 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Pre-Release Baseball Pitch Type Anticipation from Broadcast 3D Kinematics
Mar 05, 2026How much can a pitcher's body reveal about the upcoming pitch? We study this question at scale by classifying eight pitch types from monocular 3D pose sequences, without access to ball-flight data. Our pipeline chains a diffusion-based 3D pose backbone with automatic pitching-event detection, groundtruth-validated biomechanical feature extraction, and gradient-boosted classification over 229 kinematic features. Evaluated on 119,561 professional pitches, the largest such benchmark to date, we achieve 80.4\% accuracy using body kinematics alone. A systematic importance analysis reveals that upper-body mechanics contribute 64.9\% of the predictive signal versus 35.1\% for the lower body, with wrist position (14.8\%) and trunk lateral tilt emerging as the most informative joint group and biomechanical feature, respectively. We further show that grip-defined variants (four-seam vs.\ two-seam fastball) are not separable from pose, establishing an empirical ceiling near 80\% and delineating where kinematic information ends and ball-flight information begins.
Scalable Injury-Risk Screening in Baseball Pitching From Broadcast Video
Mar 05, 2026Injury prediction in pitching depends on precise biomechanical signals, yet gold-standard measurements come from expensive, stadium-installed multi-camera systems that are unavailable outside professional venues. We present a monocular video pipeline that recovers 18 clinically relevant biomechanics metrics from broadcast footage, positioning pose-derived kinematics as a scalable source for injury-risk modeling. Built on DreamPose3D, our approach introduces a drift-controlled global lifting module that recovers pelvis trajectory via velocity-based parameterization and sliding-window inference, lifting pelvis-rooted poses into global space. To address motion blur, compression artifacts, and extreme pitching poses, we incorporate a kinematics refinement pipeline with bone-length constraints, joint-limited inverse kinematics, smoothing, and symmetry constraints to ensure temporally stable and physically plausible kinematics. On 13 professional pitchers (156 paired pitches), 16/18 metrics achieve sub-degree agreement (MAE $< 1^{\circ}$). Using these metrics for injury prediction, an automated screening model achieves AUC 0.811 for Tommy John surgery and 0.825 for significant arm injuries on 7,348 pitchers. The resulting pose-derived metrics support scalable injury-risk screening, establishing monocular broadcast video as a viable alternative to stadium-scale motion capture for biomechanics.
Avatar4D: Synthesizing Domain-Specific 4D Humans for Real-World Pose Estimation
Dec 18, 2025We present Avatar4D, a real-world transferable pipeline for generating customizable synthetic human motion datasets tailored to domain-specific applications. Unlike prior works, which focus on general, everyday motions and offer limited flexibility, our approach provides fine-grained control over body pose, appearance, camera viewpoint, and environmental context, without requiring any manual annotations. To validate the impact of Avatar4D, we focus on sports, where domain-specific human actions and movement patterns pose unique challenges for motion understanding. In this setting, we introduce Syn2Sport, a large-scale synthetic dataset spanning sports, including baseball and ice hockey. Avatar4D features high-fidelity 4D (3D geometry over time) human motion sequences with varying player appearances rendered in diverse environments. We benchmark several state-of-the-art pose estimation models on Syn2Sport and demonstrate their effectiveness for supervised learning, zero-shot transfer to real-world data, and generalization across sports. Furthermore, we evaluate how closely the generated synthetic data aligns with real-world datasets in feature space. Our results highlight the potential of such systems to generate scalable, controllable, and transferable human datasets for diverse domain-specific tasks without relying on domain-specific real data.
DreamPose3D: Hallucinative Diffusion with Prompt Learning for 3D Human Pose Estimation
Nov 12, 2025Accurate 3D human pose estimation remains a critical yet unresolved challenge, requiring both temporal coherence across frames and fine-grained modeling of joint relationships. However, most existing methods rely solely on geometric cues and predict each 3D pose independently, which limits their ability to resolve ambiguous motions and generalize to real-world scenarios. Inspired by how humans understand and anticipate motion, we introduce DreamPose3D, a diffusion-based framework that combines action-aware reasoning with temporal imagination for 3D pose estimation. DreamPose3D dynamically conditions the denoising process using task-relevant action prompts extracted from 2D pose sequences, capturing high-level intent. To model the structural relationships between joints effectively, we introduce a representation encoder that incorporates kinematic joint affinity into the attention mechanism. Finally, a hallucinative pose decoder predicts temporally coherent 3D pose sequences during training, simulating how humans mentally reconstruct motion trajectories to resolve ambiguity in perception. Extensive experiments on benchmarked Human3.6M and MPI-3DHP datasets demonstrate state-of-the-art performance across all metrics. To further validate DreamPose3D's robustness, we tested it on a broadcast baseball dataset, where it demonstrated strong performance despite ambiguous and noisy 2D inputs, effectively handling temporal consistency and intent-driven motion variations.
