 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-SLAM: Hybrid Direct-Indirect Visual SLAM
Jun 12, 2023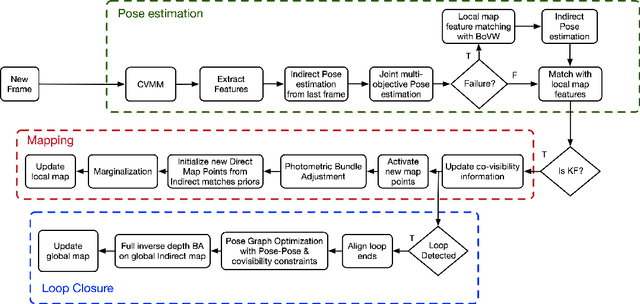
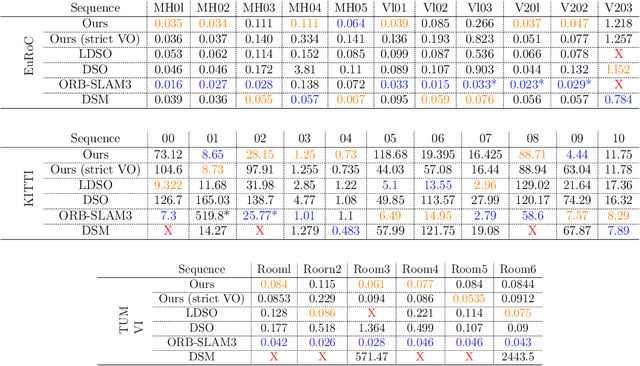


The recent success of hybrid methods in monocular odometry has led to many attempts to generalize the performance gains to hybrid monocular SLAM. However, most attempts fall short in several respects, with the most prominent issue being the need for two different map representations (local and global maps), with each requiring different, computationally expensive, and often redundant processes to maintain. Moreover, these maps tend to drift with respect to each other, resulting in contradicting pose and scene estimates, and leading to catastrophic failure. In this paper, we propose a novel approach that makes use of descriptor sharing to generate a single inverse depth scene representation. This representation can be used locally, queried globally to perform loop closure, and has the ability to re-activate previously observed map points after redundant points are marginalized from the local map, eliminating the need for separate and redundant map maintenance processes. The maps generated by our method exhibit no drift between each other, and can be computed at a fraction of the computational cost and memory footprint required by other monocular SLAM systems. Despite the reduced resource requirements, the proposed approach maintains its robustness and accuracy, delivering performance comparable to state-of-the-art SLAM methods (e.g., LDSO, ORB-SLAM3) on the majority of sequences from well-known datasets like EuRoC, KITTI, and TUM VI. The source code is available at: https://github.com/AUBVRL/fslam_ros_docker.
Arbitrary Shape Text Detection using Transformers
Feb 22, 2022



Recent text detection frameworks require several handcrafted components such as anchor generation, non-maximum suppression (NMS), or multiple processing stages (e.g. label generation) to detect arbitrarily shaped text images. In contrast, we propose an end-to-end trainable architecture based on Detection using Transformers (DETR), that outperforms previous state-of-the-art methods in arbitrary-shaped text detection. At its core, our proposed method leverages a bounding box loss function that accurately measures the arbitrary detected text regions' changes in scale and aspect ratio. This is possible due to a hybrid shape representation made from Bezier curves, that are further split into piece-wise polygons. The proposed loss function is then a combination of a generalized-split-intersection-over-union loss defined over the piece-wise polygons and regularized by a Smooth-$\ln$ regression over the Bezier curve's control points. We evaluate our proposed model using Total-Text and CTW-1500 datasets for curved text, and MSRA-TD500 and ICDAR15 datasets for multi-oriented text, and show that the proposed method outperforms the previous state-of-the-art methods in arbitrary-shape text detection tasks.
Causal Discovery from Sparse Time-Series Data Using Echo State Network
Jan 09, 2022


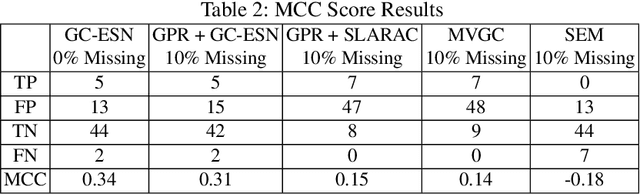
Causal discovery between collections of time-series data can help diagnose causes of symptoms and hopefully prevent faults before they occur. However, reliable causal discovery can be very challenging, especially when the data acquisition rate varies (i.e., non-uniform data sampling), or in the presence of missing data points (e.g., sparse data sampling). To address these issues, we proposed a new system comprised of two parts, the first part fills missing data with a Gaussian Process Regression, and the second part leverages an Echo State Network, which is a type of reservoir computer (i.e., used for chaotic system modeling) for Causal discovery. We evaluate the performance of our proposed system against three other off-the-shelf causal discovery algorithms, namely, structural expectation-maximization, sub-sampled linear auto-regression absolute coefficients, and multivariate Granger Causality with vector auto-regressive using the Tennessee Eastman chemical dataset; we report on their corresponding Matthews Correlation Coefficient(MCC) and Receiver Operating Characteristic curves (ROC) and show that the proposed system outperforms existing algorithms, demonstrating the viability of our approach to discover causal relationships in a complex system with missing entries.
