 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableMotion: Training Motion Cleanup Models with Unpaired Corrupted Data
May 06, 2025
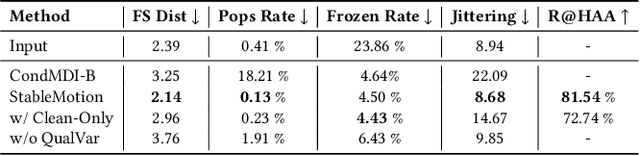
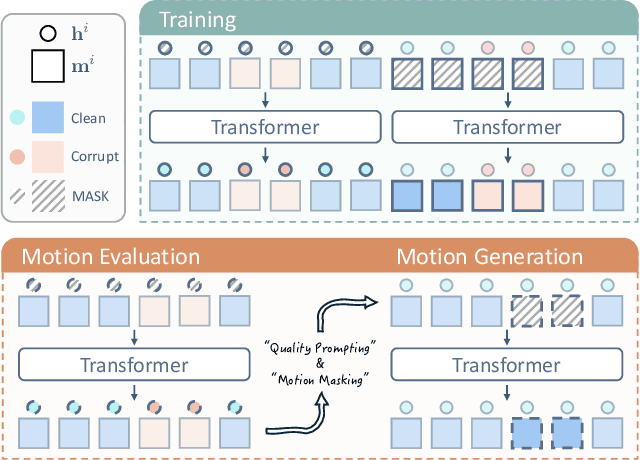
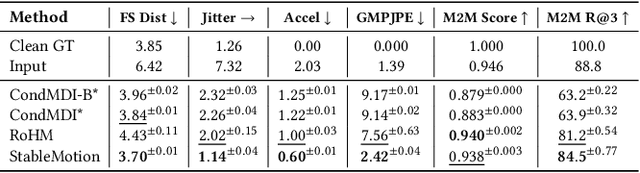
Motion capture (mocap) data often exhibits visually jarring artifacts due to inaccurate sensors and post-processing. Cleaning this corrupted data can require substantial manual effort from human experts, which can be a costly and time-consuming process. Previous data-driven motion cleanup methods offer the promise of automating this cleanup process, but often require in-domain paired corrupted-to-clean training data. Constructing such paired datasets requires access to high-quality, relatively artifact-free motion clips, which often necessitates laborious manual cleanup. In this work, we present StableMotion, a simple yet effective method for training motion cleanup models directly from unpaired corrupted datasets that need cleanup. The core component of our method is the introduction of motion quality indicators, which can be easily annotated through manual labeling or heuristic algorithms and enable training of quality-aware motion generation models on raw motion data with mixed quality. At test time, the model can be prompted to generate high-quality motions using the quality indicators. Our method can be implemented through a simple diffusion-based framework, leading to a unified motion generate-discriminate model, which can be used to both identify and fix corrupted frames. We demonstrate that our proposed method is effective for training motion cleanup models on raw mocap data in production scenarios by applying StableMotion to SoccerMocap, a 245-hour soccer mocap dataset containing real-world motion artifacts. The trained model effectively corrects a wide range of motion artifacts, reducing motion pops and frozen frames by 68% and 81%, respectively. See https://youtu.be/3Y7MMAH02B4 for more results.
