieving an mAP of 61.3% on VOC 2007 (~4.2% higher than Tiny YOLO). These experimental results show that very small deep neural network architectures can be designed for real-time object detection that are well-suited for embedded scenarios.
StressedNets: Efficient Feature Representations via Stress-induced Evolutionary Synthesis of Deep Neural Networks
Jan 16, 2018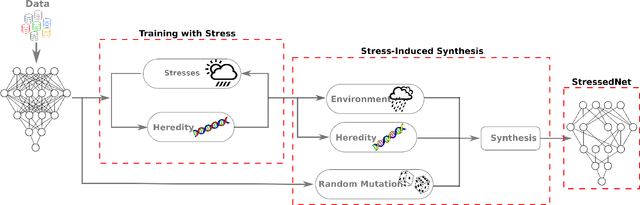
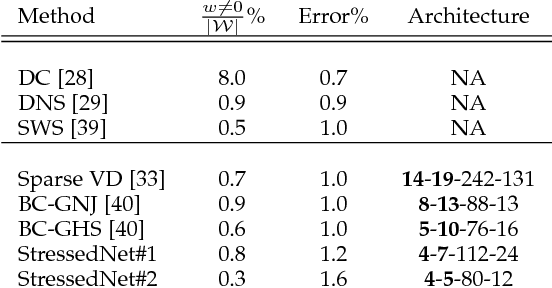
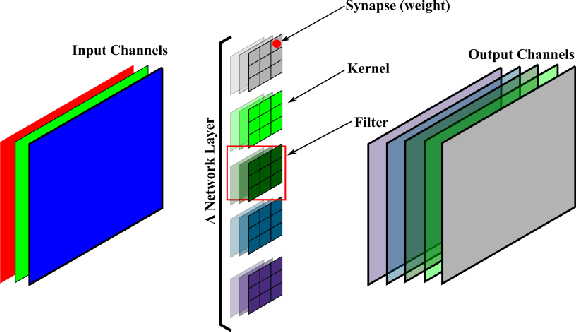

The computational complexity of leveraging deep neural networks for extracting deep feature representations is a significant barrier to its widespread adoption, particularly for use in embedded devices. One particularly promising strategy to addressing the complexity issue is the notion of evolutionary synthesis of deep neural networks, which was demonstrated to successfully produce highly efficient deep neural networks while retaining modeling performance. Here, we further extend upon the evolutionary synthesis strategy for achieving efficient feature extraction via the introduction of a stress-induced evolutionary synthesis framework, where stress signals are imposed upon the synapses of a deep neural network during training to induce stress and steer the synthesis process towards the production of more efficient deep neural networks over successive generations and improved model fidelity at a greater efficiency. The proposed stress-induced evolutionary synthesis approach is evaluated on a variety of different deep neural network architectures (LeNet5, AlexNet, and YOLOv2) on different tasks (object classification and object detection) to synthesize efficient StressedNets over multiple generations. Experimental results demonstrate the efficacy of the proposed framework to synthesize StressedNets with significant improvement in network architecture efficiency (e.g., 40x for AlexNet and 33x for YOLOv2) and speed improvements (e.g., 5.5x inference speed-up for YOLOv2 on an Nvidia Tegra X1 mobile processor).
SquishedNets: Squishing SqueezeNet further for edge device scenarios via deep evolutionary synthesis
Nov 20, 2017
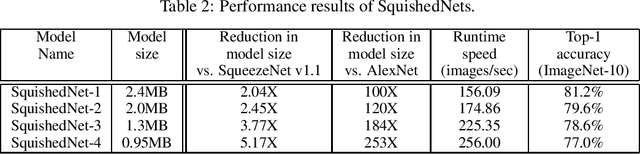
While deep neural networks have been shown in recent years to outperform other machine learning methods in a wide range of applications, one of the biggest challenges with enabling deep neural networks for widespread deployment on edge devices such as mobile and other consumer devices is high computational and memory requirements. Recently, there has been greater exploration into small deep neural network architectures that are more suitable for edge devices, with one of the most popular architectures being SqueezeNet, with an incredibly small model size of 4.8MB. Taking further advantage of the notion that many applications of machine learning on edge devices are often characterized by a low number of target classes, this study explores the utility of combining architectural modifications and an evolutionary synthesis strategy for synthesizing even smaller deep neural architectures based on the more recent SqueezeNet v1.1 macroarchitecture for applications with fewer target classes. In particular, architectural modifications are first made to SqueezeNet v1.1 to accommodate for a 10-class ImageNet-10 dataset, and then an evolutionary synthesis strategy is leveraged to synthesize more efficient deep neural networks based on this modified macroarchitecture. The resulting SquishedNets possess model sizes ranging from 2.4MB to 0.95MB (~5.17X smaller than SqueezeNet v1.1, or 253X smaller than AlexNet). Furthermore, the SquishedNets are still able to achieve accuracies ranging from 81.2% to 77%, and able to process at speeds of 156 images/sec to as much as 256 images/sec on a Nvidia Jetson TX1 embedded chip. These preliminary results show that a combination of architectural modifications and an evolutionary synthesis strategy can be a useful tool for producing very small deep neural network architectures that are well-suited for edge device scenarios.