 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating deep tracking models for player tracking in broadcast ice hockey video
May 22, 2022
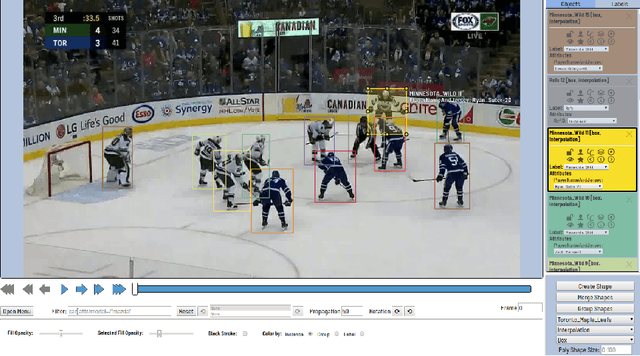

Tracking and identifying players is an important problem in computer vision based ice hockey analytics. Player tracking is a challenging problem since the motion of players in hockey is fast-paced and non-linear. There is also significant player-player and player-board occlusion, camera panning and zooming in hockey broadcast video. Prior published research perform player tracking with the help of handcrafted features for player detection and re-identification. Although commercial solutions for hockey player tracking exist, to the best of our knowledge, no network architectures used, training data or performance metrics are publicly reported. There is currently no published work for hockey player tracking making use of the recent advancements in deep learning while also reporting the current accuracy metrics used in literature. Therefore, in this paper, we compare and contrast several state-of-the-art tracking algorithms and analyze their performance and failure modes in ice hockey.
Ice hockey player identification via transformers
Nov 22, 2021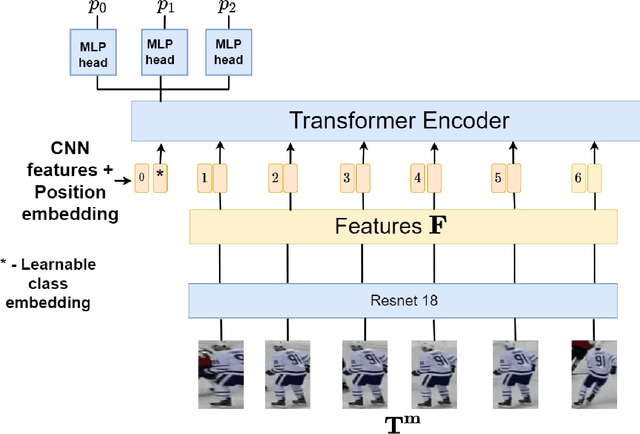
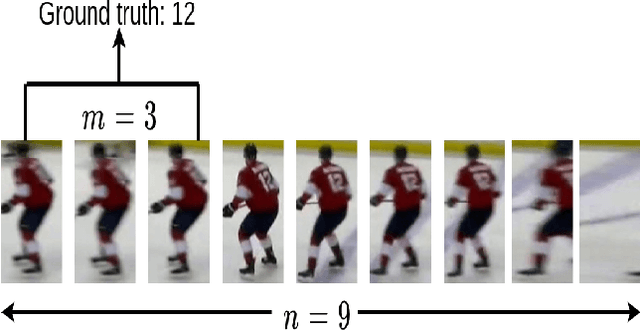
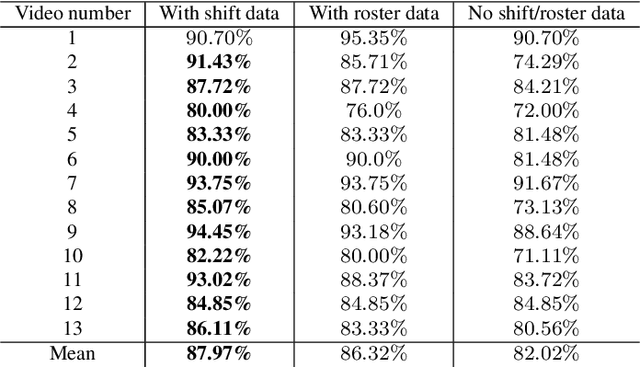
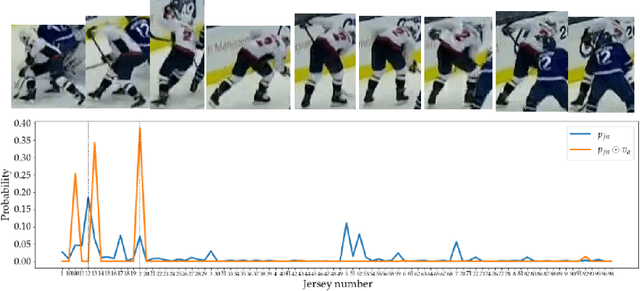
Identifying players in video is a foundational step in computer vision-based sports analytics. Obtaining player identities is essential for analyzing the game and is used in downstream tasks such as game event recognition. Transformers are the existing standard in Natural Language Processing (NLP) and are swiftly gaining traction in computer vision. Motivated by the increasing success of transformers in computer vision, in this paper, we introduce a transformer network for recognizing players through their jersey numbers in broadcast National Hockey League (NHL) videos. The transformer takes temporal sequences of player frames (also called player tracklets) as input and outputs the probabilities of jersey numbers present in the frames. The proposed network performs better