 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaFood3D: Large 3D Food Object Dataset with Nutrition Values
Sep 03, 2024
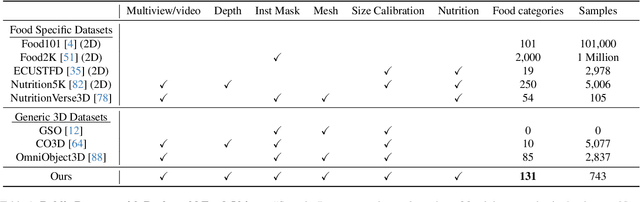
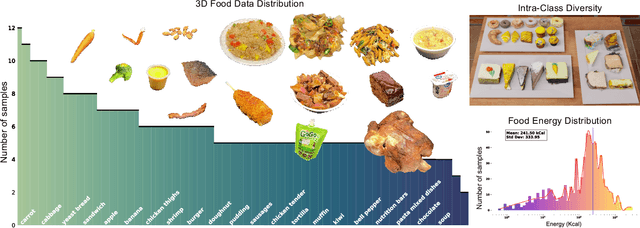
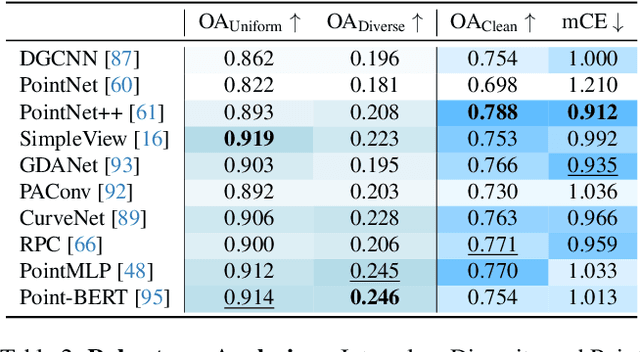
Food computing is both important and challenging in computer vision (CV). It significantly contributes to the development of CV algorithms due to its frequent presence in datasets across various applications, ranging from classification and instance segmentation to 3D reconstruction. The polymorphic shapes and textures of food, coupled with high variation in forms and vast multimodal information, including language descriptions and nutritional data, make food computing a complex and demanding task for modern CV algorithms. 3D food modeling is a new frontier for addressing food-related problems, due to its inherent capability to deal with random camera views and its straightforward representation for calculating food portion size. However, the primary hurdle in the development of algorithms for food object analysis is the lack of nutrition values in existing 3D datasets. Moreover, in the broader field of 3D research, there is a critical need for domain-specific test datasets. To bridge the gap between general 3D vision and food computing research, we propose MetaFood3D. This dataset consists of 637 meticulously labeled 3D food objects across 108 categories, featuring detailed nutrition information, weight, and food codes linked to a comprehensive nutrition database. The dataset emphasizes intra-class diversity and includes rich modalities such as textured mesh files, RGB-D videos, and segmentation masks. Experimental results demonstrate our dataset's significant potential for improving algorithm performance, highlight the challenging gap between video captures and 3D scanned data, and show the strength of the MetaFood3D dataset in high-quality data generation, simulation, and augmentation.
