 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Knowledge for Food Image Segmentation using Transformers and Convolutions
Jun 15, 2023Food image segmentation is an important task that has ubiquitous applications, such as estimating the nutritional value of a plate of food. Although machine learning models have been used for segmentation in this domain, food images pose several challenges. One challenge is that food items can overlap and mix, making them difficult to distinguish. Another challenge is the degree of inter-class similarity and intra-class variability, which is caused by the varying preparation methods and dishes a food item may be served in. Additionally, class imbalance is an inevitable issue in food datasets. To address these issues, two models are trained and compared, one based on convolutional neural networks and the other on Bidirectional Encoder representation for Image Transformers (BEiT). The models are trained and valuated using the FoodSeg103 dataset, which is identified as a robust benchmark for food image segmentation. The BEiT model outperforms the previous state-of-the-art model by achieving a mean intersection over union of 49.4 on FoodSeg103. This study provides insights into transfering knowledge using convolution and Transformer-based approaches in the food image domain.
Improving Accuracy and Explainability of Online Handwriting Recognition
Sep 14, 2022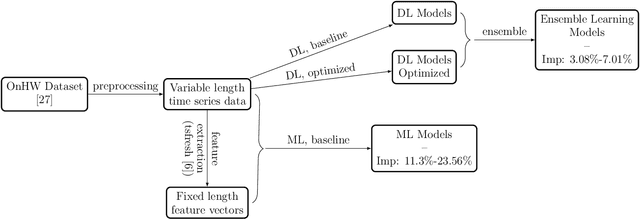

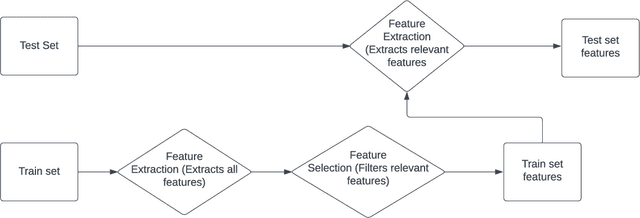
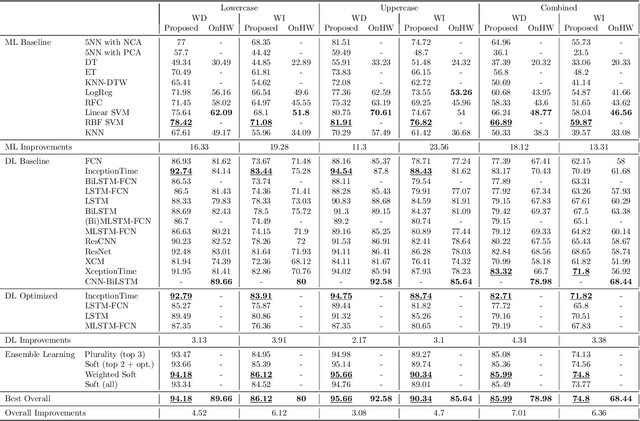
Handwriting recognition technology allows recognizing a written text from a given data. The recognition task can target letters, symbols, or words, and the input data can be a digital image or recorded by various sensors. A wide range of applications from signature verification to electronic document processing can be realized by implementing efficient and accurate handwriting recognition algorithms. Over the years, there has been an increasing interest in experimenting with different types of technology to collect handwriting data, create datasets, and develop algorithms to recognize characters and symbols. More recently, the OnHW-chars dataset has been published that contains multivariate time series data of the English alphabet collected using a ballpoint pen fitted with sensors. The authors of OnHW-chars also provided some baseline results through their machine learning (ML) and deep learning (DL) classifiers. In this paper, we develop handwriting recognition models on the OnHW-chars dataset and improve the accuracy of previous models. More specifically, our ML models provide $11.3\%$-$23.56\%$ improvements over the previous ML models, and our optimized DL models with ensemble learning provide $3.08\%$-$7.01\%$ improvements over the previous DL models. In addition to our accuracy improvements over the spectrum, we aim to provide some level of explainability for our models to provide more logic behind chosen methods and why the models make sense for the data type in the dataset. Our results are verifiable and reproducible via the provided public repository.
