 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApple Intelligence Foundation Language Models
Jul 29, 2024



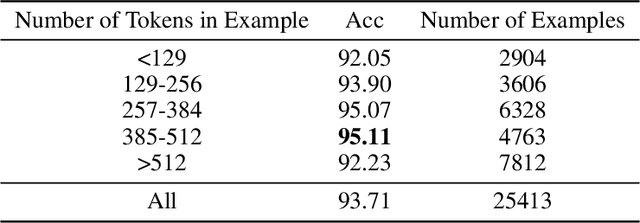
We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Investigating the Impact of Inclusion in Face Recognition Training Data on Individual Face Identification
Jan 10, 2020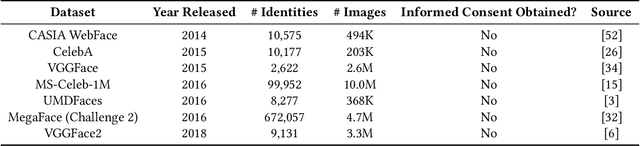
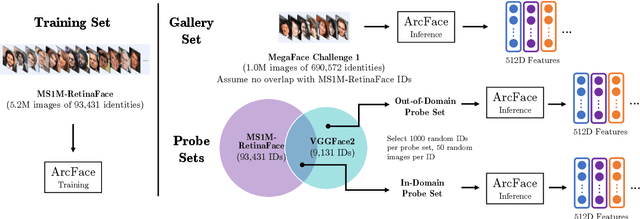
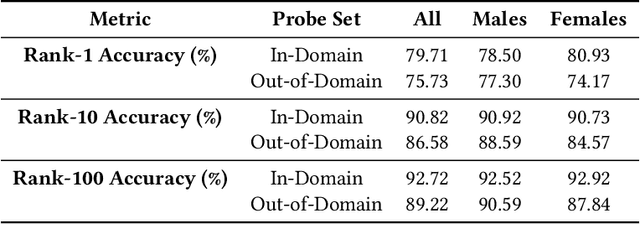
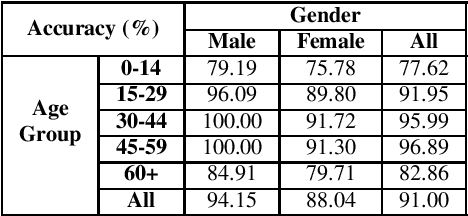
Modern face recognition systems leverage datasets containing images of hundreds of thousands of specific individuals' faces to train deep convolutional neural networks to learn an embedding space that maps an arbitrary individual's face to a vector representation of their identity. The performance of a face recognition system in face verification (1:1) and face identification (1:N) tasks is directly related to the ability of an embedding space to discriminate between identities. Recently, there has been significant public scrutiny into the source and privacy implications of large-scale face recognition training datasets such as MS-Celeb-1M and MegaFace, as many people are uncomfortable with their face being used to train dual-use technologies that can enable mass surveillance. However, the impact of an individual's inclusion in training data on a derived system's ability to recognize them has not previously been studied. In this work, we audit ArcFace, a state-of-the-art, open source face recognition system, in a large-scale face identification experiment with more than one million distractor images. We find a Rank-1 face identification accuracy of 79.71% for individuals present in the model's training data and an accuracy of 75.73% for those not present. This modest difference in accuracy demonstrates that face recognition systems using deep learning work better for individuals they are trained on, which has serious privacy implications when one considers all major open source face recognition training datasets do not obtain informed consent from individuals during their collection.
