 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistGS: Differentiable Physics for Object Permanence in 4D Gaussian Splatting
Jun 02, 2026Dynamic 3D Gaussian Splatting (3DGS) methods reconstruct time-varying scenes from synchronized multi-camera video using photometric supervision. When a moving object becomes fully occluded from all training cameras, this supervision vanishes: the Gaussians representing it receive no gradient signal and degrade. Existing approaches to incomplete observations in neural reconstruction rely on learned generative priors that prioritize visual plausibility over physical correctness. We propose $\textbf{PersistGS}$, a method that restores object permanence during occlusion by coupling differentiable rigid body simulation with 3D Gaussian Splatting. Our approach decomposes the scene into per-object Gaussians and collision meshes, estimates friction and velocity from the observed pre-occlusion trajectory via differentiable simulation, and uses the resulting SE(3) trajectory to position object Gaussians throughout the occlusion period. Because the predicted trajectory satisfies the governing equations of rigid body dynamics, it faithfully captures contact events (bounces, friction-based deceleration, direction changes) that kinematic extrapolation cannot model. We introduce a centroid silhouette loss that isolates positional gradients from appearance noise, yielding 40% lower trajectory error than photometric supervision. We evaluate using cameras withheld from training that observe the object during its occlusion. Experiments on synthetic scenes show that PersistGS outperforms constant velocity extrapolation by +2.46dB PSNR and comes within 0.19dB of a ground-truth trajectory upper bound.
* Accepted in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026 Workshop on Generative 3D Reconstruction
Optimizing 3D Gaussian Splatting via Point Cloud Upsampling
May 30, 20263D Gaussian Splatting (3DGS) is a technique for creating and rendering 3D scenes, however its performance depends heavily on the quality of initial seed points. To improve 3DGS initialization, this study presents and evaluates several point cloud upsampling approaches: linear interpolation, triangular interpolation, spline-based surface reconstruction, moving least squares surface fitting, and Voronoi-based point generation. Additionally, this research introduces a depth-guided point lifting method that leverages depth maps to maintain geometric consistency with Structure-from-Motion (SfM) reconstructions. Through extensive experiments on the Mip-NeRF360 and Replica datasets, the proposed methods demonstrate improvements in reconstruction quality across diverse scene types. Results indicate that different upsampling strategies excel in different scenarios: surface reconstruction methods perform better with organic, detailed scenes, while simpler interpolation approaches are more suited for scenes dominated by piecewise-smooth geometries. In comparison, the depth-guided approach shows promise for adding geometry-aware points across the entire scene, importantly in texture-less regions. These findings, which provide preliminary practical guidelines for selecting appropriate upsampling methods based on scene characteristics and computational constraints, advances the understanding of how point cloud initialization affects 3DGS quality.
* Accepted in Journal of Computational Vision and Imaging Systems (JCVIS)
Real-Time Physics Simulation with Dynamic Mesh-Gaussian Reconstructions
May 30, 2026Integrating dynamic 3D reconstructions into physics simulation requires fixed mesh topology for efficient collision detection, but state-of-the-art methods like DG-Mesh produce varying topology optimized for geometric quality. We investigate whether topology conversion can enable physics integration while preserving reconstruction fidelity. We propose a dual-representation framework combining fixed-topology meshes for physics with Gaussian splatting for rendering, achieving 4.65$\times$ speedup over varying-topology baselines through runtime vertex buffer updates. We evaluate two conversion strategies, temporal correspondence tracking and template-based projection, against native fixed-topology methods (MaGS) on the DG-Mesh dataset. Our evaluation reveals that both conversion approaches incur 65-80% geometric degradation, producing results inferior to MaGS despite DG-Mesh's superior initial quality. This demonstrates that high-quality reconstruction and physics-compatible topology represent fundamentally distinct objectives that cannot be reconciled through post-processing. Our findings inform future development of physics-aware reconstruction methods and our framework enables real-time simulation with any fixed-topology approach.