HEMELB Acceleration and Visualization for Cerebral Aneurysms
Jun 27, 2019
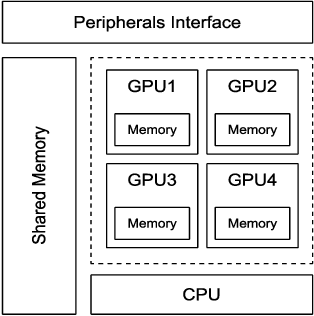
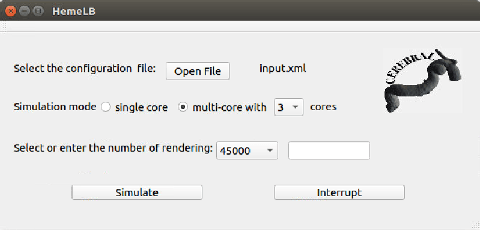
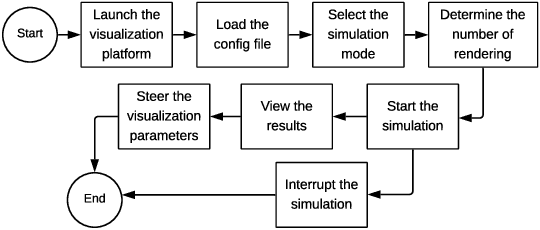
A weakness in the wall of a cerebral artery causing a dilation or ballooning of the blood vessel is known as a cerebral aneurysm. Optimal treatment requires fast and accurate diagnosis of the aneurysm. HemeLB is a fluid dynamics solver for complex geometries developed to provide neurosurgeons with information related to the flow of blood in and around aneurysms. On a cost efficient platform, HemeLB could be employed in hospitals to provide surgeons with the simulation results in real-time. In this work, we developed an improved version of HemeLB for GPU implementation and result visualization. A visualization platform for smooth interaction with end users is also presented. Finally, a comprehensive evaluation of this implementation is reported. The results demonstrate that the proposed implementation achieves a maximum performance of 15,168,964 site updates per second, and is capable of speeding up HemeLB for deployment in hospitals and clinical investigations.
A Unified Formulation for Visual Odometry
Mar 11, 2019
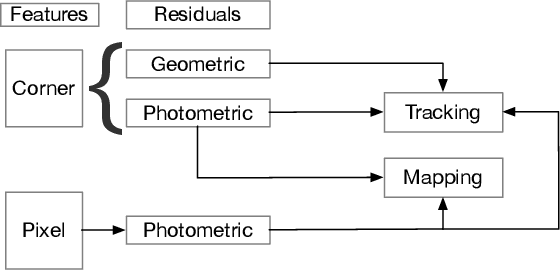
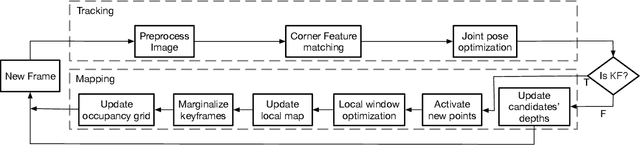

Monocular Odometry systems can be broadly categorized as being either Direct, Indirect, or a hybrid of both. While Indirect systems process an alternative image representation to compute geometric residuals, Direct methods process the image pixels directly to generate photometric residuals. Both paradigms have distinct but often complementary properties. This paper presents a Unified Formulation for Visual Odometry, referred to as UFVO, with the following key contributions: (1) a tight coupling of photometric (Direct) and geometric (Indirect) measurements using a joint multi-objective optimization, (2) the use of a utility function as a decision maker that incorporates prior knowledge on both paradigms, (3) descriptor sharing, where a feature can have more than one type of descriptor and its different descriptors are used for tracking and mapping, (4) the depth estimation of both corner features and pixel features within the same map using an inverse depth parametrization, and (5) a corner and pixel selection strategy that extracts both types of information, while promoting a uniform distribution over the image domain. Experiments show that our proposed system can handle large inter-frame motions, inherits the sub-pixel accuracy of direct methods, can run efficiently in real-time, can generate an Indirect map representation at a marginal computational cost when compared to traditional Indirect systems, all while outperforming state of the art in Direct, Indirect and hybrid systems.
