 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Error: a New Performance Measure for Adversarial Robustness
Jun 18, 2021


Despite the significant advances in deep learning over the past decade, a major challenge that limits the wide-spread adoption of deep learning has been their fragility to adversarial attacks. This sensitivity to making erroneous predictions in the presence of adversarially perturbed data makes deep neural networks difficult to adopt for certain real-world, mission-critical applications. While much of the research focus has revolved around adversarial example creation and adversarial hardening, the area of performance measures for assessing adversarial robustness is not well explored. Motivated by this, this study presents the concept of residual error, a new performance measure for not only assessing the adversarial robustness of a deep neural network at the individual sample level, but also can be used to differentiate between adversarial and non-adversarial examples to facilitate for adversarial example detection. Furthermore, we introduce a hybrid model for approximating the residual error in a tractable manner. Experimental results using the case of image classification demonstrates the effectiveness and efficacy of the proposed residual error metric for assessing several well-known deep neural network architectures. These results thus illustrate that the proposed measure could be a useful tool for not only assessing the robustness of deep neural networks used in mission-critical scenarios, but also in the design of adversarially robust models.
Vulnerability Under Adversarial Machine Learning: Bias or Variance?
Aug 01, 2020
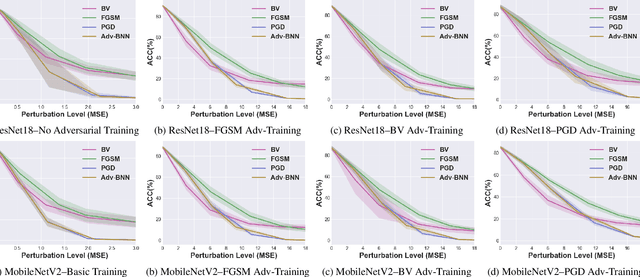
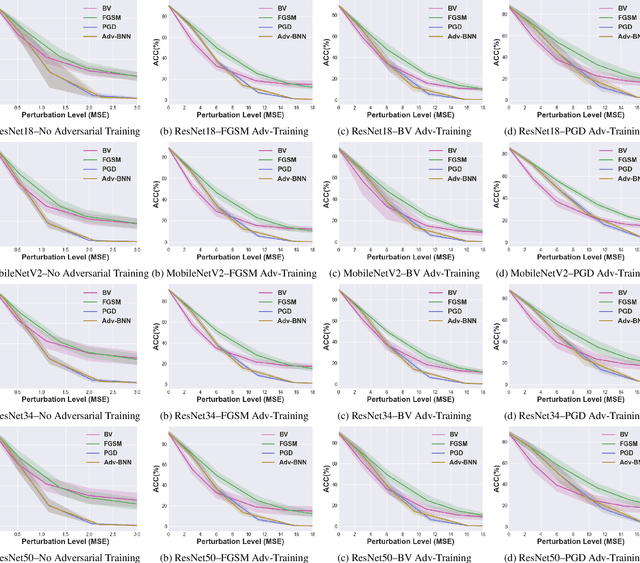