Beyond Static Gaussians: An Empirical Investigation of Architectural Paradigms for Dynamic 3D Scene Reconstruction
May 30, 2026Dynamic scene reconstruction via 3D Gaussian Splatting (3DGS) has emerged as a compelling approach for representing evolving environments, yet understanding trade-offs between methodologies remains crucial. This paper presents a comprehensive analysis of dynamic 3DGS methods, categorizing them into two paradigms: structure-guided methods employing auxiliary representations (deformation fields, canonical spaces, grids) to model temporal changes, and gaussian-centric methods encoding dynamics directly into primitives via continuous functions or 4D representations. We evaluate representative methods from both paradigms on the D-NeRF benchmark. Our findings reveal that structure-guided methods achieve superior reconstruction fidelity and compact model sizes, while gaussian-centric approaches demonstrate significantly higher rendering speeds enabling real-time performance, though with greater quality variability and potentially substantial storage overhead. This analysis highlights a fundamental trade-off between reconstruction quality/compactness versus rendering speed, providing insights to guide future research and application development in dynamic scene reconstruction.
* Accepted in Journal of Computational Vision and Imaging Systems (JCVIS)
DreamPose3D: Hallucinative Diffusion with Prompt Learning for 3D Human Pose Estimation
Nov 12, 2025Accurate 3D human pose estimation remains a critical yet unresolved challenge, requiring both temporal coherence across frames and fine-grained modeling of joint relationships. However, most existing methods rely solely on geometric cues and predict each 3D pose independently, which limits their ability to resolve ambiguous motions and generalize to real-world scenarios. Inspired by how humans understand and anticipate motion, we introduce DreamPose3D, a diffusion-based framework that combines action-aware reasoning with temporal imagination for 3D pose estimation. DreamPose3D dynamically conditions the denoising process using task-relevant action prompts extracted from 2D pose sequences, capturing high-level intent. To model the structural relationships between joints effectively, we introduce a representation encoder that incorporates kinematic joint affinity into the attention mechanism. Finally, a hallucinative pose decoder predicts temporally coherent 3D pose sequences during training, simulating how humans mentally reconstruct motion trajectories to resolve ambiguity in perception. Extensive experiments on benchmarked Human3.6M and MPI-3DHP datasets demonstrate state-of-the-art performance across all metrics. To further validate DreamPose3D's robustness, we tested it on a broadcast baseball dataset, where it demonstrated strong performance despite ambiguous and noisy 2D inputs, effectively handling temporal consistency and intent-driven motion variations.
SAGOnline: Segment Any Gaussians Online
Aug 11, 20253D Gaussian Splatting (3DGS) has emerged as a powerful paradigm for explicit 3D scene representation, yet achieving efficient and consistent 3D segmentation remains challenging. Current methods suffer from prohibitive computational costs, limited 3D spatial reasoning, and an inability to track multiple objects simultaneously. We present Segment Any Gaussians Online (SAGOnline), a lightweight and zero-shot framework for real-time 3D segmentation in Gaussian scenes that addresses these limitations through two key innovations: (1) a decoupled strategy that integrates video foundation models (e.g., SAM2) for view-consistent 2D mask propagation across synthesized views; and (2) a GPU-accelerated 3D mask generation and Gaussian-level instance labeling algorithm that assigns unique identifiers to 3D primitives, enabling lossless multi-object tracking and segmentation across views. SAGOnline achieves state-of-the-art performance on NVOS (92.7% mIoU) and Spin-NeRF (95.2% mIoU) benchmarks, outperforming Feature3DGS, OmniSeg3D-gs, and SA3D by 15--1500 times in inference speed (27 ms/frame). Qualitative results demonstrate robust multi-object segmentation and tracking in complex scenes. Our contributions include: (i) a lightweight and zero-shot framework for 3D segmentation in Gaussian scenes, (ii) explicit labeling of Gaussian primitives enabling simultaneous segmentation and tracking, and (iii) the effective adaptation of 2D video foundation models to the 3D domain. This work allows real-time rendering and 3D scene understanding, paving the way for practical AR/VR and robotic applications.
