 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuzzle Curriculum GRPO for Vision-Centric Reasoning
Dec 16, 2025Recent reinforcement learning (RL) approaches like outcome-supervised GRPO have advanced chain-of-thought reasoning in Vision Language Models (VLMs), yet key issues linger: (i) reliance on costly and noisy hand-curated annotations or external verifiers; (ii) flat and sparse reward schemes in GRPO; and (iii) logical inconsistency between a chain's reasoning and its final answer. We present Puzzle Curriculum GRPO (PC-GRPO), a supervision-free recipe for RL with Verifiable Rewards (RLVR) that strengthens visual reasoning in VLMs without annotations or external verifiers. PC-GRPO replaces labels with three self-supervised puzzle environments: PatchFit, Rotation (with binary rewards) and Jigsaw (with graded partial credit mitigating reward sparsity). To counter flat rewards and vanishing group-relative advantages, we introduce a difficulty-aware curriculum that dynamically weights samples and peaks at medium difficulty. We further monitor Reasoning-Answer Consistency (RAC) during post-training: mirroring reports for vanilla GRPO in LLMs, RAC typically rises early then degrades; our curriculum delays this decline, and consistency-enforcing reward schemes further boost RAC. RAC correlates with downstream accuracy. Across diverse benchmarks and on Qwen-7B and Qwen-3B backbones, PC-GRPO improves reasoning quality, training stability, and end-task accuracy, offering a practical path to scalable, verifiable, and interpretable RL post-training for VLMs.
Similarity-Aware Token Pruning: Your VLM but Faster
Mar 14, 2025The computational demands of Vision Transformers (ViTs) and Vision-Language Models (VLMs) remain a significant challenge due to the quadratic complexity of self-attention. While token pruning offers a promising solution, existing methods often introduce training overhead or fail to adapt dynamically across layers. We present SAINT, a training-free token pruning framework that leverages token similarity and a graph-based formulation to dynamically optimize pruning rates and redundancy thresholds. Through systematic analysis, we identify a universal three-stage token evolution process (aligner-explorer-aggregator) in transformers, enabling aggressive pruning in early stages without sacrificing critical information. For ViTs, SAINT doubles the throughput of ViT-H/14 at 224px with only 0.6% accuracy loss on ImageNet-1K, surpassing the closest competitor by 0.8%. For VLMs, we apply SAINT in three modes: ViT-only, LLM-only, and hybrid. SAINT reduces LLaVA-13B's tokens by 75%, achieving latency comparable to LLaVA-7B with less than 1% performance loss across benchmarks. Our work establishes a unified, practical framework for efficient inference in ViTs and VLMs.
QGen: On the Ability to Generalize in Quantization Aware Training
Apr 19, 2024



Quantization lowers memory usage, computational requirements, and latency by utilizing fewer bits to represent model weights and activations. In this work, we investigate the generalization properties of quantized neural networks, a characteristic that has received little attention despite its implications on model performance. In particular, first, we develop a theoretical model for quantization in neural networks and demonstrate how quantization functions as a form of regularization. Second, motivated by recent work connecting the sharpness of the loss landscape and generalization, we derive an approximate bound for the generalization of quantized models conditioned on the amount of quantization noise. We then validate our hypothesis by experimenting with over 2000 models trained on CIFAR-10, CIFAR-100, and ImageNet datasets on convolutional and transformer-based models.
A Simple Fine-tuning Is All You Need: Towards Robust Deep Learning Via Adversarial Fine-tuning
Dec 25, 2020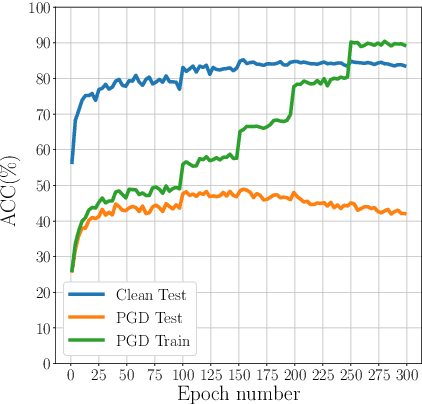


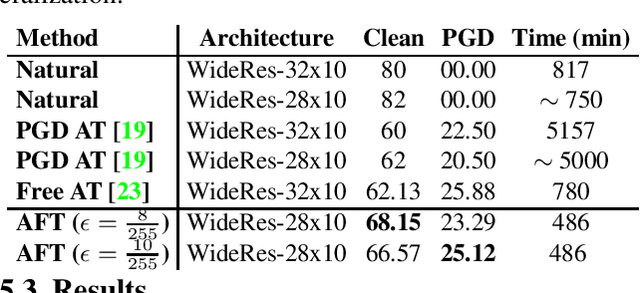
Adversarial Training (AT) with Projected Gradient Descent (PGD) is an effective approach for improving the robustness of the deep neural networks. However, PGD AT has been shown to suffer from two main limitations: i) high computational cost, and ii) extreme overfitting during training that leads to reduction in model generalization. While the effect of factors such as model capacity and scale of training data on adversarial robustness have been extensively studied, little attention has been paid to the effect of a very important parameter in every network optimization on adversarial robustness: the learning rate. In particular, we hypothesize that effective learning rate scheduling during adversarial training can significantly reduce the overfitting issue, to a degree where one does not even need to adversarially train a model from scratch but can instead simply adversarially fine-tune a pre-trained model. Motivated by this hypothesis, we propose a simple yet very effective adversarial fine-tuning approach based on a $\textit{slow start, fast decay}$ learning rate scheduling strategy which not only significantly decreases computational cost required, but also greatly improves the accuracy and robustness of a deep neural network. Experimental results show that the proposed adversarial fine-tuning approach outperforms the state-of-the-art methods on CIFAR-10, CIFAR-100 and ImageNet datasets in both test accuracy and the robustness, while reducing the computational cost by 8-10$\times$. Furthermore, a very important benefit of the proposed adversarial fine-tuning approach is that it enables the ability to improve the robustness of any pre-trained deep neural network without needing to train the model from scratch, which to the best of the authors' knowledge has not been previously demonstrated in research literature.
Tackling the Problem of Limited Data and Annotations in Semantic Segmentation
Jul 14, 2020


