 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIce Hockey Puck Localization Using Contextual Cues
Jun 04, 2025Puck detection in ice hockey broadcast videos poses significant challenges due to the puck's small size, frequent occlusions, motion blur, broadcast artifacts, and scale inconsistencies due to varying camera zoom and broadcast camera viewpoints. Prior works focus on appearance-based or motion-based cues of the puck without explicitly modelling the cues derived from player behaviour. Players consistently turn their bodies and direct their gaze toward the puck. Motivated by this strong contextual cue, we propose Puck Localization Using Contextual Cues (PLUCC), a novel approach for scale-aware and context-driven single-frame puck detections. PLUCC consists of three components: (a) a contextual encoder, which utilizes player orientations and positioning as helpful priors; (b) a feature pyramid encoder, which extracts multiscale features from the dual encoders; and (c) a gating decoder that combines latent features with a channel gating mechanism. For evaluation, in addition to standard average precision, we propose Rink Space Localization Error (RSLE), a scale-invariant homography-based metric for removing perspective bias from rink space evaluation. The experimental results of PLUCC on the PuckDataset dataset demonstrated state-of-the-art detection performance, surpassing previous baseline methods by an average precision improvement of 12.2% and RSLE average precision of 25%. Our research demonstrates the critical role of contextual understanding in improving puck detection performance, with broad implications for automated sports analysis.
Particle-Filtering-based Latent Diffusion for Inverse Problems
Aug 25, 2024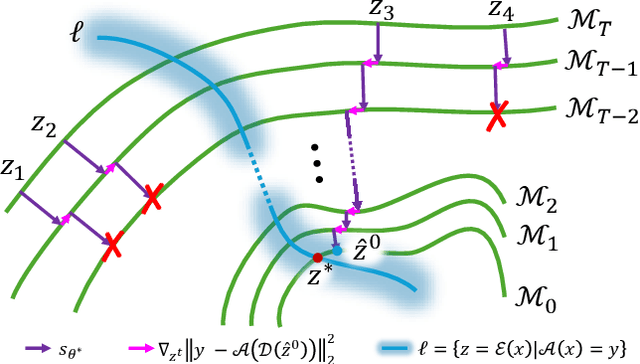
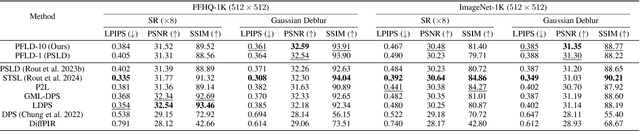
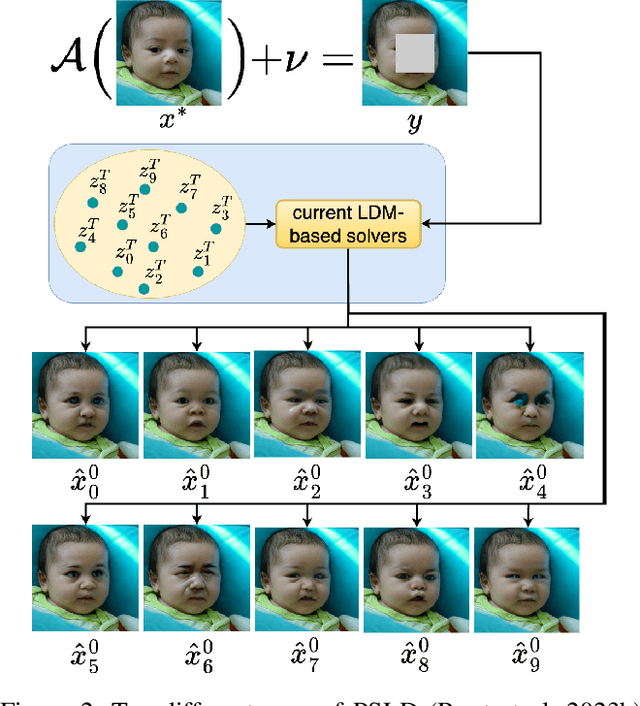