PuckNet: Estimating hockey puck location from broadcast video
Dec 11, 2019

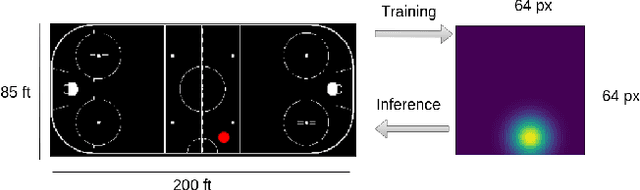
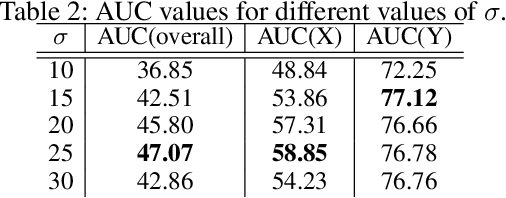
Puck location in ice hockey is essential for hockey analysts for determining the location of play and analyzing game events. However, because of the difficulty involved in obtaining accurate annotations due to the extremely low visibility and commonly occurring occlusions of the puck, the problem is very challenging. The problem becomes even more challenging in broadcast videos with changing camera angles. We introduce a novel methodology for determining puck location from approximate puck location annotations in broadcast video. Our method uniquely leverages the existing puck location information that is publicly available in existing hockey event data and uses the corresponding one-second broadcast video clips as input to the network. The rationale behind using video as input instead of static images is that with video, the temporal information can be utilized to handle puck occlusions. The network outputs a heatmap representing the probability of the puck location using a 3D CNN based architecture. The network is able to regress the puck location from broadcast hockey video clips with varying camera angles. Experimental results demonstrate the capability of the method, achieving 47.07% AUC on the test dataset. The network is also able to estimate the puck location in defensive/offensive zones with an accuracy of greater than 80%.
Taking a Stance on Fake News: Towards Automatic Disinformation Assessment via Deep Bidirectional Transformer Language Models for Stance Detection
Nov 27, 2019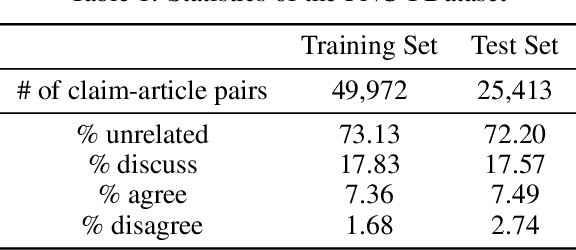
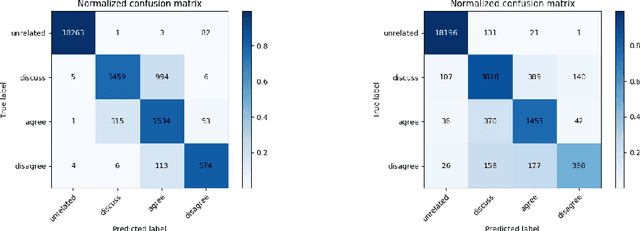
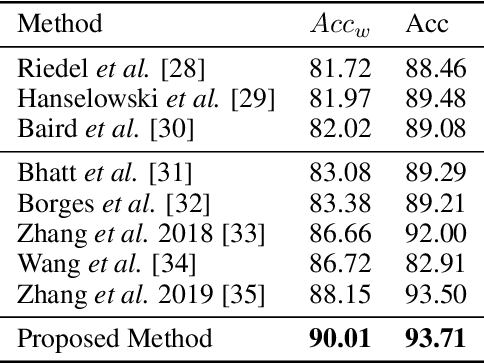
The exponential rise of social media and digital news in the past decade has had the unfortunate consequence of escalating what the United Nations has called a global topic of concern: the growing prevalence of disinformation. Given the complexity and time-consuming nature of combating disinformation through human assessment, one is motivated to explore harnessing AI solutions to automatically assess news articles for the presence of disinformation. A valuable first step towards automatic identification of disinformation is stance detection, where given a claim and a news article, the aim is to predict if the article agrees, disagrees, takes no position, or is unrelated to the claim. Existing approaches in literature have largely relied on hand-engineered features or shallow learned representations (e.g., word embeddings) to encode the claim-article pairs, which can limit the level of representational expressiveness needed to tackle the high complexity of disinformation identification. In this work, we explore the notion of harnessing large-scale deep bidirectional transformer language models for encoding claim-article pairs in an effort to construct state-of-the-art stance detection geared for identifying disinformation. Taking advantage of bidirectional cross-attention between claim-article pairs via pair encoding with self-attention, we construct a large-scale language model for stance detection by performing transfer learning on a RoBERTa deep bidirectional transformer language model, and were able to achieve state-of-the-art performance (weighted accuracy of 90.01%) on the Fake News Challenge Stage 1 (FNC-I) benchmark. These promising results serve as motivation for harnessing such large-scale language models as powerful building blocks for creating effective AI solutions to combat disinformation.