Ice Hockey Puck Localization Using Contextual Cues
Jun 04, 2025
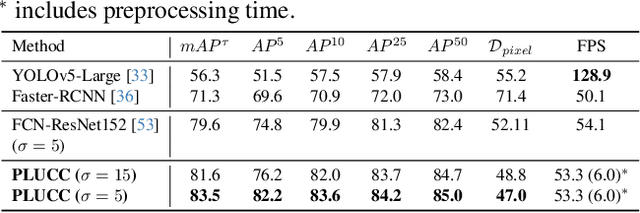
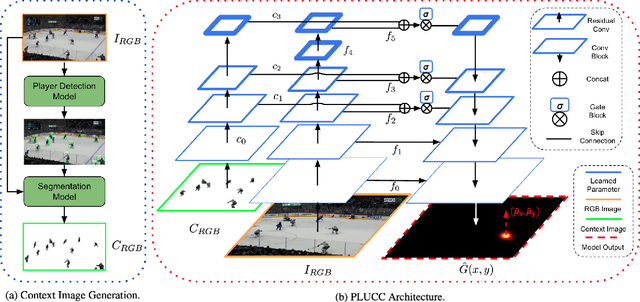

Puck detection in ice hockey broadcast videos poses significant challenges due to the puck's small size, frequent occlusions, motion blur, broadcast artifacts, and scale inconsistencies due to varying camera zoom and broadcast camera viewpoints. Prior works focus on appearance-based or motion-based cues of the puck without explicitly modelling the cues derived from player behaviour. Players consistently turn their bodies and direct their gaze toward the puck. Motivated by this strong contextual cue, we propose Puck Localization Using Contextual Cues (PLUCC), a novel approach for scale-aware and context-driven single-frame puck detections. PLUCC consists of three components: (a) a contextual encoder, which utilizes player orientations and positioning as helpful priors; (b) a feature pyramid encoder, which extracts multiscale features from the dual encoders; and (c) a gating decoder that combines latent features with a channel gating mechanism. For evaluation, in addition to standard average precision, we propose Rink Space Localization Error (RSLE), a scale-invariant homography-based metric for removing perspective bias from rink space evaluation. The experimental results of PLUCC on the PuckDataset dataset demonstrated state-of-the-art detection performance, surpassing previous baseline methods by an average precision improvement of 12.2% and RSLE average precision of 25%. Our research demonstrates the critical role of contextual understanding in improving puck detection performance, with broad implications for automated sports analysis.
PitcherNet: Powering the Moneyball Evolution in Baseball Video Analytics
May 13, 2024
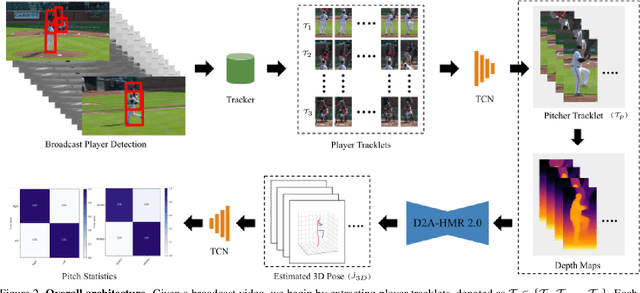
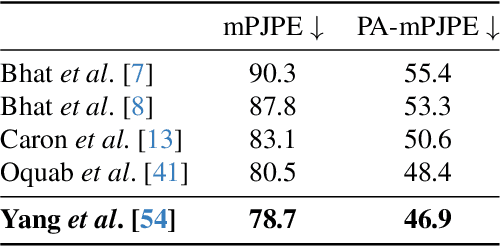
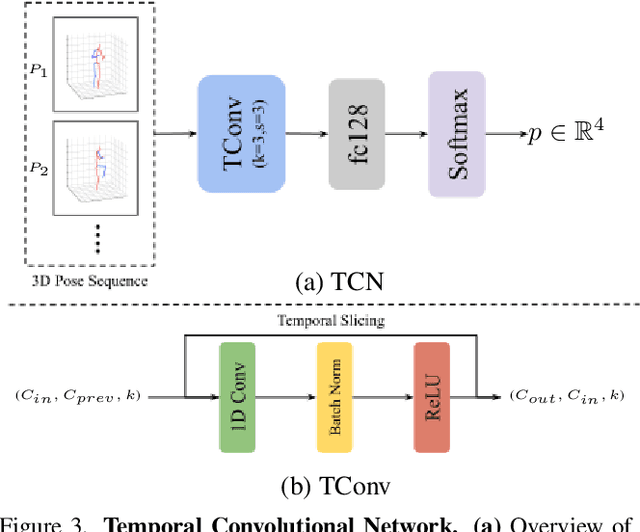
In the high-stakes world of baseball, every nuance of a pitcher's mechanics holds the key to maximizing performance and minimizing runs. Traditional analysis methods often rely on pre-recorded offline numerical data, hindering their application in the dynamic environment of live games. Broadcast video analysis, while seemingly ideal, faces significant challenges due to factors like motion blur and low resolution. To address these challenges, we introduce PitcherNet, an end-to-end automated system that analyzes pitcher kinematics directly from live broadcast video, thereby extracting valuable pitch statistics including velocity, release point, pitch position, and release extension. This system