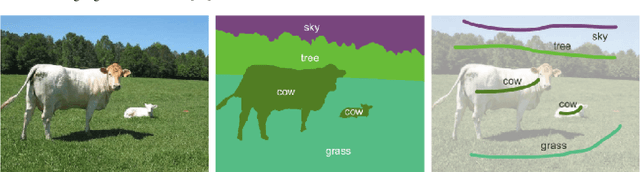
In this work, the case of semantic segmentation on a small image dataset (simulated by 1000 randomly selected images from PASCAL VOC 2012), where only weak supervision signals (scribbles from user interaction) are available is studied. Especially, to tackle the problem of limited data annotations in image segmentation, transferring different pre-trained models and CRF based methods are applied to enhance the segmentation performance. To this end, RotNet, DeeperCluster, and Semi&Weakly Supervised Learning (SWSL) pre-trained models are transferred and finetuned in a DeepLab-v2 baseline, and dense CRF is applied both as a post-processing and loss regularization technique. The results of my study show that, on this small dataset, using a pre-trained ResNet50 SWSL model gives results that are 7.4% better than applying an ImageNet pre-trained model; moreover, for the case of training on the full PASCAL VOC 2012 training data, this pre-training approach increases the mIoU results by almost 4%. On the other hand, dense CRF is shown to be very effective as well, enhancing the results both as a loss regularization technique in weakly supervised training and as a post-processing tool.
Deep Neural Network Perception Models and Robust Autonomous Driving Systems
Mar 04, 2020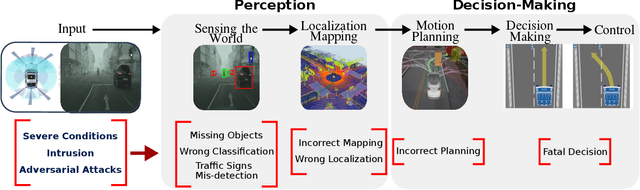



This paper analyzes the robustness of deep learning models in autonomous driving applications and discusses the practical solutions to address that.
Learn2Perturb: an End-to-end Feature Perturbation Learning to Improve Adversarial Robustness
Mar 03, 2020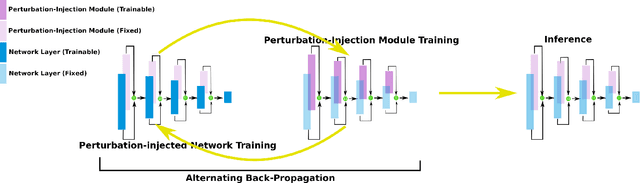


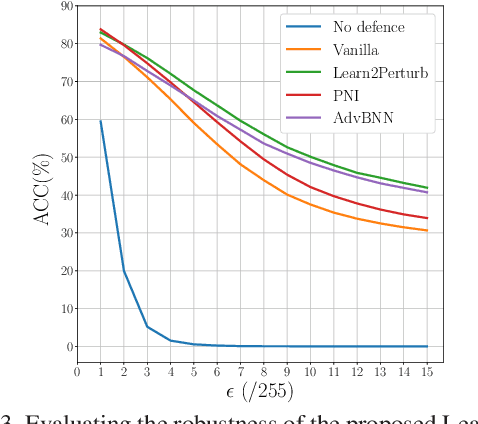
While deep neural networks have been achieving state-of-the-art performance across a wide variety of applications, their vulnerability to adversarial attacks limits their widespread deployment for safety-critical applications. Alongside other adversarial defense approaches being investigated, there has been a very recent interest in improving adversarial robustness in deep neural networks through the introduction of perturbations during the training process. However, such methods leverage fixed, pre-defined perturbations and require significant hyper-parameter tuning that makes them very difficult to leverage in a general fashion. In this study, we introduce Learn2Perturb, an end-to-end feature perturbation learning approach for improving the adversarial robustness of deep neural networks. More specifically, we introduce novel perturbation-injection modules that are incorporated at each layer to perturb the feature space and increase uncertainty in the network. This feature perturbation is performed at both the training and the inference stages. Furthermore, inspired by the Expectation-Maximization, an alternating back-propagation training algorithm is introduced to train the network and noise parameters consecutively. Experimental results on CIFAR-10 and CIFAR-100 datasets show that the proposed Learn2Perturb method can result in deep neural networks which are $4-7\%$ more robust on $l_{\infty}$ FGSM and PDG adversarial attacks and significantly outperforms the state-of-the-art against $l_2$ $C\&W$ attack and a wide range of well-known black-box attacks.