Auditing ImageNet: Towards a Model-driven Framework for Annotating Demographic Attributes of Large-Scale Image Datasets
Jun 04, 2019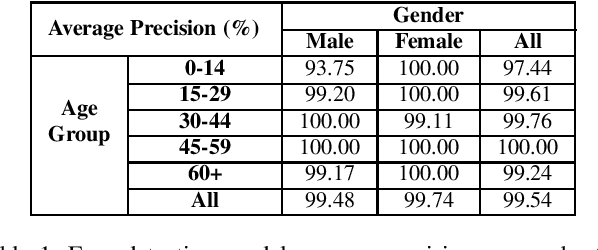
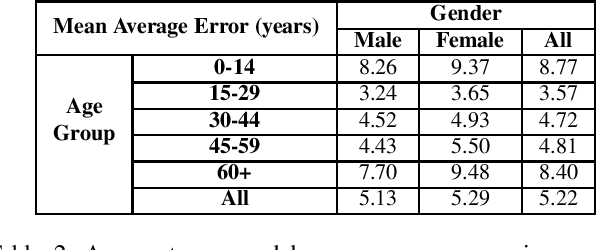
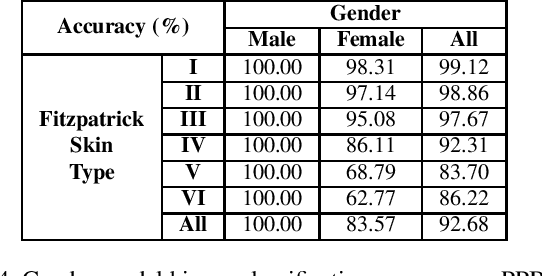
The ImageNet dataset ushered in a flood of academic and industry interest in deep learning for computer vision applications. Despite its significant impact, there has not been a comprehensive investigation into the demographic attributes of images contained within the dataset. Such a study could lead to new insights on inherent biases within ImageNet, particularly important given it is frequently used to pretrain models for a wide variety of computer vision tasks. In this work, we introduce a model-driven framework for the automatic annotation of apparent age and gender attributes in large-scale image datasets. Using this framework, we conduct the first demographic audit of the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) subset of ImageNet and the "person" hierarchical category of ImageNet. We find that 41.62% of faces in ILSVRC appear as female, 1.71% appear as individuals above the age of 60, and males aged 15 to 29 account for the largest subgroup with 27.11%. We note that the presented model-driven framework is not fair for all intersectional groups, so annotation are subject to bias. We present this work as the starting point for future development of unbiased annotation models and for the study of downstream effects of imbalances in the demographics of ImageNet. Code and annotations are available at: http://bit.ly/ImageNetDemoAudit
GolfDB: A Video Database for Golf Swing Sequencing
Mar 15, 2019
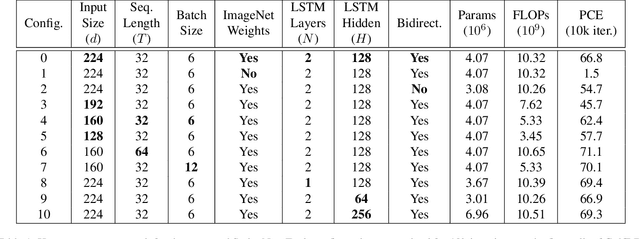


The golf swing is a complex movement requiring considerable full-body coordination to execute proficiently. As such, it is the subject of frequent scrutiny and extensive biomechanical analyses. In this paper, we introduce the notion of golf swing sequencing for detecting key events in the golf swing and facilitating golf swing analysis. To enable consistent evaluation of golf swing sequencing performance, we also introduce the benchmark database GolfDB, consisting of 1400 high-quality golf swing videos, each labeled with event frames, bounding box, player name and sex, club type, and view type. Furthermore, to act as a reference baseline for evaluating golf swing sequencing performance on GolfDB, we propose a lightweight deep neural network called SwingNet, which possesses a hybrid deep convolutional and recurrent neural network architecture. SwingNet correctly detects eight golf swing events at an average rate of 76.1%, and six out of eight events at a rate of 91.8%. In line with the proposed baseline SwingNet, we advocate the use of computationally efficient models in future research to promote in-the-field analysis via deployment on readily-available mobile devices.