than the previous benchmark on the dataset used. We implement a weakly-supervised training approach by generating approximate frame-level labels for jersey number presence and use the frame-level labels for faster training. We also utilize player shifts available in the NHL play-by-play data by reading the game time using optical character recognition (OCR) to get the players on the ice rink at a certain game time. Using player shifts improved the player identification accuracy by 6%.
Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation
Nov 17, 2021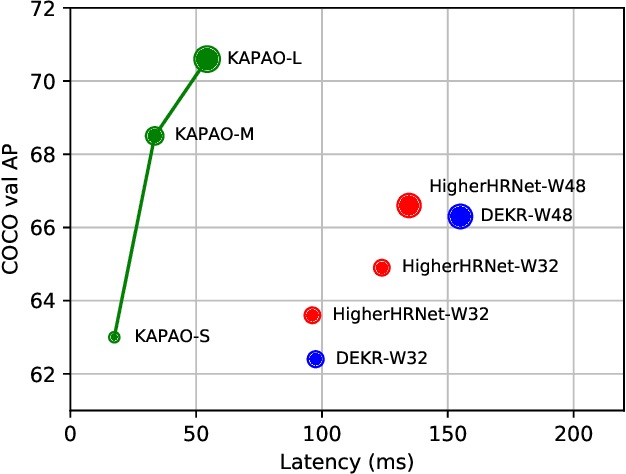

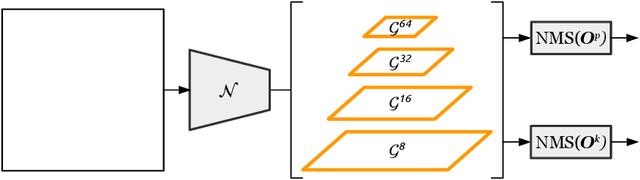
In keypoint estimation tasks such as human pose estimation, heatmap-based regression is the dominant approach despite possessing notable drawbacks: heatmaps intrinsically suffer from quantization error and require excessive computation to generate and post-process. Motivated to find a more efficient solution, we propose a new heatmap-free keypoint estimation method in which individual keypoints and sets of spatially related keypoints (i.e., poses) are modeled as objects within a dense single-stage anchor-based detection framework. Hence, we call our method KAPAO (pronounced "Ka-Pow!") for Keypoints And Poses As Objects. We apply KAPAO to the problem of single-stage multi-person human pose estimation by simultaneously detecting human pose objects and keypoint objects and fusing the detections to exploit the strengths of both object representations. In experiments, we observe that KAPAO is significantly faster and more accurate than previous methods, which suffer greatly from heatmap post-processing. Moreover, the accuracy-speed trade-off is especially favourable in the practical setting when not using test-time augmentation. Our large model, KAPAO-L, achieves an AP of 70.6 on the Microsoft COCO Keypoints validation set without test-time augmentation while being 2.5x faster than the next best single-stage model, whose accuracy is 4.0 AP less. Furthermore, KAPAO excels in the presence of heavy occlusion. On the CrowdPose test set, KAPAO-L achieves new state-of-the-art accuracy for a single-stage method with an AP of 68.9.