Particle-Filtering-based Latent Diffusion for Inverse Problems
Aug 25, 2024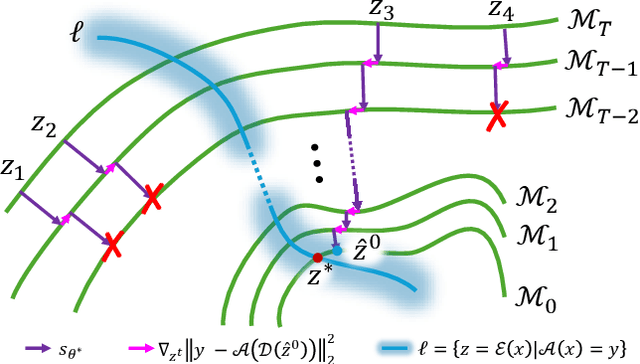
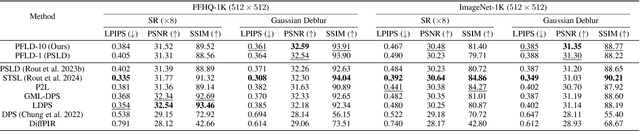
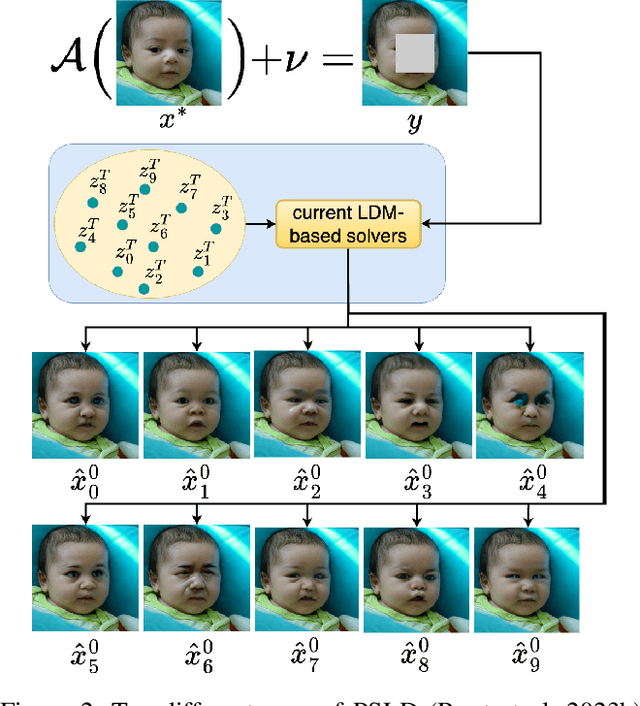

Current strategies for solving image-based inverse problems apply latent diffusion models to perform posterior sampling.However, almost all approaches make no explicit attempt to explore the solution space, instead drawing only a single sample from a Gaussian distribution from which to generate their solution. In this paper, we introduce a particle-filtering-based framework for a nonlinear exploration of the solution space in the initial stages of reverse SDE methods. Our proposed particle-filtering-based latent diffusion (PFLD) method and proposed problem formulation and framework can be applied to any diffusion-based solution for linear or nonlinear inverse problems. Our experimental results show that PFLD outperforms the SoTA solver PSLD on the FFHQ-1K and ImageNet-1K datasets on inverse problem tasks of super resolution, Gaussian debluring and inpainting.
How Much You Ate? Food Portion Estimation on Spoons
May 12, 2024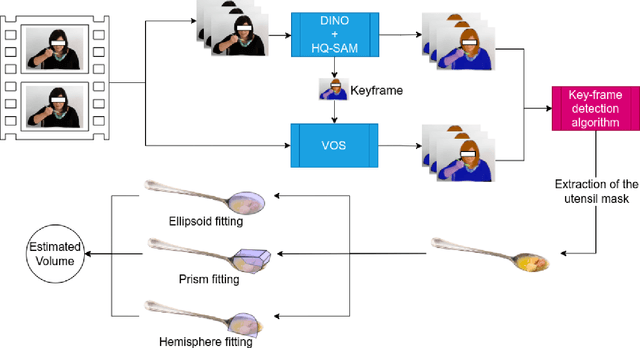
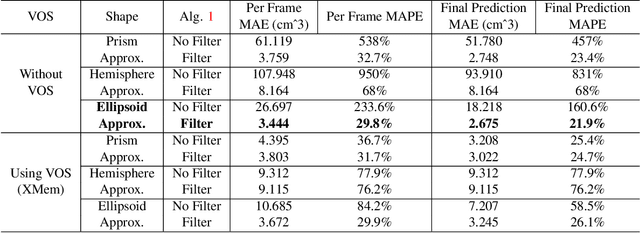

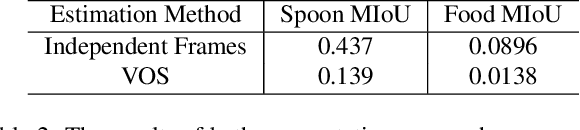
Monitoring dietary intake is a crucial aspect of promoting healthy living. In recent years, advances in computer vision technology have facilitated dietary intake monitoring through the use of images and depth cameras. However, the current state-of-the-art image-based food portion estimation algorithms assume that users take images of their meals one or two times, which can be inconvenient and fail to capture food items that are not visible from a top-down perspective, such as ingredients submerged in a stew. To address these limitations, we introduce an innovative solution that utilizes stationary user-facing cameras to track food items on utensils, not requiring any change of camera perspective after installation. The shallow depth of utensils provides a more favorable angle for capturing food items, and tracking them on the utensil's surface offers a significantly more accurate estimation of dietary intake without the need for post-meal image capture. The system is reliable for estimation of nutritional content of liquid-solid heterogeneous mixtures such as soups and stews. Through a series of experiments, we demonstrate the exceptional potential of our method as a non-invasive, user-friendly, and highly accurate dietary intake monitoring tool.
