 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Player Tracking in Ice Hockey with Homographic Projections
May 22, 2024Multi Object Tracking (MOT) in ice hockey pursues the combined task of localizing and associating players across a given sequence to maintain their identities. Tracking players from monocular broadcast feeds is an important computer vision problem offering various downstream analytics and enhanced viewership experience. However, existing trackers encounter significant difficulties in dealing with occlusions, blurs, and agile player movements prevalent in telecast feeds. In this work, we propose a novel tracking approach by formulating MOT as a bipartite graph matching problem infused with homography. We disentangle the positional representations of occluded and overlapping players in broadcast view, by mapping their foot keypoints to an overhead rink template, and encode these projected positions into the graph network. This ensures reliable spatial context for consistent player tracking and unfragmented tracklet prediction. Our results show considerable improvements in both the IDsw and IDF1 metrics on the two available broadcast ice hockey datasets.
Distribution and Depth-Aware Transformers for 3D Human Mesh Recovery
Mar 14, 2024



Precise Human Mesh Recovery (HMR) with in-the-wild data is a formidable challenge and is often hindered by depth ambiguities and reduced precision. Existing works resort to either pose priors or multi-modal data such as multi-view or point cloud information, though their methods often overlook the valuable scene-depth information inherently present in a single image. Moreover, achieving robust HMR for out-of-distribution (OOD) data is exceedingly challenging due to inherent variations in pose, shape and depth. Consequently, understanding the underlying distribution becomes a vital subproblem in modeling human forms. Motivated by the need for unambiguous and robust human modeling, we introduce Distribution and depth-aware human mesh recovery (D2A-HMR), an end-to-end transformer architecture meticulously designed to minimize the disparity between distributions and incorporate scene-depth leveraging prior depth information. Our approach demonstrates superior performance in handling OOD data in certain scenarios while consistently achieving competitive results against state-of-the-art HMR methods on controlled datasets.
Jersey Number Recognition using Keyframe Identification from Low-Resolution Broadcast Videos
Sep 12, 2023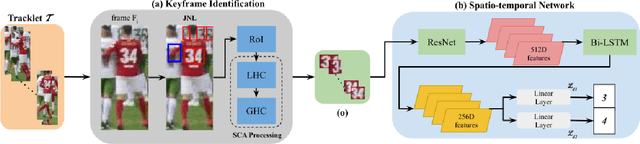

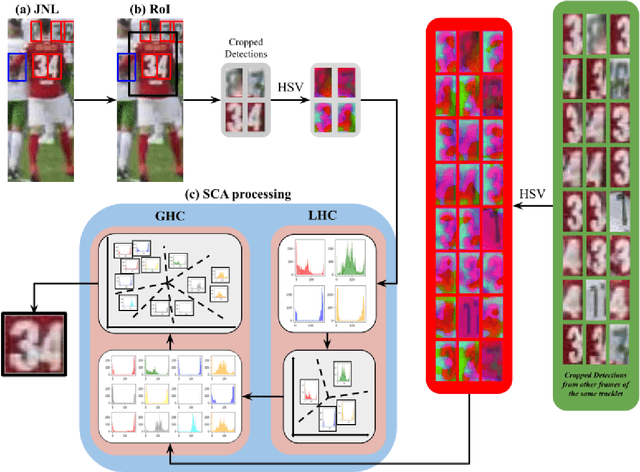

Player identification is a crucial component in vision-driven soccer analytics, enabling various downstream tasks such as player assessment, in-game analysis, and broadcast production. However, automatically detecting jersey numbers from player tracklets in videos presents challenges due to motion blur, low resolution, distortions, and occlusions. Existing methods, utilizing Spatial Transformer Networks, CNNs, and Vision Transformers, have shown success in image data but struggle with real-world video data, where jersey numbers are not visible in most of the frames. Hence, identifying frames that contain the jersey number is a key sub-problem to tackle. To address these issues, we propose a robust keyframe identification module that extracts frames containing essential high-level information about the jersey number. A spatio-temporal network is then employed to model spatial and temporal context and predict the probabilities of jersey numbers in the video. Additionally, we adopt a multi-task loss function to predict the probability distribution of each digit separately. Extensive evaluations on the SoccerNet dataset demonstrate that incorporating our proposed keyframe identification module results in a significant 37.81% and 37.70% increase in the accuracies of 2 different test sets with domain gaps. These results highlight the effectiveness and importance of our approach in tackling the challenges of automatic jersey number detection in sports videos.