Player Tracking and Identification in Ice Hockey
Oct 06, 2021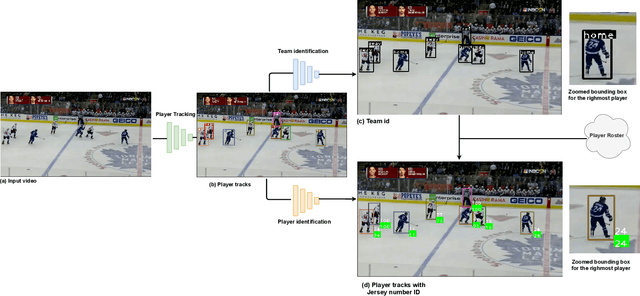
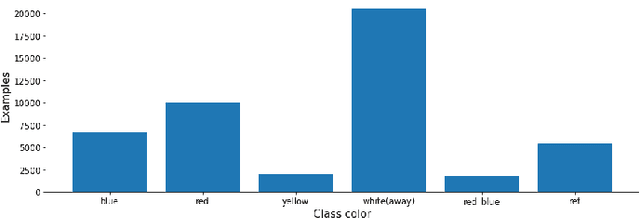
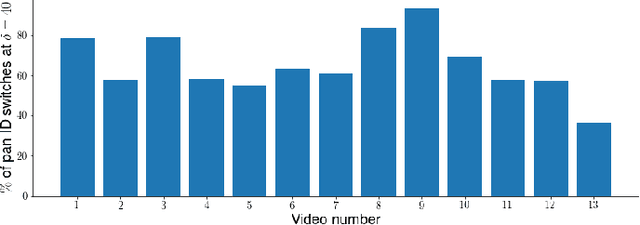
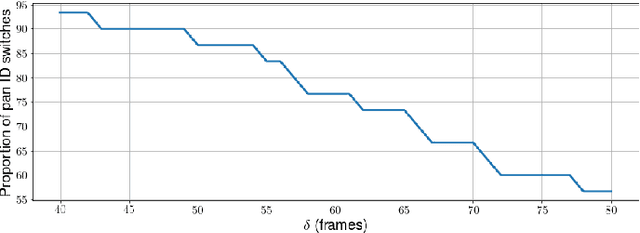
Tracking and identifying players is a fundamental step in computer vision-based ice hockey analytics. The data generated by tracking is used in many other downstream tasks, such as game event detection and game strategy analysis. Player tracking and identification is a challenging problem since the motion of players in hockey is fast-paced and non-linear when compared to pedestrians. There is also significant camera panning and zooming in hockey broadcast video. Identifying players in ice hockey is challenging since the players of the same team look almost identical, with the jersey number the only discriminating factor between players. In this paper, an automated system to track and identify players in broadcast NHL hockey videos is introduced. The system is composed of three components (1) Player tracking, (2) Team identification and (3) Player identification. Due to the absence of publicly available datasets, the datasets used to train the three components are annotated manually. Player tracking is performed with the help of a state of the art tracking algorithm obtaining a Multi-Object Tracking Accuracy (MOTA) score of 94.5%. For team identification, the away-team jerseys are grouped into a single class and home-team jerseys are grouped in classes according to their jersey color. A convolutional neural network is then trained on the team identification dataset. The team identification network gets an accuracy of 97% on the test set. A novel player identification model is introduced that utilizes a temporal one-dimensional convolutional network to identify players from player bounding box sequences. The player identification model further takes advantage of the available NHL game roster data to obtain a player identification accuracy of 83%.