PointGauss: Point Cloud-Guided Multi-Object Segmentation for Gaussian Splatting
Aug 01, 2025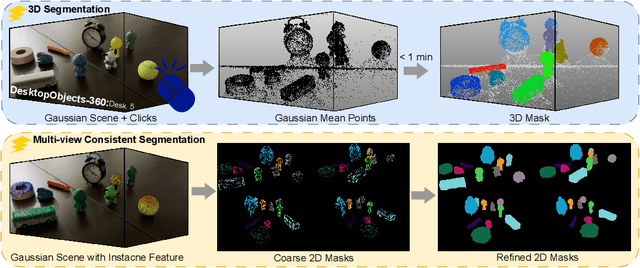
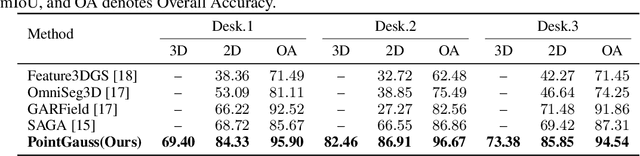
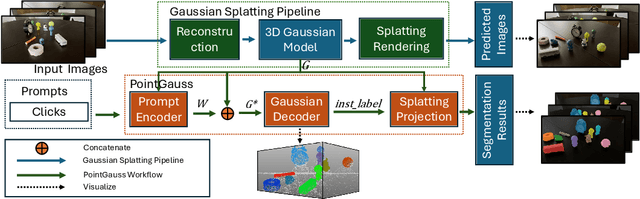
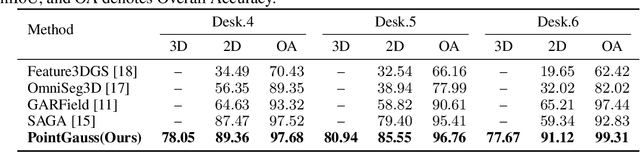
We introduce PointGauss, a novel point cloud-guided framework for real-time multi-object segmentation in Gaussian Splatting representations. Unlike existing methods that suffer from prolonged initialization and limited multi-view consistency, our approach achieves efficient 3D segmentation by directly parsing Gaussian primitives through a point cloud segmentation-driven pipeline. The key innovation lies in two aspects: (1) a point cloud-based Gaussian primitive decoder that generates 3D instance masks within 1 minute, and (2) a GPU-accelerated 2D mask rendering system that ensures multi-view consistency. Extensive experiments demonstrate significant improvements over previous state-of-the-art methods, achieving performance gains of 1.89 to 31.78% in multi-view mIoU, while maintaining superior computational efficiency. To address the limitations of current benchmarks (single-object focus, inconsistent 3D evaluation, small scale, and partial coverage), we present DesktopObjects-360, a novel comprehensive dataset for 3D segmentation in radiance fields, featuring: (1) complex multi-object scenes, (2) globally consistent 2D annotations, (3) large-scale training data (over 27 thousand 2D masks), (4) full 360{\deg} coverage, and (5) 3D evaluation masks.
