 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTexture Image Synthesis Using Spatial GAN Based on Vision Transformers
Feb 03, 2025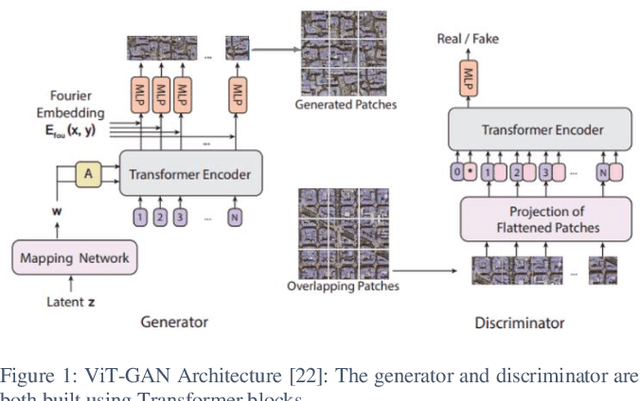
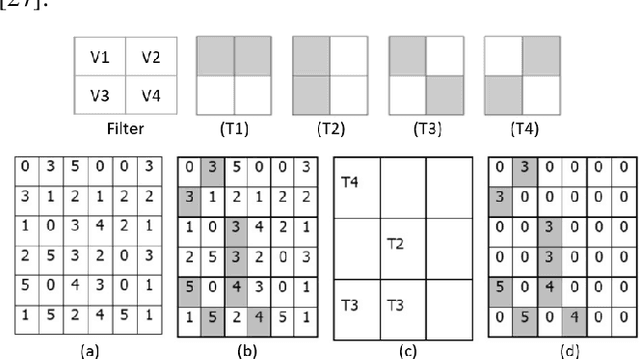
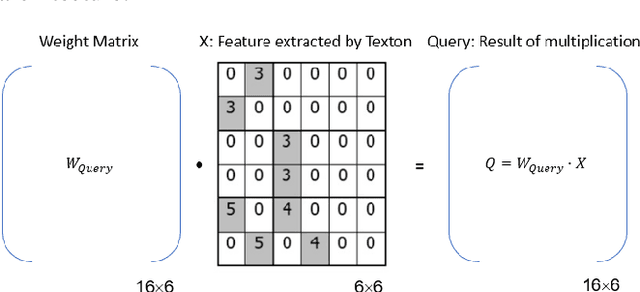

Texture synthesis is a fundamental task in computer vision, whose goal is to generate visually realistic and structurally coherent textures for a wide range of applications, from graphics to scientific simulations. While traditional methods like tiling and patch-based techniques often struggle with complex textures, recent advancements in deep learning have transformed this field. In this paper, we propose ViT-SGAN, a new hybrid model that fuses Vision Transformers (ViTs) with a Spatial Generative Adversarial Network (SGAN) to address the limitations of previous methods. By incorporating specialized texture descriptors such as mean-variance (mu, sigma) and textons into the self-attention mechanism of ViTs, our model achieves superior texture synthesis. This approach enhances the model's capacity to capture complex spatial dependencies, leading to improved texture quality that is superior to state-of-the-art models, especially for regular and irregular textures. Comparison experiments with metrics such as FID, IS, SSIM, and LPIPS demonstrate the substantial improvement of ViT-SGAN, which underlines its efficiency in generating diverse realistic textures.
* Published at the 2nd International Conference on Artificial Intelligence and Software Engineering (AI-SOFT), Shiraz University, Shiraz, Iran, 2024
DensePANet: An improved generative adversarial network for photoacoustic tomography image reconstruction from sparse data
Apr 19, 2024Image reconstruction is an essential step of every medical imaging method, including Photoacoustic Tomography (PAT), which is a promising modality of imaging, that unites the benefits of both ultrasound and optical imaging methods. Reconstruction of PAT images using conventional methods results in rough artifacts, especially when applied directly to sparse PAT data. In recent years, generative adversarial networks (GANs) have shown a powerful performance in image generation as well as translation, rendering them a smart choice to be applied to reconstruction tasks. In this study, we proposed an end-to-end method called DensePANet to solve the problem of PAT image reconstruction from sparse data. The proposed model employs a novel modification of UNet in its generator, called FD-UNet++, which considerably improves the reconstruction performance. We evaluated the method on various in-vivo and simulated datasets. Quantitative and qualitative results show the better performance of our model over other prevalent deep learning techniques.