Multi-task learning for jersey number recognition in Ice Hockey
Aug 17, 2021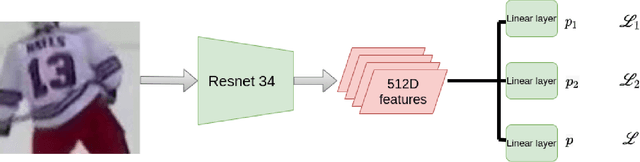

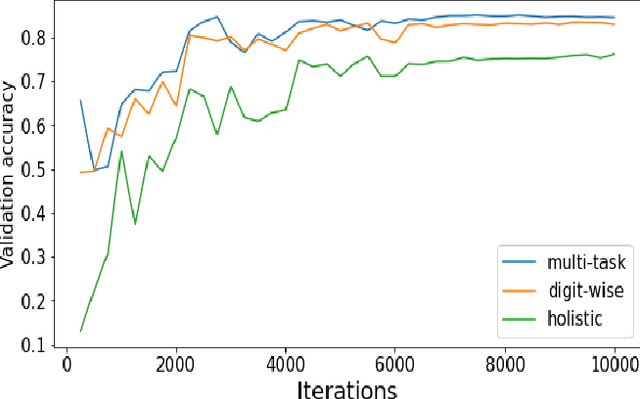

Identifying players in sports videos by recognizing their jersey numbers is a challenging task in computer vision. We have designed and implemented a multi-task learning network for jersey number recognition. In order to train a network to recognize jersey numbers, two output label representations are used (1) Holistic - considers the entire jersey number as one class, and (2) Digit-wise - considers the two digits in a jersey number as two separate classes. The proposed network learns both holistic and digit-wise representations through a multi-task loss function. We determine the optimal weights to be assigned to holistic and digit-wise losses through an ablation study. Experimental results demonstrate that the proposed multi-task learning network performs better than the constituent holistic and digit-wise single-task learning networks.
Puck localization and multi-task event recognition in broadcast hockey videos
May 21, 2021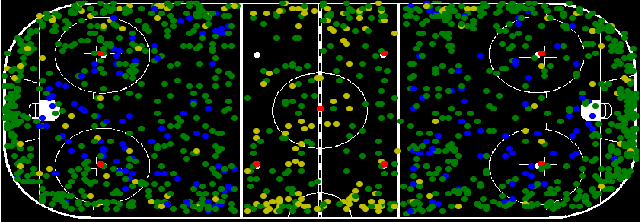

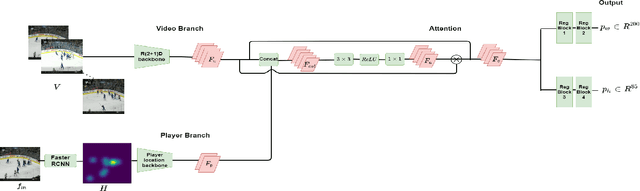

Puck localization is an important problem in ice hockey video analytics useful for analyzing the game, determining play location, and assessing puck possession. The problem is challenging due to the small size of the puck, excessive motion blur due to high puck velocity and occlusions due to players and boards. In this paper, we introduce and implement a network for puck localization in broadcast hockey video. The network leverages expert NHL play-by-play annotations and uses temporal context to locate the puck. Player locations are incorporated into the network through an attention mechanism by encoding player positions with a Gaussian-based spatial heatmap drawn at player positions. Since event occurrence on the rink and puck location are related, we also perform event recognition by augmenting the puck localization network with an event recognition head and training the network through multi-task learning. Experimental results demonstrate that the network is able to localize the puck with an AUC of $73.1 \%$ on the test set. The puck location can be inferred in 720p broadcast videos at $5$ frames per second. It is also demonstrated that multi-task learning with puck location improves event recognition accuracy.