Complete Autonomous Robotic Nasopharyngeal Swab System with Evaluation on a Stochastically Moving Phantom Head
Aug 23, 2024
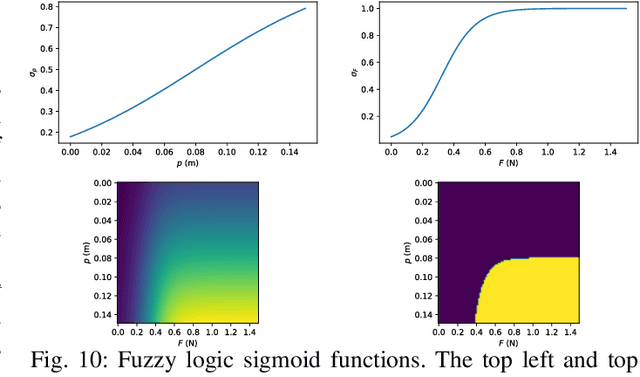


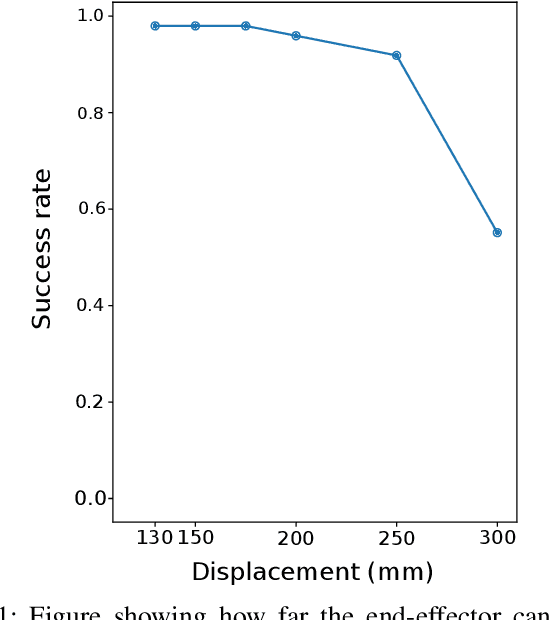
The application of autonomous robotics to close-contact healthcare tasks has a clear role for the future due to its potential to reduce infection risks to staff and improve clinical efficiency. Nasopharyngeal (NP) swab sample collection for diagnosing upper-respiratory illnesses is one type of close contact task that is interesting for robotics due to the dexterity requirements and the unobservability of the nasal cavity. We propose a control system that performs the test using a collaborative manipulator arm with an instrumented end-effector to take visual and force measurements, under the scenario that the patient is unrestrained and the tools are general enough to be applied to other close contact tasks. The system employs a visual servo controller to align the swab with the nostrils. A compliant joint velocity controller inserts the swab along a trajectory optimized through a simulation environment, that also reacts to measured forces applied to the swab. Additional subsystems include a fuzzy logic system for detecting when the swab reaches the nasopharynx and a method for detaching the swab and aborting the procedure if safety criteria is violated. The system is evaluated using a second robotic arm that holds a nasal cavity phantom and simulates the natural head motions that could occur during the procedure. Through extensive experiments, we identify controller configurations capable of effectively performing the NP swab test even with significant head motion, which demonstrates the safety and reliability of the system.
Robotic Eye-in-hand Visual Servo Axially Aligning Nasopharyngeal Swabs with the Nasal Cavity
Aug 22, 2024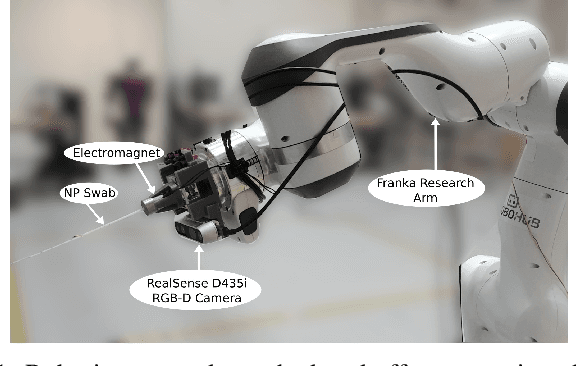
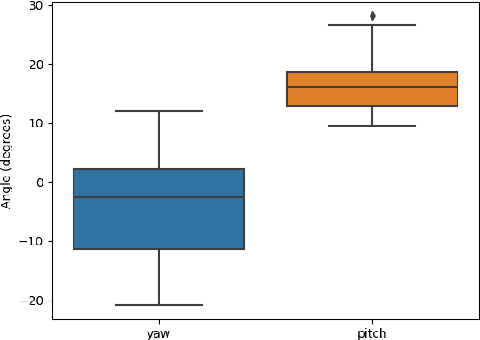

The nasopharyngeal (NP) swab test is a method for collecting cultures to diagnose for different types of respiratory illnesses, including COVID-19. Delegating this task to robots would be beneficial in terms of reducing infection risks and bolstering the healthcare system, but a critical component of the NP swab test is having the swab aligned properly with the nasal cavity so that it does not cause excessive discomfort or injury by traveling down the wrong passage. Existing research towards robotic NP swabbing typically assumes the patient's head is held within a fixture. This simplifies the alignment problem, but is also dissimilar to clinical scenarios where patients are typically free-standing. Consequently, our work creates a vision-guided pipeline to allow an instrumented robot arm to properly position and orient NP swabs with respect to the nostrils of free-standing patients. The first component of the pipeline is a precomputed joint lookup table to allow the arm to meet the patient's arbitrary position in the designated workspace, while avoiding joint limits. Our pipeline leverages semantic face models from computer vision to estimate the Euclidean pose of the face with respect to a monocular RGB-D camera placed on the end-effector. These estimates are passed into an unscented Kalman filter on manifolds state estimator and a pose based visual servo control loop to move the swab to the designated pose in front of the nostril. Our pipeline was validated with human trials, featuring a cohort of 25 participants. The system is effective, reaching the nostril for 84% of participants, and our statistical analysis did not find significant demographic biases within the cohort.