MetaFood3D: Large 3D Food Object Dataset with Nutrition Values
Sep 03, 2024
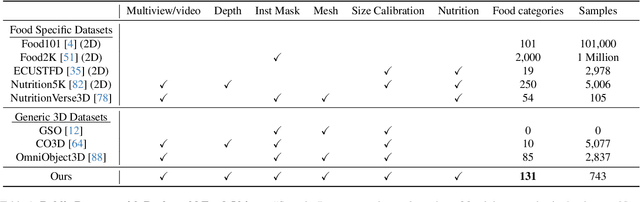
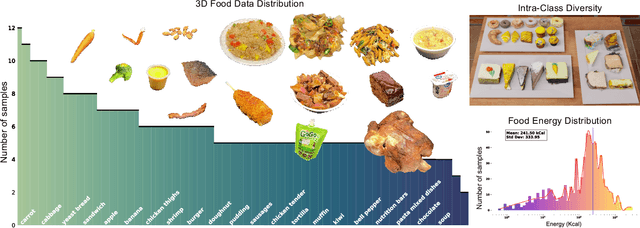
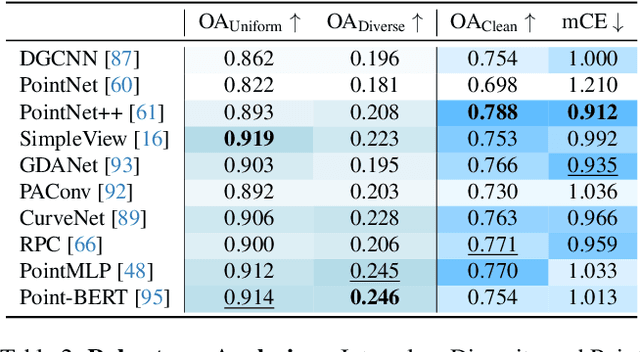
Food computing is both important and challenging in computer vision (CV). It significantly contributes to the development of CV algorithms due to its frequent presence in datasets across various applications, ranging from classification and instance segmentation to 3D reconstruction. The polymorphic shapes and textures of food, coupled with high variation in forms and vast multimodal information, including language descriptions and nutritional data, make food computing a complex and demanding task for modern CV algorithms. 3D food modeling is a new frontier for addressing food-related problems, due to its inherent capability to deal with random camera views and its straightforward representation for calculating food portion size. However, the primary hurdle in the development of algorithms for food object analysis is the lack of nutrition values in existing 3D datasets. Moreover, in the broader field of 3D research, there is a critical need for domain-specific test datasets. To bridge the gap between general 3D vision and food computing research, we propose MetaFood3D. This dataset consists of 637 meticulously labeled 3D food objects across 108 categories, featuring detailed nutrition information, weight, and food codes linked to a comprehensive nutrition database. The dataset emphasizes intra-class diversity and includes rich modalities such as textured mesh files, RGB-D videos, and segmentation masks. Experimental results demonstrate our dataset's significant potential for improving algorithm performance, highlight the challenging gap between video captures and 3D scanned data, and show the strength of the MetaFood3D dataset in high-quality data generation, simulation, and augmentation.
MetaFood CVPR 2024 Challenge on Physically Informed 3D Food Reconstruction: Methods and Results
Jul 12, 2024
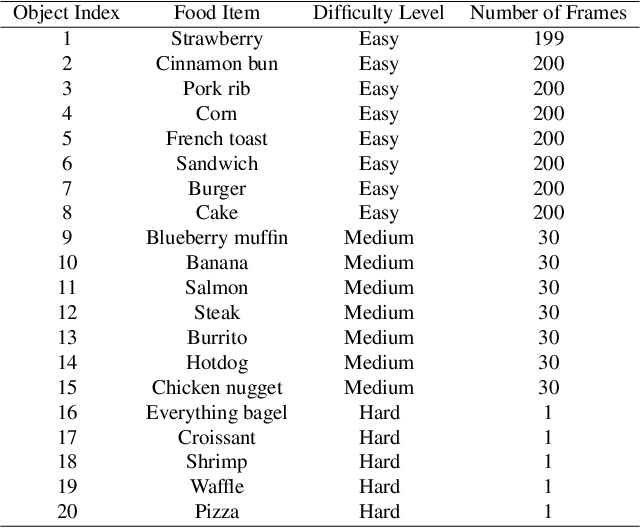
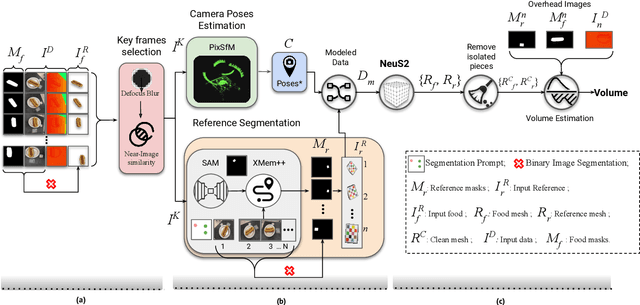
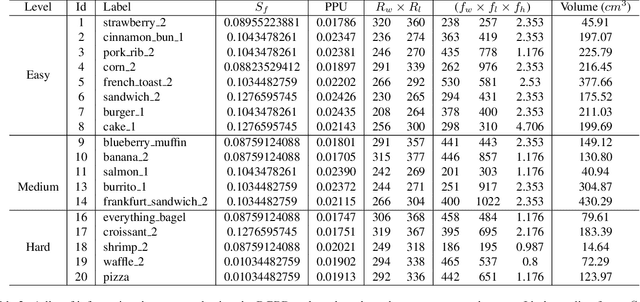
