 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemmCounter: Static People Counting in Dense Indoor Scenarios Using mmWave Radar
Dec 11, 2025mmWave radars struggle to detect or count individuals in dense, static (non-moving) groups due to limitations in spatial resolution and reliance on movement for detection. We present mmCounter, which accurately counts static people in dense indoor spaces (up to three people per square meter). mmCounter achieves this by extracting ultra-low frequency (< 1 Hz) signals, primarily from breathing and micro-scale body movements such as slight torso shifts, and applying novel signal processing techniques to differentiate these subtle signals from background noise and nearby static objects. Our problem differs significantly from existing studies on breathing rate estimation, which assume the number of people is known a priori. In contrast, mmCounter utilizes a novel multi-stage signal processing pipeline to extract relevant low-frequency sources along with their spatial information and map these sources to individual people, enabling accurate counting. Extensive evaluations in various environments demonstrate that mmCounter delivers an 87% average F1 score and 0.6 mean absolute error in familiar environments, and a 60% average F1 score and 1.1 mean absolute error in previously untested environments. It can count up to seven individuals in a three square meter space, such that there is no side-by-side spacing and only a one-meter front-to-back distance.
ChronoFlow: A Data-Driven Model for Gyrochronology
Dec 16, 2024Gyrochronology is a technique for constraining stellar ages using rotation periods, which change over a star's main sequence lifetime due to magnetic braking. This technique shows promise for main sequence FGKM stars, where other methods are imprecise. However, models have historically struggled to capture the observed rotational dispersion in stellar populations. To properly understand this complexity, we have assembled the largest standardized data catalog of rotators in open clusters to date, consisting of ~7,400 stars across 30 open clusters/associations spanning ages of 1.5 Myr to 4 Gyr. We have also developed ChronoFlow: a flexible data-driven model which accurately captures observed rotational dispersion. We show that ChronoFlow can be used to accurately forward model rotational evolution, and to infer both cluster and individual stellar ages. We recover cluster ages with a statistical uncertainty of 0.06 dex ($\approx$ 15%), and individual stellar ages with a statistical uncertainty of 0.7 dex. Additionally, we conducted robust systematic tests to analyze the impact of extinction models, cluster membership, and calibration ages on our model's performance. These contribute an additional $\approx$ 0.06 dex of uncertainty in cluster age estimates, resulting in a total error budget of 0.08 dex. We estimate ages for the NGC 6709 open cluster and the Theia 456 stellar stream, and calculate revised rotational ages for M34, NGC 2516, NGC 1750, and NGC 1647. Our results show that ChronoFlow can precisely estimate the ages of coeval stellar populations, and constrain ages for individual stars. Furthermore, its predictions may be used to inform physical spin down models. ChronoFlow will be publicly available at https://github.com/philvanlane/chronoflow.
A Reinforcement Learning based Reset Policy for CDCL SAT Solvers
Apr 04, 2024



Restart policy is an important technique used in modern Conflict-Driven Clause Learning (CDCL) solvers, wherein some parts of the solver state are erased at certain intervals during the run of the solver. In most solvers, variable activities are preserved across restart boundaries, resulting in solvers continuing to search parts of the assignment tree that are not far from the one immediately prior to a restart. To enable the solver to search possibly "distant" parts of the assignment tree, we study the effect of resets, a variant of restarts which not only erases the assignment trail, but also randomizes the activity scores of the variables of the input formula after reset, thus potentially enabling a better global exploration of the search space. In this paper, we model the problem of whether to trigger reset as a multi-armed bandit (MAB) problem, and propose two reinforcement learning (RL) based adaptive reset policies using the Upper Confidence Bound (UCB) and Thompson sampling algorithms. These two algorithms balance the exploration-exploitation tradeoff by adaptively choosing arms (reset vs. no reset) based on their estimated rewards during the solver's run. We implement our reset policies in four baseline SOTA CDCL solvers and compare the baselines against the reset versions on Satcoin benchmarks and SAT Competition instances. Our results show that RL-based reset versions outperform the corresponding baseline solvers on both Satcoin and the SAT competition instances, suggesting that our RL policy helps to dynamically and profitably adapt the reset frequency for any given input instance. We also introduce the concept of a partial reset, where at least a constant number of variable activities are retained across reset boundaries. Building on previous results, we show that there is an exponential separation between O(1) vs. $\Omega(n)$-length partial resets.