In The Wild Ellipse Parameter Estimation for Circular Dining Plates and Bowls
May 12, 2024
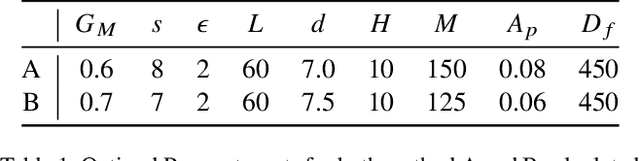
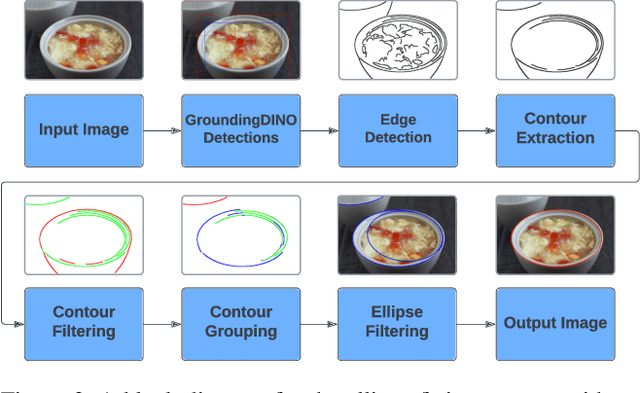
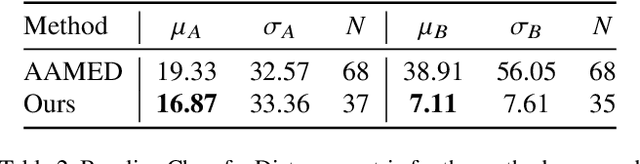
Ellipse estimation is an important topic in food image processing because it can be leveraged to parameterize plates and bowls, which in turn can be used to estimate camera view angles and food portion sizes. Automatically detecting the elliptical rim of plates and bowls and estimating their ellipse parameters for data "in-the-wild" is challenging: diverse camera angles and plate shapes could have been used for capture, noisy background, multiple non-uniform plates and bowls in the image could be present. Recent advancements in foundational models offer promising capabilities for zero-shot semantic understanding and object segmentation. However, the output mask boundaries for plates and bowls generated by these models often lack consistency and precision compared to traditional ellipse fitting methods. In this paper, we combine ellipse fitting with semantic information extracted by zero-shot foundational models and propose WildEllipseFit, a method to detect and estimate the elliptical rim for plate and bowl. Evaluation on the proposed Yummly-ellipse dataset demonstrates its efficacy and zero-shot capability in real-world scenarios.
Double-Condensing Attention Condenser: Leveraging Attention in Deep Learning to Detect Skin Cancer from Skin Lesion Images
Nov 20, 2023Skin cancer is the most common type of cancer in the United States and is estimated to affect one in five Americans. Recent advances have demonstrated strong performance on skin cancer detection, as exemplified by state of the art performance in the SIIM-ISIC Melanoma Classification Challenge; however these solutions leverage ensembles of complex deep neural architectures requiring immense storage and compute costs, and therefore may not be tractable. A recent movement for TinyML applications is integrating Double-Condensing Attention Condensers (DC-AC) into a self-attention neural network backbone architecture to allow for faster and more efficient computation. This paper explores leveraging an efficient self-attention structure to detect skin cancer in skin lesion images and introduces a deep neural network design with DC-AC customized for skin cancer detection from skin lesion images. The final model is publicly available as a part of a global open-source initiative dedicated to accelerating advancement in machine learning to aid clinicians in the fight against cancer.