FDMO: Feature Assisted Direct Monocular Odometry
Apr 15, 2018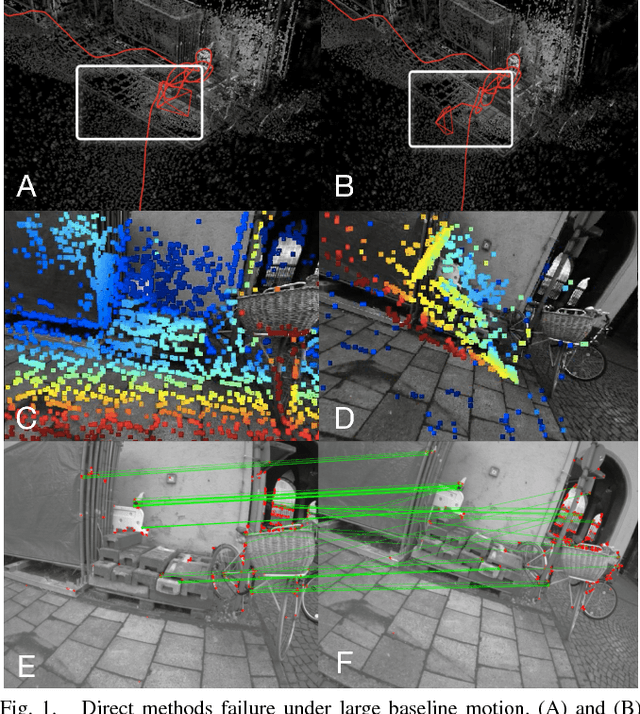
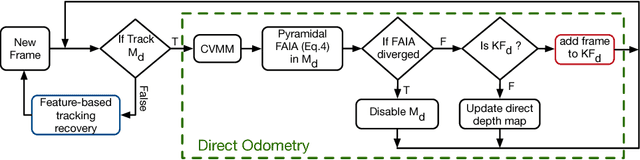
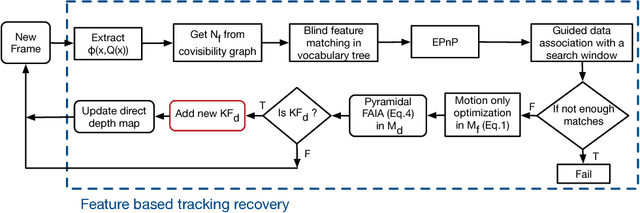
Visual Odometry (VO) can be categorized as being either direct or feature based. When the system is calibrated photometrically, and images are captured at high rates, direct methods have shown to outperform feature-based ones in terms of accuracy and processing time; they are also more robust to failure in feature-deprived environments. On the downside, Direct methods rely on heuristic motion models to seed the estimation of camera motion between frames; in the event that these models are violated (e.g., erratic motion), Direct methods easily fail. This paper proposes a novel system entitled FDMO (Feature assisted Direct Monocular Odometry), which complements the advantages of both direct and featured based techniques. FDMO bootstraps indirect feature tracking upon the sub-pixel accurate localized direct keyframes only when failure modes (e.g., large baselines) of direct tracking occur. Control returns back to direct odometry when these conditions are no longer violated. Efficiencies are introduced to help FDMO perform in real time. FDMO shows significant drift (alignment, rotation & scale) reduction when compared to DSO & ORB SLAM when evaluated using the TumMono and EuroC datasets.
Keyframe-based monocular SLAM: design, survey, and future directions
Jan 07, 2018
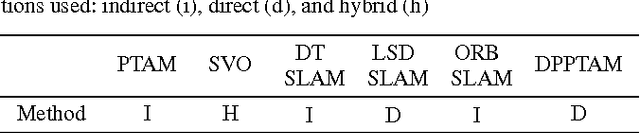
Extensive research in the field of monocular SLAM for the past fifteen years has yielded workable systems that found their way into various applications in robotics and augmented reality. Although filter-based monocular SLAM systems were common at some time, the more efficient keyframe-based solutions are becoming the de facto methodology for building a monocular SLAM system. The objective of this paper is threefold: first, the paper serves as a guideline for people seeking to design their own monocular SLAM according to specific environmental constraints. Second, it presents a survey that covers the various keyframe-based monocular SLAM systems in the literature, detailing the components of their implementation, and critically assessing the specific strategies made in each proposed solution. Third, the paper provides insight into the direction of future research in this field, to address the major limitations still facing monocular SLAM; namely, in the issues of illumination changes, initialization, highly dynamic motion, poorly textured scenes, repetitive textures, map maintenance, and failure recovery.