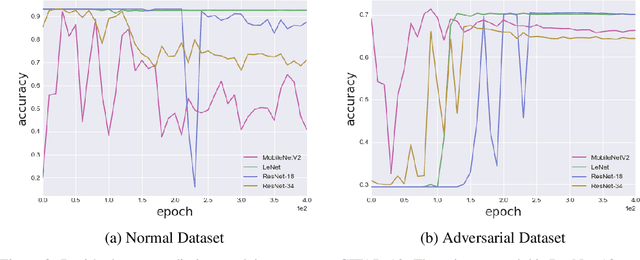
Prior studies have unveiled the vulnerability of the deep neural networks in the context of adversarial machine learning, leading to great recent attention into this area. One interesting question that has yet to be fully explored is the bias-variance relationship of adversarial machine learning, which can potentially provide deeper insights into this behaviour. The notion of bias and variance is one of the main approaches to analyze and evaluate the generalization and reliability of a machine learning model. Although it has been extensively used in other machine learning models, it is not well explored in the field of deep learning and it is even less explored in the area of adversarial machine learning. In this study, we investigate the effect of adversarial machine learning on the bias and variance of a trained deep neural network and analyze how adversarial perturbations can affect the generalization of a network. We derive the bias-variance trade-off for both classification and regression applications based on two main loss functions: (i) mean squared error (MSE), and (ii) cross-entropy. Furthermore, we perform quantitative analysis with both simulated and real data to empirically evaluate consistency with the derived bias-variance tradeoffs. Our analysis sheds light on why the deep neural networks have poor performance under adversarial perturbation from a bias-variance point of view and how this type of perturbation would change the performance of a network. Moreover, given these new theoretical findings, we introduce a new adversarial machine learning algorithm with lower computational complexity than well-known adversarial machine learning strategies (e.g., PGD) while providing a high success rate in fooling deep neural networks in lower perturbation magnitudes.
Learn2Perturb: an End-to-end Feature Perturbation Learning to Improve Adversarial Robustness
Mar 03, 2020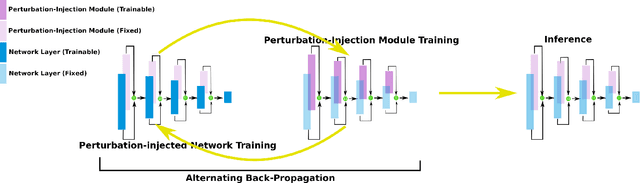


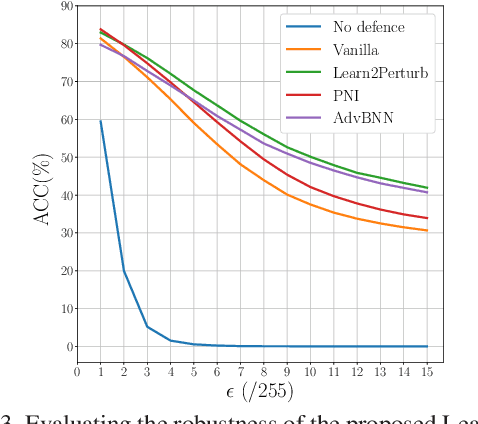
While deep neural networks have been achieving state-of-the-art performance across a wide variety of applications, their vulnerability to adversarial attacks limits their widespread deployment for safety-critical applications. Alongside other adversarial defense approaches being investigated, there has been a very recent interest in improving adversarial robustness in deep neural networks through the introduction of perturbations during the training process. However, such methods leverage fixed, pre-defined perturbations and require significant hyper-parameter tuning that makes them very difficult to leverage in a general fashion. In this study, we introduce Learn2Perturb, an end-to-end feature perturbation learning approach for improving the adversarial robustness of deep neural networks. More specifically, we introduce novel perturbation-injection modules that are incorporated at each layer to perturb the feature space and increase uncertainty in the network. This feature perturbation is performed at both the training and the inference stages. Furthermore, inspired by the Expectation-Maximization, an alternating back-propagation training algorithm is introduced to train the network and noise parameters consecutively. Experimental results on CIFAR-10 and CIFAR-100 datasets show that the proposed Learn2Perturb method can result in deep neural networks which are $4-7\%$ more robust on $l_{\infty}$ FGSM and PDG adversarial attacks and significantly outperforms the state-of-the-art against $l_2$ $C\&W$ attack and a wide range of well-known black-box attacks.
StressedNets: Efficient Feature Representations via Stress-induced Evolutionary Synthesis of Deep Neural Networks
Jan 16, 2018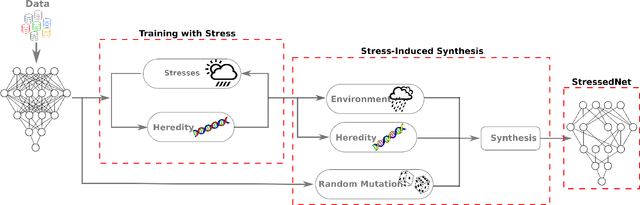
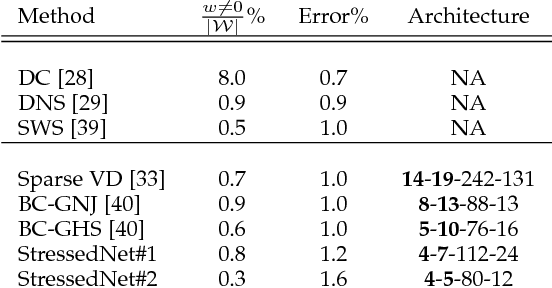
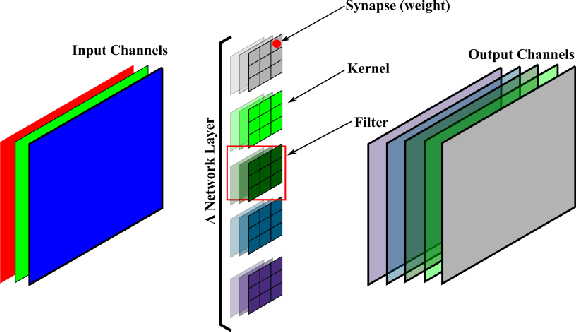