Deep-MDS Framework for Recovering the 3D Shape of 2D Landmarks from a Single Image
Oct 27, 2022In this paper, a low parameter deep learning framework utilizing the Non-metric Multi-Dimensional scaling (NMDS) method, is proposed to recover the 3D shape of 2D landmarks on a human face, in a single input image. Hence, NMDS approach is used for the first time to establish a mapping from a 2D landmark space to the corresponding 3D shape space. A deep neural network learns the pairwise dissimilarity among 2D landmarks, used by NMDS approach, whose objective is to learn the pairwise 3D Euclidean distance of the corresponding 2D landmarks on the input image. This scheme results in a symmetric dissimilarity matrix, with the rank larger than 2, leading the NMDS approach toward appropriately recovering the 3D shape of corresponding 2D landmarks. In the case of posed images and complex image formation processes like perspective projection which causes occlusion in the input image, we consider an autoencoder component in the proposed framework, as an occlusion removal part, which turns different input views of the human face into a profile view. The results of a performance evaluation using different synthetic and real-world human face datasets, including Besel Face Model (BFM), CelebA, CoMA - FLAME, and CASIA-3D, indicates the comparable performance of the proposed framework, despite its small number of training parameters, with the related state-of-the-art and powerful 3D reconstruction methods from the literature, in terms of efficiency and accuracy.
Survey of Deep Learning Methods for Inverse Problems
Nov 13, 2021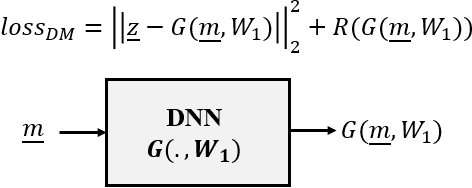
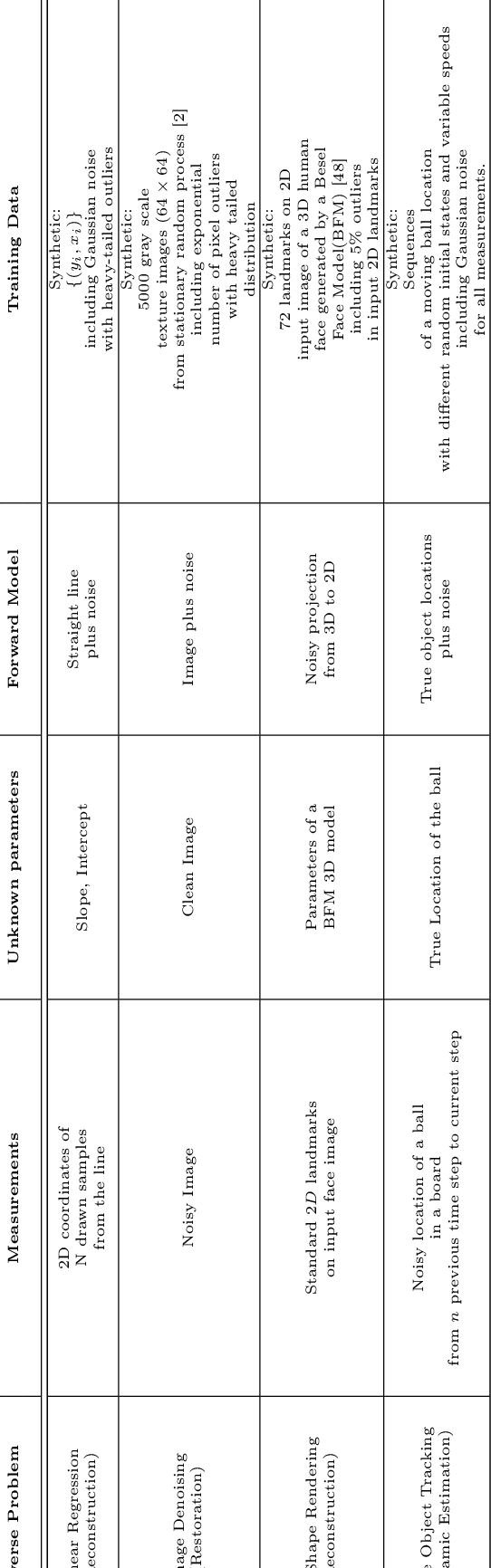
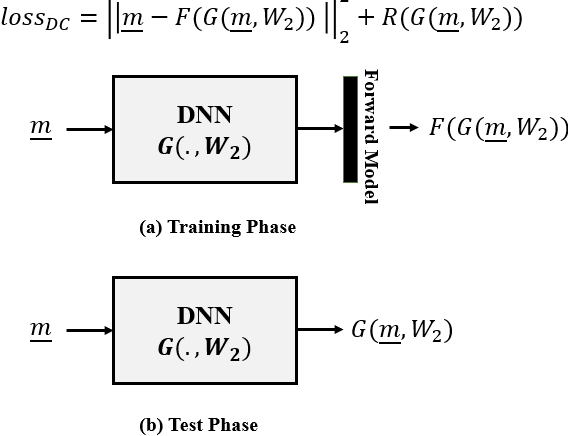