Current strategies for solving image-based inverse problems apply latent diffusion models to perform posterior sampling.However, almost all approaches make no explicit attempt to explore the solution space, instead drawing only a single sample from a Gaussian distribution from which to generate their solution. In this paper, we introduce a particle-filtering-based framework for a nonlinear exploration of the solution space in the initial stages of reverse SDE methods. Our proposed particle-filtering-based latent diffusion (PFLD) method and proposed problem formulation and framework can be applied to any diffusion-based solution for linear or nonlinear inverse problems. Our experimental results show that PFLD outperforms the SoTA solver PSLD on the FFHQ-1K and ImageNet-1K datasets on inverse problem tasks of super resolution, Gaussian debluring and inpainting.
Challenges for Predictive Modeling with Neural Network Techniques using Error-Prone Dietary Intake Data
Nov 15, 2023



Dietary intake data are routinely drawn upon to explore diet-health relationships. However, these data are often subject to measurement error, distorting the true relationships. Beyond measurement error, there are likely complex synergistic and sometimes antagonistic interactions between different dietary components, complicating the relationships between diet and health outcomes. Flexible models are required to capture the nuance that these complex interactions introduce. This complexity makes research on diet-health relationships an appealing candidate for the application of machine learning techniques, and in particular, neural networks. Neural networks are computational models that are able to capture highly complex, nonlinear relationships so long as sufficient data are available. While these models have been applied in many domains, the impacts of measurement error on the performance of predictive modeling has not been systematically investigated. However, dietary intake data are typically collected using self-report methods and are prone to large amounts of measurement error. In this work, we demonstrate the ways in which measurement error erodes the performance of neural networks, and illustrate the care that is required for leveraging these models in the presence of error. We demonstrate the role that sample size and replicate measurements play on model performance, indicate a motivation for the investigation of transformations to additivity, and illustrate the caution required to prevent model overfitting. While the past performance of neural networks across various domains make them an attractive candidate for examining diet-health relationships, our work demonstrates that substantial care and further methodological development are both required to observe increased predictive performance when applying these techniques, compared to more traditional statistical procedures.
Memory-Efficient Continual Learning Object Segmentation for Long Video
Sep 26, 2023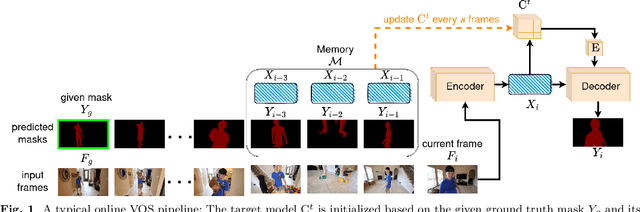



Recent state-of-the-art semi-supervised Video Object Segmentation (VOS) methods have shown significant improvements in target object segmentation accuracy when information from preceding frames is used in undertaking segmentation on the current frame. In particular, such memory-based approaches can help a model to more effectively handle appearance changes (representation drift) or occlusions. Ideally, for maximum performance, online VOS methods would need all or most of the preceding frames (or their extracted information) to be stored in memory and be used for online learning in consecutive frames. Such a solution is not feasible for long videos, as the required memory size would grow without bound. On the other hand, these methods can fail when memory is limited and a target object experiences repeated representation drifts throughout a video. We propose two novel techniques to reduce the memory requirement of online VOS methods while improving modeling accuracy and generalization on long videos. Motivated by the success of continual learning techniques in preserving previously-learned knowledge, here we propose Gated-Regularizer Continual Learning (GRCL), which improves the performance of any online VOS subject to limited memory, and a Reconstruction-based Memory Selection Continual Learning (RMSCL) which empowers online VOS methods to efficiently benefit from stored information in memory. Experimental results show that the proposed methods improve the performance of online VOS models up to 10 %, and boosts their robustness on long-video datasets while maintaining comparable performance on short-video datasets DAVIS16 and DAVIS17.
CLVOS23: A Long Video Object Segmentation Dataset for Continual Learning
Apr 09, 2023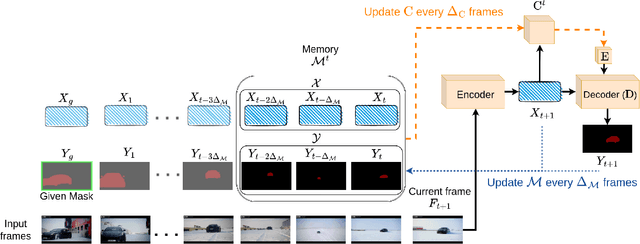
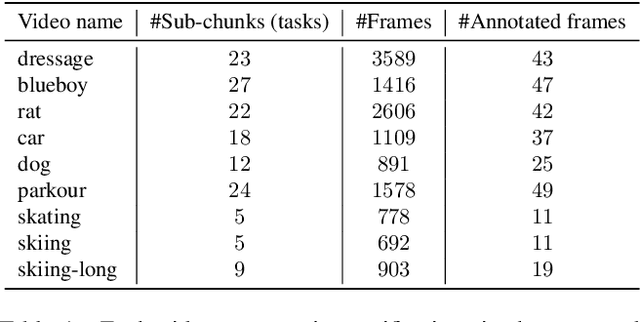


