 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Accuracy and Explainability of Online Handwriting Recognition
Sep 14, 2022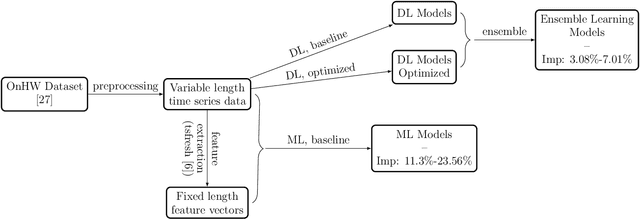

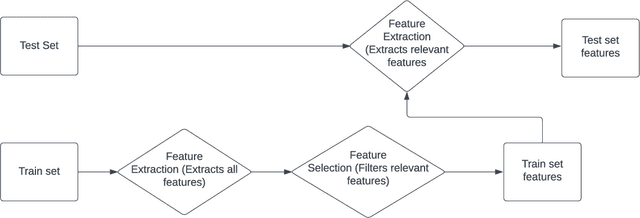
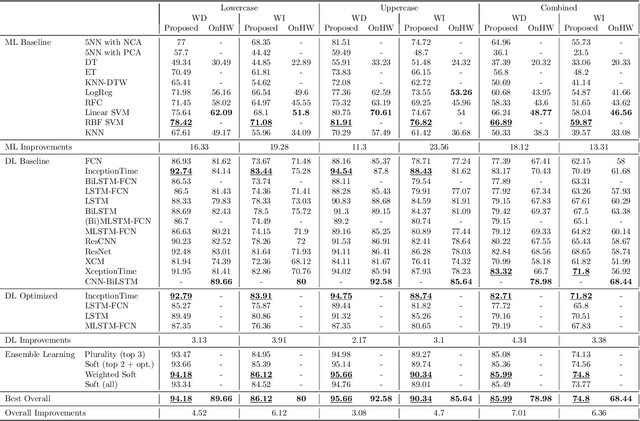
Handwriting recognition technology allows recognizing a written text from a given data. The recognition task can target letters, symbols, or words, and the input data can be a digital image or recorded by various sensors. A wide range of applications from signature verification to electronic document processing can be realized by implementing efficient and accurate handwriting recognition algorithms. Over the years, there has been an increasing interest in experimenting with different types of technology to collect handwriting data, create datasets, and develop algorithms to recognize characters and symbols. More recently, the OnHW-chars dataset has been published that contains multivariate time series data of the English alphabet collected using a ballpoint pen fitted with sensors. The authors of OnHW-chars also provided some baseline results through their machine learning (ML) and deep learning (DL) classifiers. In this paper, we develop handwriting recognition models on the OnHW-chars dataset and improve the accuracy of previous models. More specifically, our ML models provide $11.3\%$-$23.56\%$ improvements over the previous ML models, and our optimized DL models with ensemble learning provide $3.08\%$-$7.01\%$ improvements over the previous DL models. In addition to our accuracy improvements over the spectrum, we aim to provide some level of explainability for our models to provide more logic behind chosen methods and why the models make sense for the data type in the dataset. Our results are verifiable and reproducible via the provided public repository.
ACM RecSys 2018 Late-Breaking Results Proceedings
Sep 11, 2018The ACM RecSys'18 Late-Breaking Results track (previously known as the Poster track) is part of the main program of the 2018 ACM Conference on Recommender Systems in Vancouver, Canada. The track attracted 48 submissions this year out of which 18 papers could be accepted resulting in an acceptance rated of 37.5%.