The increasing interest in computer vision applications for nutrition and dietary monitoring has led to the development of advanced 3D reconstruction techniques for food items. However, the scarcity of high-quality data and limited collaboration between industry and academia have constrained progress in this field. Building on recent advancements in 3D reconstruction, we host the MetaFood Workshop and its challenge for Physically Informed 3D Food Reconstruction. This challenge focuses on reconstructing volume-accurate 3D models of food items from 2D images, using a visible checkerboard as a size reference. Participants were tasked with reconstructing 3D models for 20 selected food items of varying difficulty levels: easy, medium, and hard. The easy level provides 200 images, the medium level provides 30 images, and the hard level provides only 1 image for reconstruction. In total, 16 teams submitted results in the final testing phase. The solutions developed in this challenge achieved promising results in 3D food reconstruction, with significant potential for improving portion estimation for dietary assessment and nutritional monitoring. More details about this workshop challenge and access to the dataset can be found at https://sites.google.com/view/cvpr-metafood-2024.
NutritionVerse-Direct: Exploring Deep Neural Networks for Multitask Nutrition Prediction from Food Images
May 13, 2024



Many aging individuals encounter challenges in effectively tracking their dietary intake, exacerbating their susceptibility to nutrition-related health complications. Self-reporting methods are often inaccurate and suffer from substantial bias; however, leveraging intelligent prediction methods can automate and enhance precision in this process. Recent work has explored using computer vision prediction systems to predict nutritional information from food images. Still, these methods are often tailored to specific situations, require other inputs in addition to a food image, or do not provide comprehensive nutritional information. This paper aims to enhance the efficacy of dietary intake estimation by leveraging various neural network architectures to directly predict a meal's nutritional content from its image. Through comprehensive experimentation and evaluation, we present NutritionVerse-Direct, a model utilizing a vision transformer base architecture with three fully connected layers that lead to five regression heads predicting calories (kcal), mass (g), protein (g), fat (g), and carbohydrates (g) present in a meal. NutritionVerse-Direct yields a combined mean average error score on the NutritionVerse-Real dataset of 412.6, an improvement of 25.5% over the Inception-ResNet model, demonstrating its potential for improving dietary intake estimation accuracy.