In this paper we investigate a variety of deep learning strategies for solving inverse problems. We classify existing deep learning solutions for inverse problems into three categories of Direct Mapping, Data Consistency Optimizer, and Deep Regularizer. We choose a sample of each inverse problem type, so as to compare the robustness of the three categories, and report a statistical analysis of their differences. We perform extensive experiments on the classic problem of linear regression and three well-known inverse problems in computer vision, namely image denoising, 3D human face inverse rendering, and object tracking, selected as representative prototypes for each class of inverse problems. The overall results and the statistical analyses show that the solution categories have a robustness behaviour dependent on the type of inverse problem domain, and specifically dependent on whether or not the problem includes measurement outliers. Based on our experimental results, we conclude by proposing the most robust solution category for each inverse problem class.
Meta-heuristic for non-homogeneous peak density spaces and implementation on 2 real-world parameter learning/tuning applications
Jun 13, 2019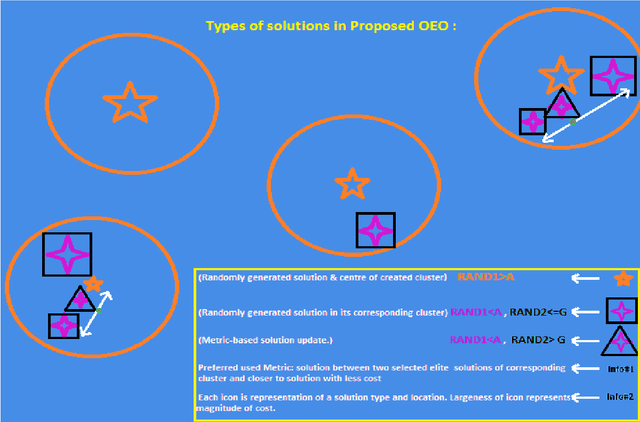
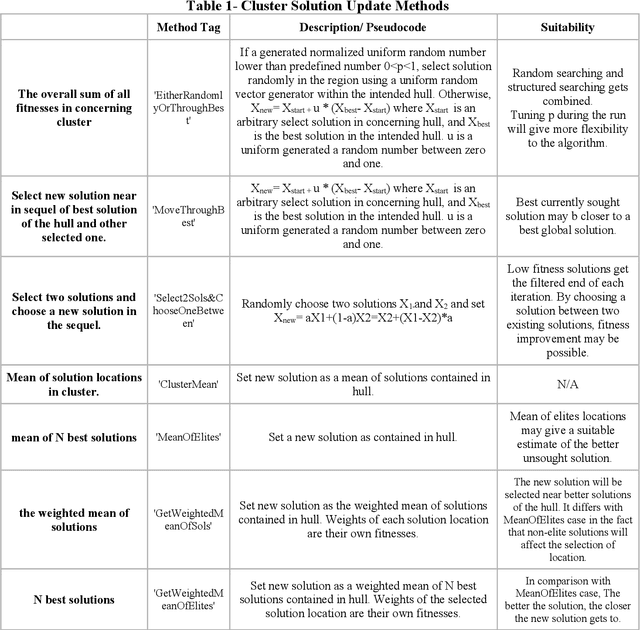
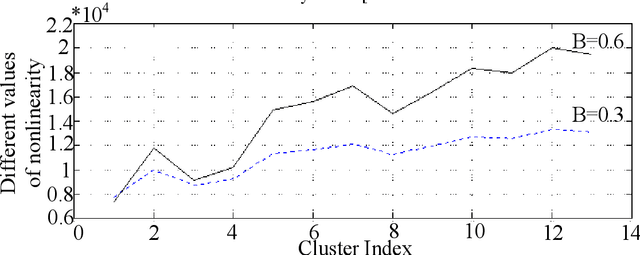
Observer effect in physics (/psychology) regards bias in measurement (/perception) due to the interference of instrument (/knowledge). Based on these concepts, a new meta-heuristic algorithm is proposed for controlling memory usage per localities without pursuing Tabu-like cut-off approaches. In this paper, first, variations of observer effect are explained in different branches of science from physics to psychology. Then, a metaheuristic algorithm is proposed based on observer effect concepts and the used metrics are explained. The derived optimizer performance has been compared between 1st, non-homogeneous-peaks-density functions, and 2nd, homogeneous-peaks-density