COVID-Net UV: An End-to-End Spatio-Temporal Deep Neural Network Architecture for Automated Diagnosis of COVID-19 Infection from Ultrasound Videos
May 18, 2022
Besides vaccination, as an effective way to mitigate the further spread of COVID-19, fast and accurate screening of individuals to test for the disease is yet necessary to ensure public health safety. We propose COVID-Net UV, an end-to-end hybrid spatio-temporal deep neural network architecture, to detect COVID-19 infection from lung point-of-care ultrasound videos captured by convex transducers. COVID-Net UV comprises a convolutional neural network that extracts spatial features and a recurrent neural network that learns temporal dependence. After careful hyperparameter tuning, the network achieves an average accuracy of 94.44% with no false-negative cases for COVID-19 cases. The goal with COVID-Net UV is to assist front-line clinicians in the fight against COVID-19 via accelerating the screening of lung point-of-care ultrasound videos and automatic detection of COVID-19 positive cases.
Improving Classification Model Performance on Chest X-Rays through Lung Segmentation
Feb 22, 2022


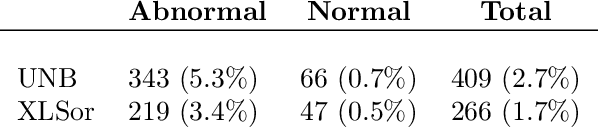
Chest radiography is an effective screening tool for diagnosing pulmonary diseases. In computer-aided diagnosis, extracting the relevant region of interest, i.e., isolating the lung region of each radiography image, can be an essential step towards improved performance in diagnosing pulmonary disorders. Methods: In this work, we propose a deep learning approach to enhance abnormal chest x-ray (CXR) identification performance through segmentations. Our approach is designed in a cascaded manner and incorporates two modules: a deep neural network with criss-cross attention modules (XLSor) for localizing lung region in CXR images and a CXR classification model with a backbone of a self-supervised momentum contrast (MoCo) model pre-trained on large-scale CXR data sets. The proposed pipeline is evaluated on Shenzhen Hospital (SH) data set for the segmentation module, and COVIDx data set for both segmentation and classification modules. Novel statistical analysis is conducted in addition to regular evaluation metrics for the segmentation module. Furthermore, the results of the optimized approach are analyzed with gradient-weighted class activation mapping (Grad-CAM) to investigate the rationale behind the classification decisions and to interpret its choices. Results and Conclusion: Different data sets, methods, and scenarios for each module of the proposed pipeline are examined for designing an optimized approach, which has achieved an accuracy of 0.946 in distinguishing abnormal CXR images (i.e., Pneumonia and COVID-19) from normal ones. Numerical and visual validations suggest that applying automated segmentation as a pre-processing step for classification improves the generalization capability and the performance of the classification models.
COVID-19 Detection from Chest X-ray Images using Imprinted Weights Approach
May 04, 2021
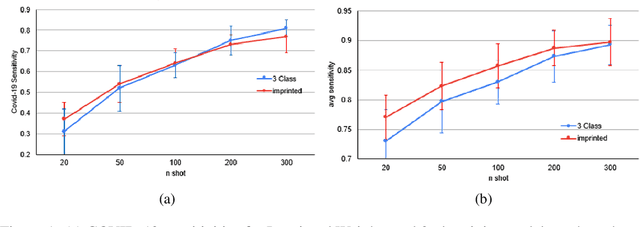
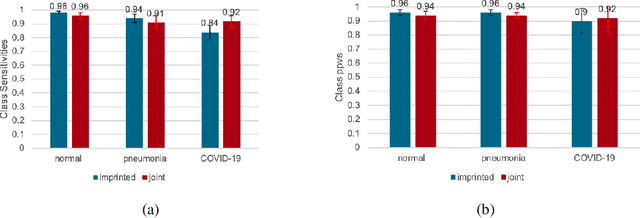
The COVID-19 pandemic has had devastating effects on the well-being of the global population. The pandemic has been so prominent partly due to the high infection rate of the virus and its variants. In response, one of the most effective ways to stop infection is rapid diagnosis. The main-stream screening method, reverse transcription-polymerase chain reaction (RT-PCR), is time-consuming, laborious and in short supply. Chest radiography is an alternative screening method for the COVID-19 and computer-aided diagnosis (CAD) has proven to be a viable solution at low cost and with fast speed; however, one of the challenges in training the CAD models is the limited number of training data, especially at the onset of the pandemic. This becomes outstanding precisely when the quick and cheap type of diagnosis is critically needed for flattening the infection curve. To address this challenge, we propose the use of a low-shot learning approach named imprinted weights, taking advantage of the abundance of samples from known illnesses such as pneumonia to improve the detection performance on COVID-19.