How Much You Ate? Food Portion Estimation on Spoons
May 12, 2024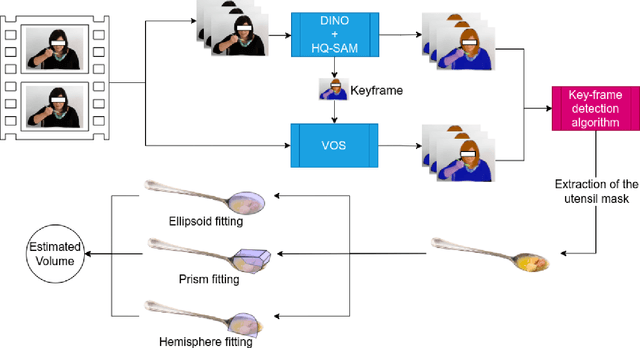
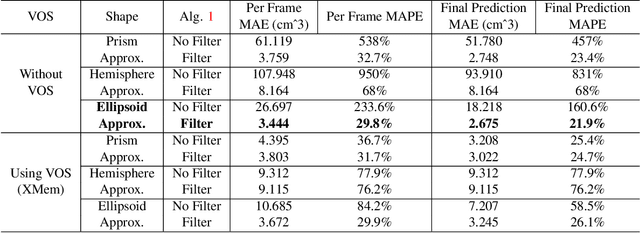

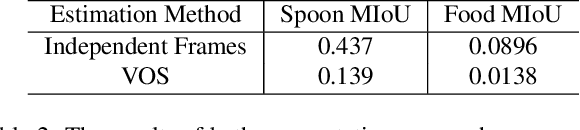
Monitoring dietary intake is a crucial aspect of promoting healthy living. In recent years, advances in computer vision technology have facilitated dietary intake monitoring through the use of images and depth cameras. However, the current state-of-the-art image-based food portion estimation algorithms assume that users take images of their meals one or two times, which can be inconvenient and fail to capture food items that are not visible from a top-down perspective, such as ingredients submerged in a stew. To address these limitations, we introduce an innovative solution that utilizes stationary user-facing cameras to track food items on utensils, not requiring any change of camera perspective after installation. The shallow depth of utensils provides a more favorable angle for capturing food items, and tracking them on the utensil's surface offers a significantly more accurate estimation of dietary intake without the need for post-meal image capture. The system is reliable for estimation of nutritional content of liquid-solid heterogeneous mixtures such as soups and stews. Through a series of experiments, we demonstrate the exceptional potential of our method as a non-invasive, user-friendly, and highly accurate dietary intake monitoring tool.
In The Wild Ellipse Parameter Estimation for Circular Dining Plates and Bowls
May 12, 2024
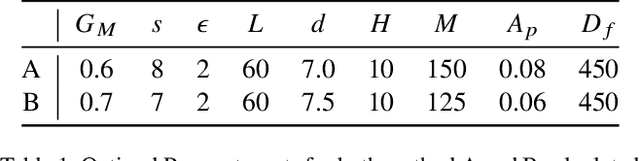
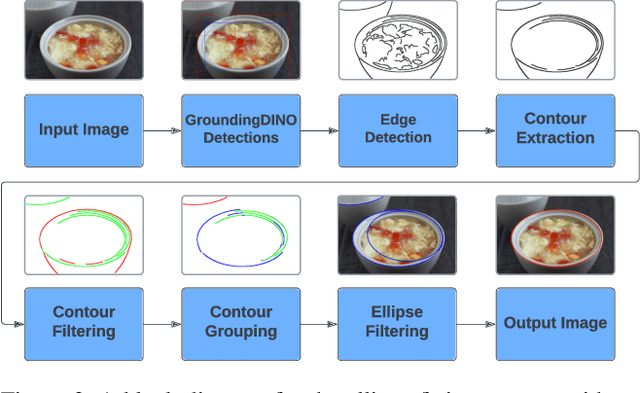
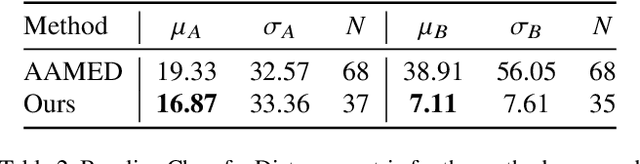
Ellipse estimation is an important topic in food image processing because it can be leveraged to parameterize plates and bowls, which in turn can be used to estimate camera view angles and food portion sizes. Automatically detecting the elliptical rim of plates and bowls and estimating their ellipse parameters for data "in-the-wild" is challenging: diverse camera angles and plate shapes could have been used for capture, noisy background, multiple non-uniform plates and bowls in the image could be present. Recent advancements in foundational models offer promising capabilities for zero-shot semantic understanding and object segmentation. However, the output mask boundaries for plates and bowls generated by these models often lack consistency and precision compared to traditional ellipse fitting methods. In this paper, we combine ellipse fitting with semantic information extracted by zero-shot foundational models and propose WildEllipseFit, a method to detect and estimate the elliptical rim for plate and bowl. Evaluation on the proposed Yummly-ellipse dataset demonstrates its efficacy and zero-shot capability in real-world scenarios.