Continual learning in real-world scenarios is a major challenge. A general continual learning model should have a constant memory size and no predefined task boundaries, as is the case in semi-supervised Video Object Segmentation (VOS), where continual learning challenges particularly present themselves in working on long video sequences. In this article, we first formulate the problem of semi-supervised VOS, specifically online VOS, as a continual learning problem, and then secondly provide a public VOS dataset, CLVOS23, focusing on continual learning. Finally, we propose and implement a regularization-based continual learning approach on LWL, an existing online VOS baseline, to demonstrate the efficacy of continual learning when applied to online VOS and to establish a CLVOS23 baseline. We apply the proposed baseline to the Long Videos dataset as well as to two short video VOS datasets, DAVIS16 and DAVIS17. To the best of our knowledge, this is the first time that VOS has been defined and addressed as a continual learning problem.
Deep Neural Network Perception Models and Robust Autonomous Driving Systems
Mar 04, 2020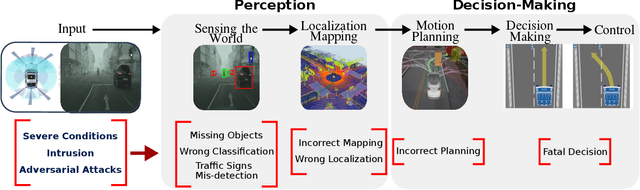



This paper analyzes the robustness of deep learning models in autonomous driving applications and discusses the practical solutions to address that.
Potential adversarial samples for white-box attacks
Dec 13, 2019


Deep convolutional neural networks can be highly vulnerable to small perturbations of their inputs, potentially a major issue or limitation on system robustness when using deep networks as classifiers. In this paper we propose a low-cost method to explore marginal sample data near trained classifier decision boundaries, thus identifying potential adversarial samples. By finding such adversarial samples it is possible to reduce the search space of adversarial attack algorithms while keeping a reasonable successful perturbation rate. In our developed strategy, the potential adversarial samples represent only 61% of the test data, but in fact cover more than 82% of the adversarial samples produced by iFGSM and 92% of the adversarial samples successfully perturbed by DeepFool on CIFAR10.
Unsupervised Feature Learning Toward a Real-time Vehicle Make and Model Recognition
Jun 08, 2018


Vehicle Make and Model Recognition (MMR) systems provide a fully automatic framework to recognize and classify different vehicle models. Several approaches have been proposed to address this challenge, however they can perform in restricted conditions. Here, we formulate the vehicle make and model recognition as a fine-grained classification problem and propose a new configurable on-road vehicle make and model recognition framework. We benefit from the unsupervised feature learning methods and in more details we employ Locality constraint Linear Coding (LLC) method as a fast feature encoder for encoding the input SIFT features. The proposed method can perform in real environments of different conditions. This framework can recognize fifty models of vehicles and has an advantage to classify every other vehicle not belonging to one of the specified fifty classes as an unknown vehicle. The proposed MMR framework can be configured to become faster or more accurate based on the application domain. The proposed approach is examined on two datasets including Iranian on-road vehicle dataset and CompuCar dataset. The Iranian on-road vehicle dataset contains images of 50 models of vehicles captured in real situations by traffic cameras in different weather and lighting conditions. Experimental results show superiority of the proposed framework over the state-of-the-art methods on Iranian on-road vehicle datatset and comparable results on CompuCar dataset with 97.5% and 98.4% accuracies, respectively.