 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNutritionVerse: Empirical Study of Various Dietary Intake Estimation Approaches
Sep 14, 2023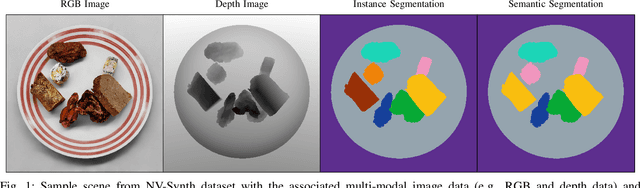



Accurate dietary intake estimation is critical for informing policies and programs to support healthy eating, as malnutrition has been directly linked to decreased quality of life. However self-reporting methods such as food diaries suffer from substantial bias. Other conventional dietary assessment techniques and emerging alternative approaches such as mobile applications incur high time costs and may necessitate trained personnel. Recent work has focused on using computer vision and machine learning to automatically estimate dietary intake from food images, but the lack of comprehensive datasets with diverse viewpoints, modalities and food annotations hinders the accuracy and realism of such methods. To address this limitation, we introduce NutritionVerse-Synth, the first large-scale dataset of 84,984 photorealistic synthetic 2D food images with associated dietary information and multimodal annotations (including depth images, instance masks, and semantic masks). Additionally, we collect a real image dataset, NutritionVerse-Real, containing 889 images of 251 dishes to evaluate realism. Leveraging these novel datasets, we develop and benchmark NutritionVerse, an empirical study of various dietary intake estimation approaches, including indirect segmentation-based and direct prediction networks. We further fine-tune models pretrained on synthetic data with real images to provide insights into the fusion of synthetic and real data. Finally, we release both datasets (NutritionVerse-Synth, NutritionVerse-Real) on https://www.kaggle.com/nutritionverse/datasets as part of an open initiative to accelerate machine learning for dietary sensing.
Transferring Knowledge for Food Image Segmentation using Transformers and Convolutions
Jun 15, 2023Food image segmentation is an important task that has ubiquitous applications, such as estimating the nutritional value of a plate of food. Although machine learning models have been used for segmentation in this domain, food images pose several challenges. One challenge is that food items can overlap and mix, making them difficult to distinguish. Another challenge is the degree of inter-class similarity and intra-class variability, which is caused by the varying preparation methods and dishes a food item may be served in. Additionally, class imbalance is an inevitable issue in food datasets. To address these issues, two models are trained and compared, one based on convolutional neural networks and the other on Bidirectional Encoder representation for Image Transformers (BEiT). The models are trained and valuated using the FoodSeg103 dataset, which is identified as a robust benchmark for food image segmentation. The BEiT model outperforms the previous state-of-the-art model by achieving a mean intersection over union of 49.4 on FoodSeg103. This study provides insights into transfering knowledge using convolution and Transformer-based approaches in the food image domain.