 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Detection & Recognition in the Wild for Robot Localization
May 19, 2022



Signage is everywhere and a robot should be able to take advantage of signs to help it localize (including Visual Place Recognition (VPR)) and map. Robust text detection & recognition in the wild is challenging due to such factors as pose, irregular text, illumination, and occlusion. We propose an end-to-end scene text spotting model that simultaneously outputs the text string and bounding boxes. This model is more suitable for VPR. Our central contribution is introducing utilizing an end-to-end scene text spotting framework to adequately capture the irregular and occluded text regions in different challenging places. To evaluate our proposed architecture's performance for VPR, we conducted several experiments on the challenging Self-Collected Text Place (SCTP) benchmark dataset. The initial experimental results show that the proposed method outperforms the SOTA methods in terms of precision and recall when tested on this benchmark.
Arbitrary Shape Text Detection using Transformers
Feb 22, 2022



Recent text detection frameworks require several handcrafted components such as anchor generation, non-maximum suppression (NMS), or multiple processing stages (e.g. label generation) to detect arbitrarily shaped text images. In contrast, we propose an end-to-end trainable architecture based on Detection using Transformers (DETR), that outperforms previous state-of-the-art methods in arbitrary-shaped text detection. At its core, our proposed method leverages a bounding box loss function that accurately measures the arbitrary detected text regions' changes in scale and aspect ratio. This is possible due to a hybrid shape representation made from Bezier curves, that are further split into piece-wise polygons. The proposed loss function is then a combination of a generalized-split-intersection-over-union loss defined over the piece-wise polygons and regularized by a Smooth-$\ln$ regression over the Bezier curve's control points. We evaluate our proposed model using Total-Text and CTW-1500 datasets for curved text, and MSRA-TD500 and ICDAR15 datasets for multi-oriented text, and show that the proposed method outperforms the previous state-of-the-art methods in arbitrary-shape text detection tasks.
Text Detection and Recognition in the Wild: A Review
Jun 30, 2020

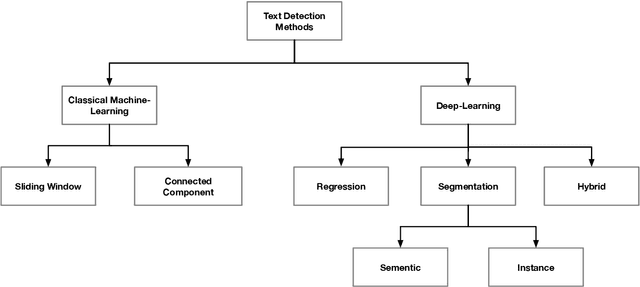

Detection and recognition of text in natural images are two main problems in the field of computer vision that have a wide variety of applications in analysis of sports videos, autonomous driving, industrial automation, to name a few. They face common challenging problems that are factors in how text is represented and affected by several environmental conditions. The current state-of-the-art scene text detection and/or recognition methods have exploited the witnessed advancement in deep learning architectures and reported a superior accuracy on benchmark datasets when tackling multi-resolution and multi-oriented text. However, there are still several remaining challenges affecting text in the wild images that cause existing methods to underperform due to there models are not able to generalize to unseen data and the insufficient labeled data. Thus, unlike previous surveys in this field, the objectives of this survey are as follows: first, offering the reader not only a review on the recent advancement in scene text detection and recognition, but also presenting the results of conducting extensive experiments using a unified evaluation framework that assesses pre-trained models of the selected methods on challenging cases, and applies the same evaluation criteria on these techniques. Second, identifying several existing challenges for detecting or recognizing text in the wild images, namely, in-plane-rotation, multi-oriented and multi-resolution text, perspective distortion, illumination reflection, partial occlusion, complex fonts, and special characters. Finally, the paper also presents insight into the potential research directions in this field to address some of the mentioned challenges that are still encountering scene text detection and recognition techniques.