functions to verify the algorithm outperformance in the 1st scheme. Finally, performance analysis of the novel algorithms is derived using two real-world engineering applications in Electroencephalogram feature learning and Distributed Generator parameter tuning, each of which having nonlinearity and complex multi-modal peaks distributions as its characteristics. Also, the effect of version improvement has been assessed. The performance analysis among other optimizers in the same context suggests that the proposed algorithm is useful both solely and in hybrid Gradient Descent settings where problem's search space is nonhomogeneous in terms of local peaks density.
Deep Generative Models: Deterministic Prediction with an Application in Inverse Rendering
Mar 11, 2019



Deep generative models are stochastic neural networks capable of learning the distribution of data so as to generate new samples. Conditional Variational Autoencoder (CVAE) is a powerful deep generative model aiming at maximizing the lower bound of training data log-likelihood. In the CVAE structure, there is appropriate regularizer, which makes it applicable for suitably constraining the solution space in solving ill-posed problems and providing high generalization power. Considering the stochastic prediction characteristic in CVAE, depending on the problem at hand, it is desirable to be able to control the uncertainty in CVAE predictions. Therefore, in this paper we analyze the impact of CVAE's condition on the diversity of solutions given by our designed CVAE in 3D shape inverse rendering as a prediction problem. The experimental results using Modelnet10 and Shapenet datasets show the appropriate performance of our designed CVAE and verify the hypothesis: \emph{"The more informative the conditions in terms of object pose are, the less diverse the CVAE predictions are}".