When is it permissible for artificial intelligence to lie? A trust-based approach
Mar 14, 2021Conversational Artificial Intelligence (AI) used in industry settings can be trained to closely mimic human behaviors, including lying and deception. However, lying is often a necessary part of negotiation. To address this, we develop a normative framework for when it is ethical or unethical for a conversational AI to lie to humans, based on whether there is what we call "invitation of trust" in a particular scenario. Importantly, cultural norms play an important role in determining whether there is invitation of trust across negotiation settings, and thus an AI trained in one culture may not be generalizable to others. Moreover, individuals may have different expectations regarding the invitation of trust and propensity to lie for human vs. AI negotiators, and these expectations may vary across cultures as well. Finally, we outline how a conversational chatbot can be trained to negotiate ethically by applying autoregressive models to large dialog and negotiations datasets.
Spoiled for Choice? Personalized Recommendation for Healthcare Decisions: A Multi-Armed Bandit Approach
Sep 13, 2020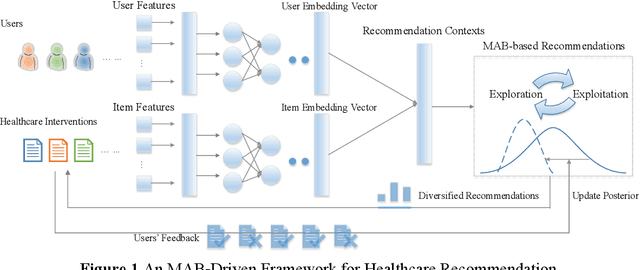
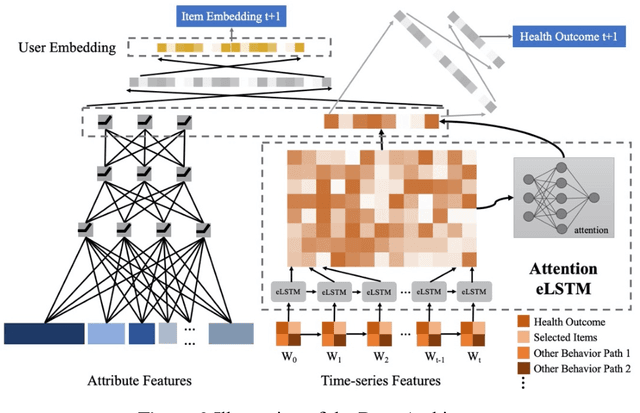

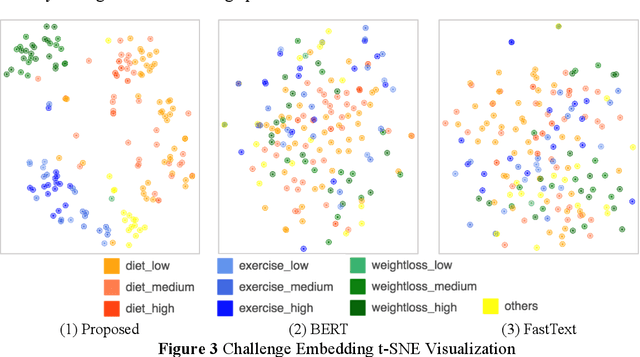
Online healthcare communities provide users with various healthcare interventions to promote healthy behavior and improve adherence. When faced with too many intervention choices, however, individuals may find it difficult to decide which option to take, especially when they lack the experience or knowledge to evaluate different options. The choice overload issue may negatively affect users' engagement in health management. In this study, we take a design-science perspective to propose a recommendation framework that helps users to select healthcare interventions. Taking into account that users' health behaviors can be highly dynamic and diverse, we propose a multi-armed bandit (MAB)-driven recommendation framework, which enables us to adaptively learn users' preference variations while promoting recommendation diversity in the meantime. To better adapt an MAB to the healthcare context, we synthesize two innovative model components based on prominent health theories. The first component is a deep-learning-based feature engineering procedure, which is designed to learn crucial recommendation contexts in regard to users' sequential health histories, health-management experiences, preferences, and intrinsic attributes of healthcare interventions. The second component is a diversity constraint, which structurally diversifies recommendations in different dimensions to provide users with well-rounded support. We apply our approach to an online weight management context and evaluate it rigorously through a series of experiments. Our results demonstrate that each of the design components is effective and that our recommendation design outperforms a wide range of state-of-the-art recommendation systems. Our study contributes to the research on the application of business intelligence and has implications for multiple stakeholders, including online healthcare platforms, policymakers, and users.