 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM or Human? Perceptions of Trust and Information Quality in Research Summaries
Jan 22, 2026Large Language Models (LLMs) are increasingly used to generate and edit scientific abstracts, yet their integration into academic writing raises questions about trust, quality, and disclosure. Despite growing adoption, little is known about how readers perceive LLM-generated summaries and how these perceptions influence evaluations of scientific work. This paper presents a mixed-methods survey experiment investigating whether readers with ML expertise can distinguish between human- and LLM-generated abstracts, how actual and perceived LLM involvement affects judgments of quality and trustworthiness, and what orientations readers adopt toward AI-assisted writing. Our findings show that participants struggle to reliably identify LLM-generated content, yet their beliefs about LLM involvement significantly shape their evaluations. Notably, abstracts edited by LLMs are rated more favorably than those written solely by humans or LLMs. We also identify three distinct reader orientations toward LLM-assisted writing, offering insights into evolving norms and informing policy around disclosure and acceptable use in scientific communication.
A Use-Case Specific Dataset for Measuring Dimensions of Responsible Performance in LLM-generated Text
Oct 23, 2025Current methods for evaluating large language models (LLMs) typically focus on high-level tasks such as text generation, without targeting a particular AI application. This approach is not sufficient for evaluating LLMs for Responsible AI dimensions like fairness, since protected attributes that are highly relevant in one application may be less relevant in another. In this work, we construct a dataset that is driven by a real-world application (generate a plain-text product description, given a list of product features), parameterized by fairness attributes intersected with gendered adjectives and product categories, yielding a rich set of labeled prompts. We show how to use the data to identify quality, veracity, safety, and fairness gaps in LLMs, contributing a proposal for LLM evaluation paired with a concrete resource for the research community.
Unsupervised Domain Adaptation for Hate Speech Detection Using a Data Augmentation Approach
Jul 31, 2021
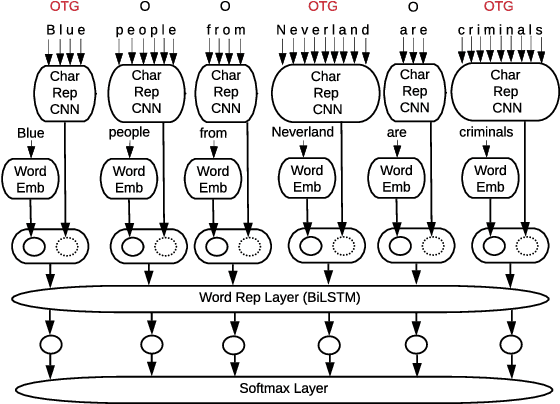
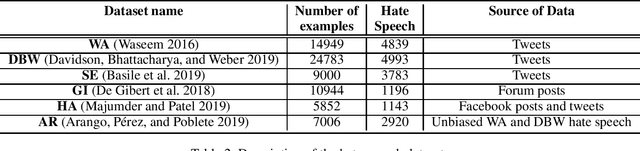

Online harassment in the form of hate speech has been on the rise in recent years. Addressing the issue requires a combination of content moderation by people, aided by automatic detection methods. As content moderation is itself harmful to the people doing it, we desire to reduce the burden by improving the automatic detection of hate speech. Hate speech presents a challenge as it is directed at different target groups using a completely different vocabulary. Further the authors of the hate speech are incentivized to disguise their behavior to avoid being removed from a platform. This makes it difficult to develop a comprehensive data set for training and evaluating hate speech detection models because the examples that represent one hate speech domain do not typically represent others, even within the same language or culture. We propose an unsupervised domain adaptation approach to augment labeled data for hate speech detection. We evaluate the approach with three different models (character CNNs, BiLSTMs and BERT) on three different collections. We show our approach improves Area under the Precision/Recall curve by as much as 42% and recall by as much as 278%, with no loss (and in some cases a significant gain) in precision.
ACM RecSys 2018 Late-Breaking Results Proceedings
Sep 11, 2018The ACM RecSys'18 Late-Breaking Results track (previously known as the Poster track) is part of the main program of the 2018 ACM Conference on Recommender Systems in Vancouver, Canada. The track attracted 48 submissions this year out of which 18 papers could be accepted resulting in an acceptance rated of 37.5%.