Unsupervised Feature Learning Toward a Real-time Vehicle Make and Model Recognition
Jun 08, 2018


Vehicle Make and Model Recognition (MMR) systems provide a fully automatic framework to recognize and classify different vehicle models. Several approaches have been proposed to address this challenge, however they can perform in restricted conditions. Here, we formulate the vehicle make and model recognition as a fine-grained classification problem and propose a new configurable on-road vehicle make and model recognition framework. We benefit from the unsupervised feature learning methods and in more details we employ Locality constraint Linear Coding (LLC) method as a fast feature encoder for encoding the input SIFT features. The proposed method can perform in real environments of different conditions. This framework can recognize fifty models of vehicles and has an advantage to classify every other vehicle not belonging to one of the specified fifty classes as an unknown vehicle. The proposed MMR framework can be configured to become faster or more accurate based on the application domain. The proposed approach is examined on two datasets including Iranian on-road vehicle dataset and CompuCar dataset. The Iranian on-road vehicle dataset contains images of 50 models of vehicles captured in real situations by traffic cameras in different weather and lighting conditions. Experimental results show superiority of the proposed framework over the state-of-the-art methods on Iranian on-road vehicle datatset and comparable results on CompuCar dataset with 97.5% and 98.4% accuracies, respectively.
A Deep-structured Conditional Random Field Model for Object Silhouette Tracking
Aug 04, 2015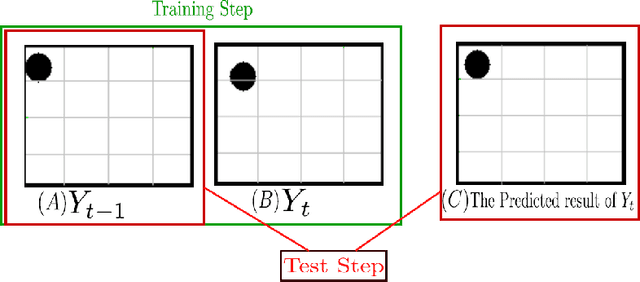
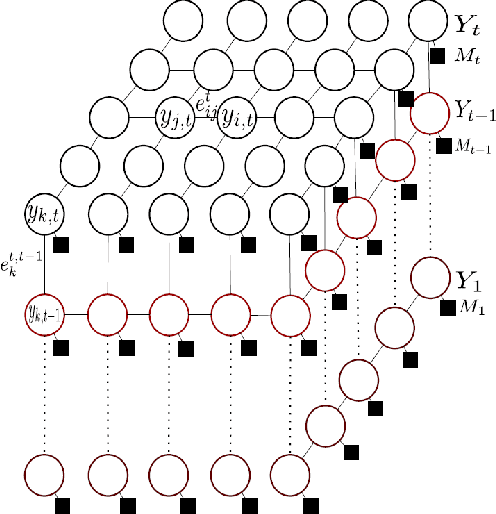
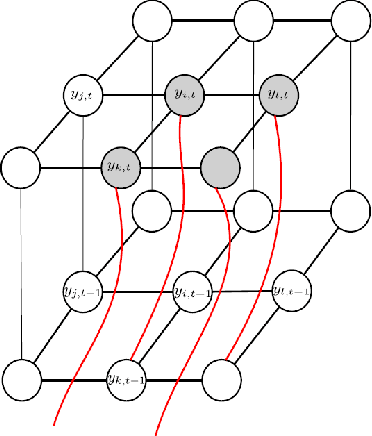

In this work, we introduce a deep-structured conditional random field (DS-CRF) model for the purpose of state-based object silhouette tracking. The proposed DS-CRF model consists of a series of state layers, where each state layer spatially characterizes the object silhouette at a particular point in time. The interactions between adjacent state layers are established by inter-layer connectivity dynamically determined based on inter-frame optical flow. By incorporate both spatial and temporal context in a dynamic fashion within such a deep-structured probabilistic graphical model, the proposed DS-CRF model allows us to develop a framework that can accurately and efficiently track object silhouettes that can change greatly over time, as well as under different situations such as occlusion and multiple targets within the scene. Experiment results using video surveillance datasets containing different scenarios such as occlusion and multiple targets showed that the proposed DS-CRF approach provides strong object silhouette tracking performance when compared to baseline methods such as mean-shift tracking, as well as state-of-the-art methods such as context tracking and boosted particle filtering.