 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
FoodFusion: A Latent Diffusion Model for Realistic Food Image Generation
Dec 06, 2023

Current state-of-the-art image generation models such as Latent Diffusion Models (LDMs) have demonstrated the capacity to produce visually striking food-related images. However, these generated images often exhibit an artistic or surreal quality that diverges from the authenticity of real-world food representations. This inadequacy renders them impractical for applications requiring realistic food imagery, such as training models for image-based dietary assessment. To address these limitations, we introduce FoodFusion, a Latent Diffusion model engineered specifically for the faithful synthesis of realistic food images from textual descriptions. The development of the FoodFusion model involves harnessing an extensive array of open-source food datasets, resulting in over 300,000 curated image-caption pairs. Additionally, we propose and employ two distinct data cleaning methodologies to ensure that the resulting image-text pairs maintain both realism and accuracy. The FoodFusion model, thus trained, demonstrates a remarkable ability to generate food images that exhibit a significant improvement in terms of both realism and diversity over the publicly available image generation models. We openly share the dataset and fine-tuned models to support advancements in this critical field of food image synthesis at https://bit.ly/genai4good.
NutritionVerse: Empirical Study of Various Dietary Intake Estimation Approaches
Sep 14, 2023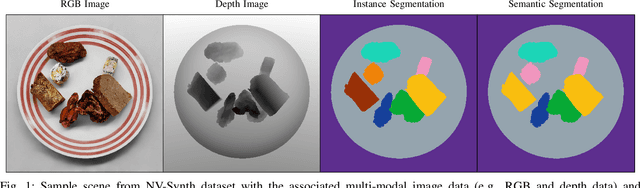



Accurate dietary intake estimation is critical for informing policies and programs to support healthy eating, as malnutrition has been directly linked to decreased quality of life. However self-reporting methods such as food diaries suffer from substantial bias. Other conventional dietary assessment techniques and emerging alternative approaches such as mobile applications incur high time costs and may necessitate trained personnel. Recent work has focused on using computer vision and machine learning to automatically estimate dietary intake from food images, but the lack of comprehensive datasets with diverse viewpoints, modalities and food annotations hinders the accuracy and realism of such methods. To address this limitation, we introduce NutritionVerse-Synth, the first large-scale dataset of 84,984 photorealistic synthetic 2D food images with associated dietary information and multimodal annotations (including depth images, instance masks, and semantic masks). Additionally, we collect a real image dataset, NutritionVerse-Real, containing 889 images of 251 dishes to evaluate realism. Leveraging these novel datasets, we develop and benchmark NutritionVerse, an empirical study of various dietary intake estimation approaches, including indirect segmentation-based and direct prediction networks. We further fine-tune models pretrained on synthetic data with real images to provide insights into the fusion of synthetic and real data. Finally, we release both datasets (NutritionVerse-Synth, NutritionVerse-Real) on https://www.kaggle.com/nutritionverse/datasets as part of an open initiative to accelerate machine learning for dietary sensing.