DeepDarts: Modeling Keypoints as Objects for Automatic Scorekeeping in Darts using a Single Camera
May 20, 2021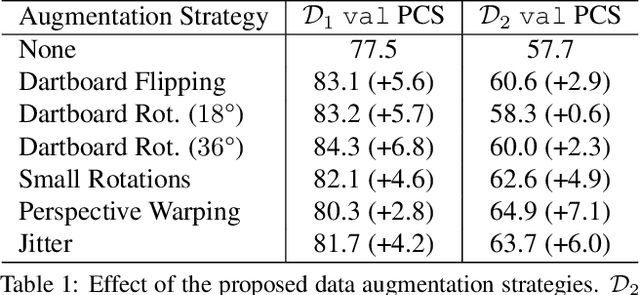


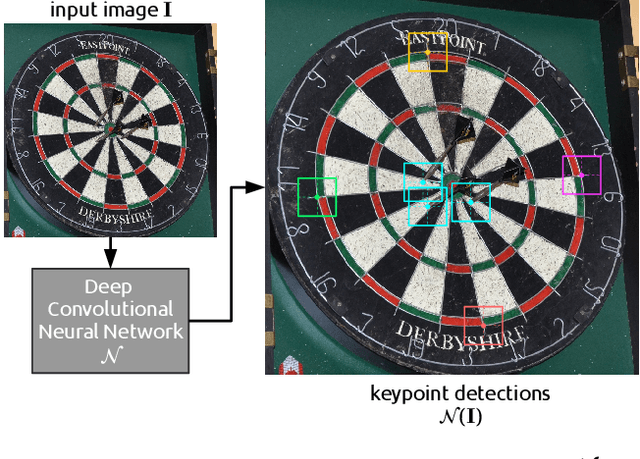
Existing multi-camera solutions for automatic scorekeeping in steel-tip darts are very expensive and thus inaccessible to most players. Motivated to develop a more accessible low-cost solution, we present a new approach to keypoint detection and apply it to predict dart scores from a single image taken from any camera angle. This problem involves detecting multiple keypoints that may be of the same class and positioned in close proximity to one another. The widely adopted framework for regressing keypoints using heatmaps is not well-suited for this task. To address this issue, we instead propose to model keypoints as objects. We develop a deep convolutional neural network around this idea and use it to predict dart locations and dartboard calibration points within an overall pipeline for automatic dart scoring, which we call DeepDarts. Additionally, we propose several task-specific data augmentation strategies to improve the generalization of our method. As a proof of concept, two datasets comprising 16k images originating from two different dartboard setups were manually collected and annotated to evaluate the system. In the primary dataset containing 15k images captured from a face-on view of the dartboard using a smartphone, DeepDarts predicted the total score correctly in 94.7% of the test images. In a second more challenging dataset containing limited training data (830 images) and various camera angles, we utilize transfer learning and extensive data augmentation to achieve a test accuracy of 84.0%. Because DeepDarts relies only on single images, it has the potential to be deployed on edge devices, giving anyone with a smartphone access to an automatic dart scoring system for steel-tip darts. The code and datasets are available.
EvoPose2D: Pushing the Boundaries of 2D Human Pose Estimation using Neuroevolution
Nov 17, 2020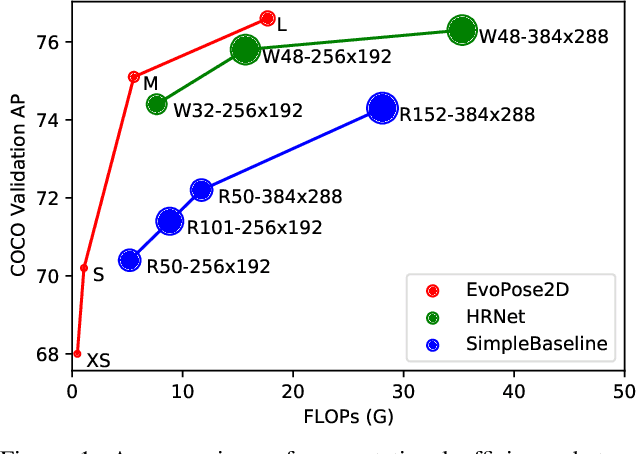
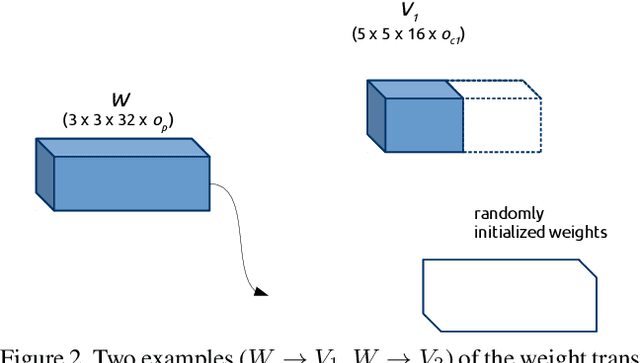
Neural architecture search has proven to be highly effective in the design of computationally efficient, task-specific convolutional neural networks across several areas of computer vision. In 2D human pose estimation, however, its application has been limited by high computational demands. Hypothesizing that neural architecture search holds great potential for 2D human pose estimation, we propose a new weight transfer scheme that relaxes function-preserving mutations, enabling us to accelerate neuroevolution in a flexible manner. Our method produces 2D human pose network designs that are more efficient and more accurate than state-of-the-art hand-designed networks. In fact, the generated networks can process images at higher resolutions using less computation than previous networks at lower resolutions, permitting us to push the boundaries of 2D human pose estimation. Our baseline network designed using neuroevolution, which we refer to as EvoPose2D-S, provides comparable accuracy to SimpleBaseline while using 4.9x fewer floating-point operations and 13.5x fewer parameters. Our largest network, EvoPose2D-L, achieves new state-of-the-art accuracy on the Microsoft COCO Keypoints benchmark while using 2.0x fewer operations and 4.3x fewer parameters than its nearest competitor.