The computational complexity of leveraging deep neural networks for extracting deep feature representations is a significant barrier to its widespread adoption, particularly for use in embedded devices. One particularly promising strategy to addressing the complexity issue is the notion of evolutionary synthesis of deep neural networks, which was demonstrated to successfully produce highly efficient deep neural networks while retaining modeling performance. Here, we further extend upon the evolutionary synthesis strategy for achieving efficient feature extraction via the introduction of a stress-induced evolutionary synthesis framework, where stress signals are imposed upon the synapses of a deep neural network during training to induce stress and steer the synthesis process towards the production of more efficient deep neural networks over successive generations and improved model fidelity at a greater efficiency. The proposed stress-induced evolutionary synthesis approach is evaluated on a variety of different deep neural network architectures (LeNet5, AlexNet, and YOLOv2) on different tasks (object classification and object detection) to synthesize efficient StressedNets over multiple generations. Experimental results demonstrate the efficacy of the proposed framework to synthesize StressedNets with significant improvement in network architecture efficiency (e.g., 40x for AlexNet and 33x for YOLOv2) and speed improvements (e.g., 5.5x inference speed-up for YOLOv2 on an Nvidia Tegra X1 mobile processor).
Non-contact transmittance photoplethysmographic imaging (PPGI) for long-distance cardiovascular monitoring
Mar 23, 2015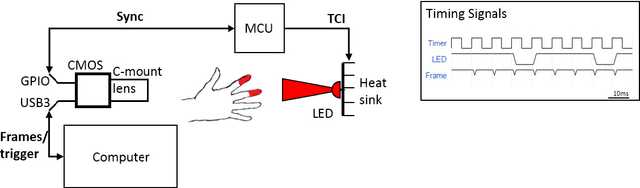



Photoplethysmography (PPG) devices are widely used for monitoring cardiovascular function. However, these devices require skin contact, which restrict their use to at-rest short-term monitoring using single-point measurements. Photoplethysmographic imaging (PPGI) has been recently proposed as a non-contact monitoring alternative by measuring blood pulse signals across a spatial region of interest. Existing systems operate in reflectance mode, of which many are limited to short-distance monitoring and are prone to temporal changes in ambient illumination. This paper is the first study to investigate the feasibility of long-distance non-contact cardiovascular monitoring at the supermeter level using transmittance PPGI. For this purpose, a novel PPGI system was designed at the hardware and software level using ambient correction via temporally coded illumination (TCI) and signal processing for PPGI signal extraction. Experimental results show that the processing steps yield a substantially more pulsatile PPGI signal than the raw acquired signal, resulting in statistically significant increases in correlation to ground-truth PPG in both short- ($p \in [<0.0001, 0.040]$) and long-distance ($p \in [<0.0001, 0.056]$) monitoring. The results support the hypothesis that long-distance heart rate monitoring is feasible using transmittance PPGI, allowing for new possibilities of monitoring cardiovascular function in a non-contact manner.