leverages three key components: (1) Player tracking and identification by decoupling actions from player kinematics; (2) Distribution and depth-aware 3D human modeling; and (3) Kinematic-driven pitch statistics. Experimental validation demonstrates that PitcherNet achieves robust analysis results with 96.82% accuracy in pitcher tracklet identification, reduced joint position error by 1.8mm and superior analytics compared to baseline methods. By enabling performance-critical kinematic analysis from broadcast video, PitcherNet paves the way for the future of baseball analytics by optimizing pitching strategies, preventing injuries, and unlocking a deeper understanding of pitcher mechanics, forever transforming the game.
Domain-Guided Masked Autoencoders for Unique Player Identification
Mar 17, 2024
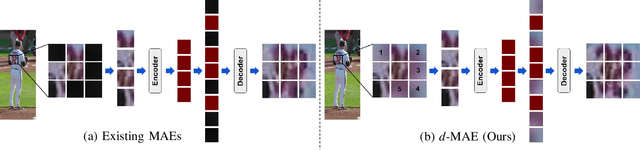
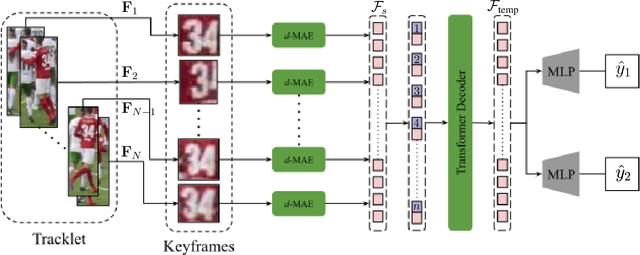

Unique player identification is a fundamental module in vision-driven sports analytics. Identifying players from broadcast videos can aid with various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatic detection of jersey numbers using deep features is challenging primarily due to: a) motion blur, b) low resolution video feed, and c) occlusions. With their recent success in various vision tasks, masked autoencoders (MAEs) have emerged as a superior alternative to conventional feature extractors. However, most MAEs simply zero-out image patches either randomly or focus on where to mask rather than how to mask. Motivated by human vision, we devise a novel domain-guided masking policy for MAEs termed d-MAE to facilitate robust feature extraction in the presence of motion blur for player identification. We further introduce a new spatio-temporal network leveraging our novel d-MAE for unique player identification. We conduct experiments on three large-scale sports datasets, including a curated baseball dataset, the SoccerNet dataset, and an in-house ice hockey dataset. We preprocess the datasets using an upgraded keyframe identification (KfID) module by focusing on frames containing jersey numbers. Additionally, we propose a keyframe-fusion technique to augment keyframes, preserving spatial and temporal context. Our spatio-temporal network showcases significant improvements, surpassing the current state-of-the-art by 8.58%, 4.29%, and 1.20% in the test set accuracies, respectively. Rigorous ablations highlight the effectiveness of our domain-guided masking approach and the refined KfID module, resulting in performance enhancements of 1.48% and 1.84% respectively, compared to original architectures.