Event detection in coarsely annotated sports videos via parallel multi receptive field 1D convolutions
Apr 13, 2020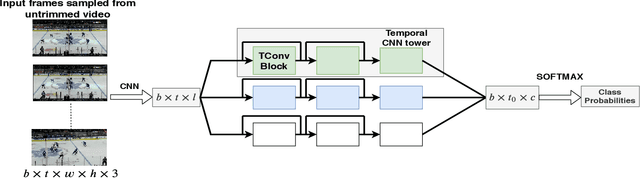



In problems such as sports video analytics, it is difficult to obtain accurate frame level annotations and exact event duration because of the lengthy videos and sheer volume of video data. This issue is even more pronounced in fast-paced sports such as ice hockey. Obtaining annotations on a coarse scale can be much more practical and time efficient. We propose the task of event detection in coarsely annotated videos. We introduce a multi-tower temporal convolutional network architecture for the proposed task. The network, with the help of multiple receptive fields, processes information at various temporal scales to account for the uncertainty with regard to the exact event location and duration. We demonstrate the effectiveness of the multi-receptive field architecture through appropriate ablation studies. The method is evaluated on two tasks - event detection in coarsely annotated hockey videos in the NHL dataset and event spotting in soccer on the SoccerNet dataset. The two datasets lack frame-level annotations and have very distinct event frequencies. Experimental results demonstrate the effectiveness of the network by obtaining a 55% average F1 score on the NHL dataset and by achieving competitive performance compared to the state of the art on the SoccerNet dataset. We believe our approach will help develop more practical pipelines for event detection in sports video.
PuckNet: Estimating hockey puck location from broadcast video
Dec 11, 2019

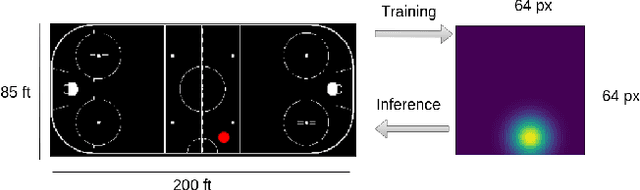
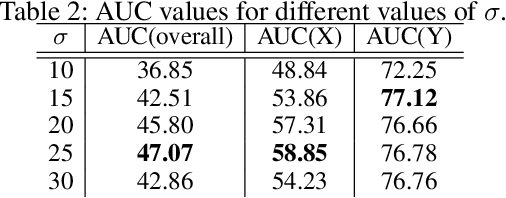
Puck location in ice hockey is essential for hockey analysts for determining the location of play and analyzing game events. However, because of the difficulty involved in obtaining accurate annotations due to the extremely low visibility and commonly occurring occlusions of the puck, the problem is very challenging. The problem becomes even more challenging in broadcast videos with changing camera angles. We introduce a novel methodology for determining puck location from approximate puck location annotations in broadcast video. Our method uniquely leverages the existing puck location information that is publicly available in existing hockey event data and uses the corresponding one-second broadcast video clips as input to the network. The rationale behind using video as input instead of static images is that with video, the temporal information can be utilized to handle puck occlusions. The network outputs a heatmap representing the probability of the puck location using a 3D CNN based architecture. The network is able to regress the puck location from broadcast hockey video clips with varying camera angles. Experimental results demonstrate the capability of the method, achieving 47.07% AUC on the test dataset. The network is also able to estimate the puck location in defensive/offensive zones with an accuracy of greater than 80%.