 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved subsample-and-aggregate via the private modified winsorized mean
Jan 23, 2025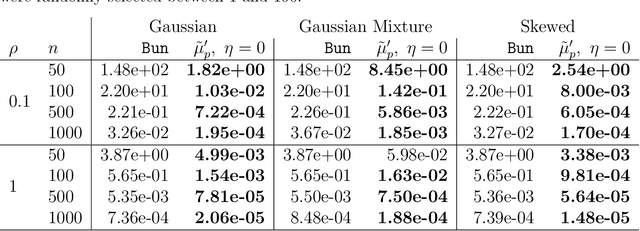
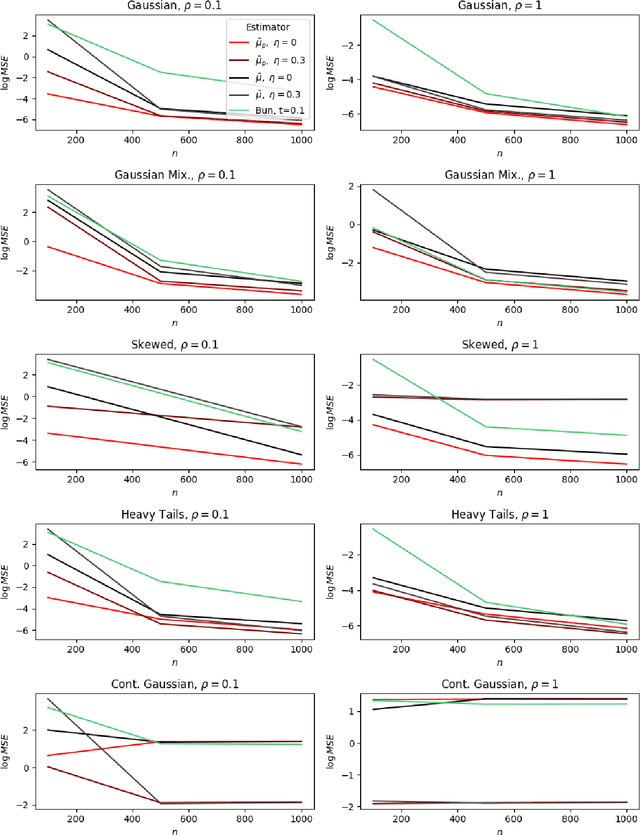

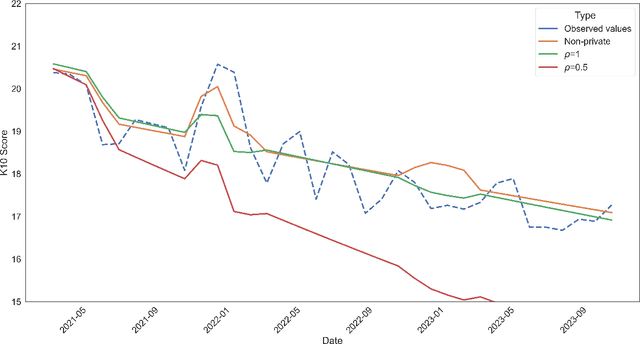
We develop a univariate, differentially private mean estimator, called the private modified winsorized mean designed to be used as the aggregator in subsample-and-aggregate. We demonstrate, via real data analysis, that common differentially private multivariate mean estimators may not perform well as the aggregator, even with a dataset with 8000 observations, motivating our developments. We show that the modified winsorized mean is minimax optimal for several, large classes of distributions, even under adversarial contamination. We also demonstrate that, empirically, the modified winsorized mean performs well compared to other private mean estimates. We consider the modified winsorized mean as the aggregator in subsample-and-aggregate, deriving a finite sample deviations bound for a subsample-and-aggregate estimate generated with the new aggregator. This result yields two important insights: (i) the optimal choice of subsamples depends on the bias of the estimator computed on the subsamples, and (ii) the rate of convergence of the subsample-and-aggregate estimator depends on the robustness of the estimator computed on the subsamples.
Differentially private projection-depth-based medians
Dec 12, 2023
We develop $(\epsilon,\delta)$-differentially private projection-depth-based medians using the propose-test-release (PTR) and exponential mechanisms. Under general conditions on the input parameters and the population measure, (e.g. we do not assume any moment bounds), we quantify the probability the test in PTR fails, as well as the cost of privacy via finite sample deviation bounds. We demonstrate our main result on the canonical projection-depth-based median. In the Gaussian setting, we show that the resulting deviation bound matches the known lower bound for private Gaussian mean estimation, up to a polynomial function of the condition number of the covariance matrix. In the Cauchy setting, we show that the ``outlier error amplification'' effect resulting from the heavy tails outweighs the cost of privacy. This result is then verified via numerical simulations. Additionally, we present results on general PTR mechanisms and a uniform concentration result on the projected spacings of order statistics.
Challenges for Predictive Modeling with Neural Network Techniques using Error-Prone Dietary Intake Data
Nov 15, 2023



Dietary intake data are routinely drawn upon to explore diet-health relationships. However, these data are often subject to measurement error, distorting the true relationships. Beyond measurement error, there are likely complex synergistic and sometimes antagonistic interactions between different dietary components, complicating the relationships between diet and health outcomes. Flexible models are required to capture the nuance that these complex interactions introduce. This complexity makes research on diet-health relationships an appealing candidate for the application of machine learning techniques, and in particular, neural networks. Neural networks are computational models that are able to capture highly complex, nonlinear relationships so long as sufficient data are available. While these models have been applied in many domains, the impacts of measurement error on the performance of predictive modeling has not been systematically investigated. However, dietary intake data are typically collected using self-report methods and are prone to large amounts of measurement error. In this work, we demonstrate the ways in which measurement error erodes the performance of neural networks, and illustrate the care that is required for leveraging these models in the presence of error. We demonstrate the role that sample size and replicate measurements play on model performance, indicate a motivation for the investigation of transformations to additivity, and illustrate the caution required to prevent model overfitting. While the past performance of neural networks across various domains make them an attractive candidate for examining diet-health relationships, our work demonstrates that substantial care and further methodological development are both required to observe increased predictive performance when applying these techniques, compared to more traditional statistical procedures.