Collaborative Robot Arm Inserting Nasopharyngeal Swabs with Admittance Control
Aug 21, 2024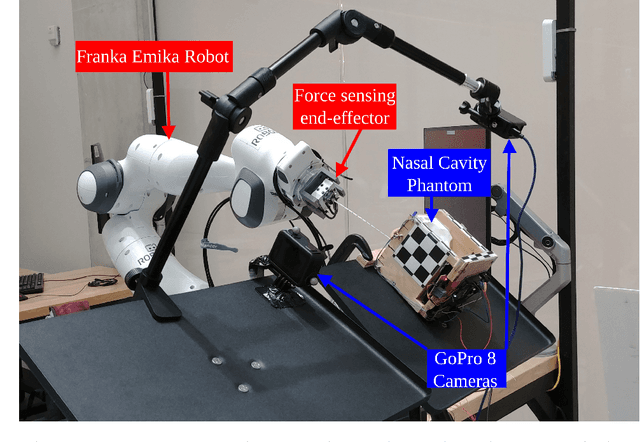
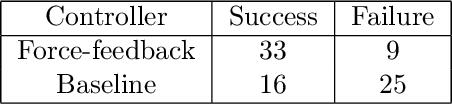
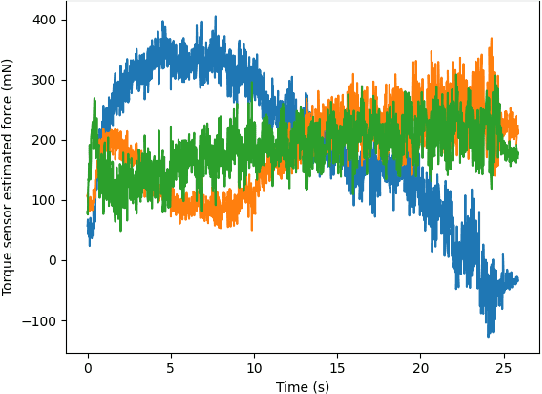

The nasopharyngeal (NP) swab sample test, commonly used to detect COVID-19 and other respiratory illnesses, involves moving a swab through the nasal cavity to collect samples from the nasopharynx. While typically this is done by human healthcare workers, there is a significant societal interest to enable robots to do this test to reduce exposure to patients and to free up human resources. The task is challenging from the robotics perspective because of the dexterity and safety requirements. While other works have implemented specific hardware solutions, our research differentiates itself by using a ubiquitous rigid robotic arm. This work presents a case study where we investigate the strengths and challenges using compliant control system to accomplish NP swab tests with such a robotic configuration. To accomplish this, we designed a force sensing end-effector that integrates with the proposed torque controlled compliant control loop. We then conducted experiments where the robot inserted NP swabs into a 3D printed nasal cavity phantom. Ultimately, we found that the compliant control system outperformed a basic position controller and shows promise for human use. However, further efforts are needed to ensure the initial alignment with the nostril and to address head motion.