NutritionVerse: Empirical Study of Various Dietary Intake Estimation Approaches
Sep 14, 2023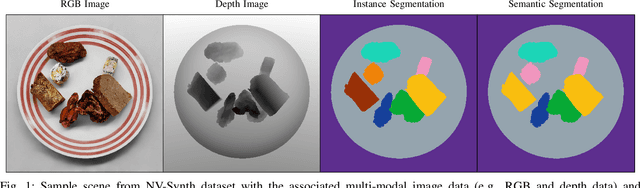



Accurate dietary intake estimation is critical for informing policies and programs to support healthy eating, as malnutrition has been directly linked to decreased quality of life. However self-reporting methods such as food diaries suffer from substantial bias. Other conventional dietary assessment techniques and emerging alternative approaches such as mobile applications incur high time costs and may necessitate trained personnel. Recent work has focused on using computer vision and machine learning to automatically estimate dietary intake from food images, but the lack of comprehensive datasets with diverse viewpoints, modalities and food annotations hinders the accuracy and realism of such methods. To address this limitation, we introduce NutritionVerse-Synth, the first large-scale dataset of 84,984 photorealistic synthetic 2D food images with associated dietary information and multimodal annotations (including depth images, instance masks, and semantic masks). Additionally, we collect a real image dataset, NutritionVerse-Real, containing 889 images of 251 dishes to evaluate realism. Leveraging these novel datasets, we develop and benchmark NutritionVerse, an empirical study of various dietary intake estimation approaches, including indirect segmentation-based and direct prediction networks. We further fine-tune models pretrained on synthetic data with real images to provide insights into the fusion of synthetic and real data. Finally, we release both datasets (NutritionVerse-Synth, NutritionVerse-Real) on https://www.kaggle.com/nutritionverse/datasets as part of an open initiative to accelerate machine learning for dietary sensing.
Transferring Knowledge for Food Image Segmentation using Transformers and Convolutions
Jun 15, 2023Food image segmentation is an important task that has ubiquitous applications, such as estimating the nutritional value of a plate of food. Although machine learning models have been used for segmentation in this domain, food images pose several challenges. One challenge is that food items can overlap and mix, making them difficult to distinguish. Another challenge is the degree of inter-class similarity and intra-class variability, which is caused by the varying preparation methods and dishes a food item may be served in. Additionally, class imbalance is an inevitable issue in food datasets. To address these issues, two models are trained and compared, one based on convolutional neural networks and the other on Bidirectional Encoder representation for Image Transformers (BEiT). The models are trained and valuated using the FoodSeg103 dataset, which is identified as a robust benchmark for food image segmentation. The BEiT model outperforms the previous state-of-the-art model by achieving a mean intersection over union of 49.4 on FoodSeg103. This study provides insights into transfering knowledge using convolution and Transformer-based approaches in the food image domain.