Distribution and Depth-Aware Transformers for 3D Human Mesh Recovery
Mar 14, 2024



Precise Human Mesh Recovery (HMR) with in-the-wild data is a formidable challenge and is often hindered by depth ambiguities and reduced precision. Existing works resort to either pose priors or multi-modal data such as multi-view or point cloud information, though their methods often overlook the valuable scene-depth information inherently present in a single image. Moreover, achieving robust HMR for out-of-distribution (OOD) data is exceedingly challenging due to inherent variations in pose, shape and depth. Consequently, understanding the underlying distribution becomes a vital subproblem in modeling human forms. Motivated by the need for unambiguous and robust human modeling, we introduce Distribution and depth-aware human mesh recovery (D2A-HMR), an end-to-end transformer architecture meticulously designed to minimize the disparity between distributions and incorporate scene-depth leveraging prior depth information. Our approach demonstrates superior performance in handling OOD data in certain scenarios while consistently achieving competitive results against state-of-the-art HMR methods on controlled datasets.
Jersey Number Recognition using Keyframe Identification from Low-Resolution Broadcast Videos
Sep 12, 2023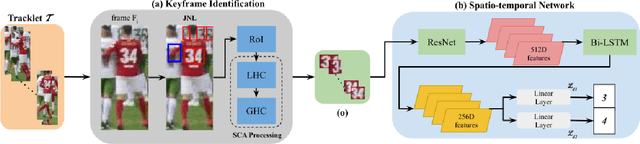

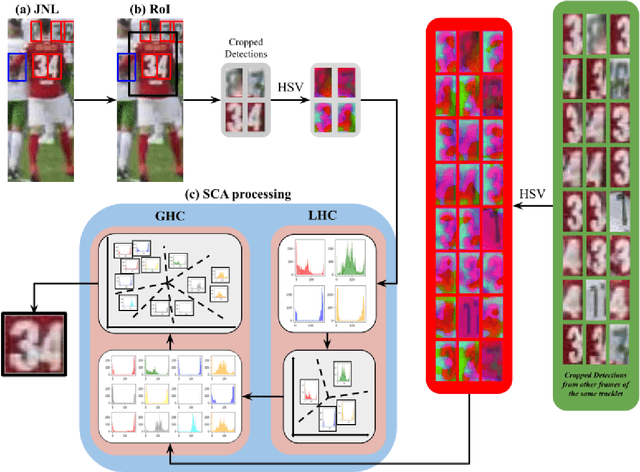

Player identification is a crucial component in vision-driven soccer analytics, enabling various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatically detecting jersey numbers from player tracklets in videos presents challenges due to motion blur, low resolution, distortions, and occlusions. Existing methods, utilizing Spatial Transformer Networks, CNNs, and Vision Transformers, have shown success in image data but struggle with real-world video data, where jersey numbers are not visible in most of the frames. Hence, identifying frames that contain the jersey number is a key sub-problem to tackle. To address these issues, we propose a robust keyframe identification module that extracts frames containing essential high-level information about the jersey number. A spatio-temporal network is then employed to model spatial and temporal context and predict the probabilities of jersey numbers in the video. Additionally, we adopt a multi-task loss function to predict the probability distribution of each digit separately. Extensive evaluations on the SoccerNet dataset demonstrate that incorporating our proposed keyframe identification module results in a significant 37.81% and 37.70% increase in the accuracies of 2 different test sets with domain gaps. These results highlight the effectiveness and importance of our approach in tackling the challenges of automatic jersey number detection in sports videos.
Mitigating Motion Blur for Robust 3D Baseball Player Pose Modeling for Pitch Analysis
Sep 02, 2023Using videos to analyze pitchers in baseball can play a vital role in strategizing and injury prevention. Computer vision-based pose analysis offers a time-efficient and cost-effective approach. However, the use of accessible broadcast videos, with a 30fps framerate, often results in partial body motion blur during fast actions, limiting the performance of existing pose keypoint estimation models. Previous works have primarily relied on fixed backgrounds, assuming minimal motion differences between frames, or utilized multiview data to address this problem. To this end, we propose a synthetic data augmentation pipeline to enhance the model's capability to deal with the pitcher's blurry actions. In addition, we leverage in-the-wild videos to make our model robust under different real-world conditions and camera positions. By carefully optimizing the augmentation parameters, we observed a notable reduction in the loss by 54.2% and 36.2% on the test dataset for 2D and 3D pose estimation respectively. By applying our approach to existing state-of-the-art pose estimators, we demonstrate an average improvement of 29.2%. The findings highlight the effectiveness of our method in mitigating the challenges posed by motion blur, thereby enhancing the overall quality of pose estimation.