NutritionVerse-Thin: An Optimized Strategy for Enabling Improved Rendering of 3D Thin Food Models
Apr 12, 2023

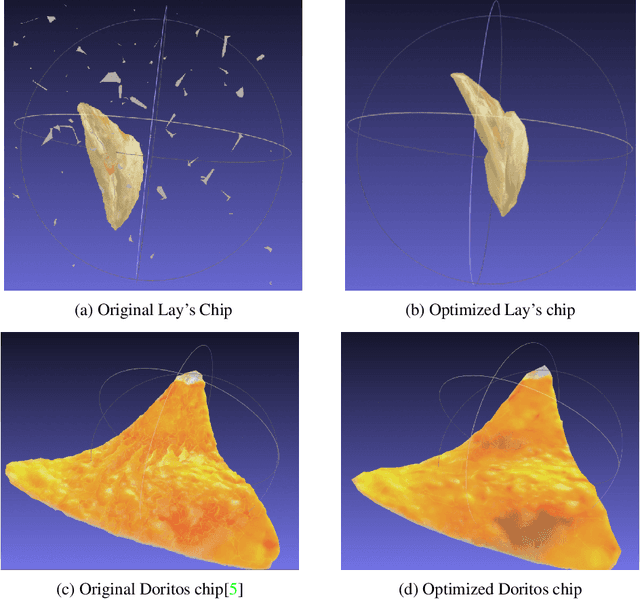

With the growth in capabilities of generative models, there has been growing interest in using photo-realistic renders of common 3D food items to improve downstream tasks such as food printing, nutrition prediction, or management of food wastage. Despite 3D modelling capabilities being more accessible than ever due to the success of NeRF based view-synthesis, such rendering methods still struggle to correctly capture thin food objects, often generating meshes with significant holes. In this study, we present an optimized strategy for enabling improved rendering of thin 3D food models, and demonstrate qualitative improvements in rendering quality. Our method generates the 3D model mesh via a proposed thin-object-optimized differentiable reconstruction method and tailors the strategy at both the data collection and training stages to better handle thin objects. While simple, we find that this technique can be employed for quick and highly consistent capturing of thin 3D objects.
NutritionVerse-3D: A 3D Food Model Dataset for Nutritional Intake Estimation
Apr 12, 2023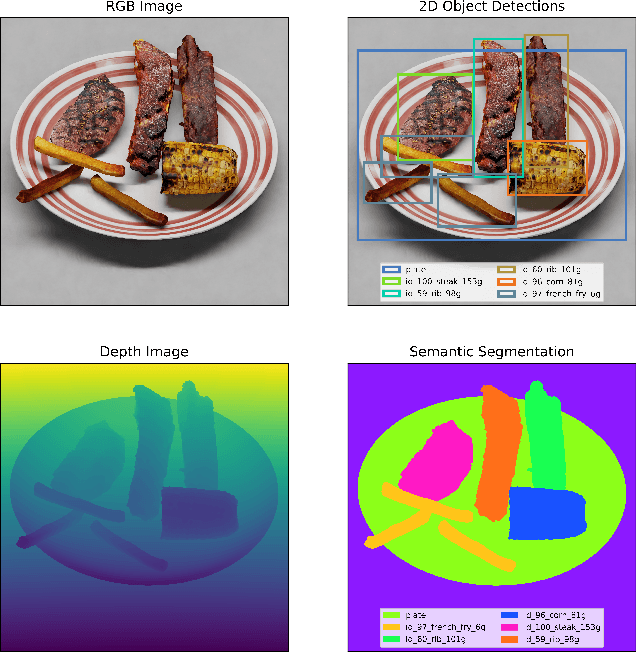
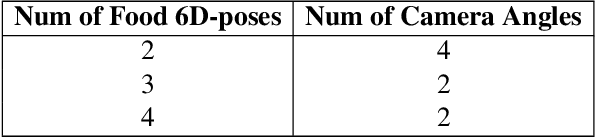


77% of adults over 50 want to age in place today, presenting a major challenge to ensuring adequate nutritional intake. It has been reported that one in four older adults that are 65 years or older are malnourished and given the direct link between malnutrition and decreased quality of life, there have been numerous studies conducted on how to efficiently track nutritional intake of food. Recent advancements in machine learning and computer vision show promise of automated nutrition tracking methods of food, but require a large high-quality dataset in order to accurately identify the nutrients from the food on the plate. Unlike existing datasets, a collection of 3D models with nutritional information allow for view synthesis to create an infinite number of 2D images for any given viewpoint/camera angle along with the associated nutritional information. In this paper, we develop a methodology for collecting high-quality 3D models for food items with a particular focus on speed and consistency, and introduce NutritionVerse-3D, a large-scale high-quality high-resolution dataset of 105 3D food models, in conjunction with their associated weight, food name, and nutritional value. These models allow for large quantity food intake scenes, diverse and customizable scene layout, and an infinite number of camera settings and lighting conditions. NutritionVerse-3D is publicly available as a part of an open initiative to accelerate machine learning for nutrition sensing.