 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronoFlow: A Data-Driven Model for Gyrochronology
Dec 16, 2024Gyrochronology is a technique for constraining stellar ages using rotation periods, which change over a star's main sequence lifetime due to magnetic braking. This technique shows promise for main sequence FGKM stars, where other methods are imprecise. However, models have historically struggled to capture the observed rotational dispersion in stellar populations. To properly understand this complexity, we have assembled the largest standardized data catalog of rotators in open clusters to date, consisting of ~7,400 stars across 30 open clusters/associations spanning ages of 1.5 Myr to 4 Gyr. We have also developed ChronoFlow: a flexible data-driven model which accurately captures observed rotational dispersion. We show that ChronoFlow can be used to accurately forward model rotational evolution, and to infer both cluster and individual stellar ages. We recover cluster ages with a statistical uncertainty of 0.06 dex ($\approx$ 15%), and individual stellar ages with a statistical uncertainty of 0.7 dex. Additionally, we conducted robust systematic tests to analyze the impact of extinction models, cluster membership, and calibration ages on our model's performance. These contribute an additional $\approx$ 0.06 dex of uncertainty in cluster age estimates, resulting in a total error budget of 0.08 dex. We estimate ages for the NGC 6709 open cluster and the Theia 456 stellar stream, and calculate revised rotational ages for M34, NGC 2516, NGC 1750, and NGC 1647. Our results show that ChronoFlow can precisely estimate the ages of coeval stellar populations, and constrain ages for individual stars. Furthermore, its predictions may be used to inform physical spin down models. ChronoFlow will be publicly available at https://github.com/philvanlane/chronoflow.
Estimating Probability Densities with Transformer and Denoising Diffusion
Jul 22, 2024Transformers are often the go-to architecture to build foundation models that ingest a large amount of training data. But these models do not estimate the probability density distribution when trained on regression problems, yet obtaining full probabilistic outputs is crucial to many fields of science, where the probability distribution of the answer can be non-Gaussian and multimodal. In this work, we demonstrate that training a probabilistic model using a denoising diffusion head on top of the Transformer provides reasonable probability density estimation even for high-dimensional inputs. The combined Transformer+Denoising Diffusion model allows conditioning the output probability density on arbitrary combinations of inputs and it is thus a highly flexible density function emulator of all possible input/output combinations. We illustrate our Transformer+Denoising Diffusion model by training it on a large dataset of astronomical observations and measured labels of stars within our Galaxy and we apply it to a variety of inference tasks to show that the model can infer labels accurately with reasonable distributions.
A Novel Application of Conditional Normalizing Flows: Stellar Age Inference with Gyrochronology
Jul 17, 2023Stellar ages are critical building blocks of evolutionary models, but challenging to measure for low mass main sequence stars. An unexplored solution in this regime is the application of probabilistic machine learning methods to gyrochronology, a stellar dating technique that is uniquely well suited for these stars. While accurate analytical gyrochronological models have proven challenging to develop, here we apply conditional normalizing flows to photometric data from open star clusters, and demonstrate that a data-driven approach can constrain gyrochronological ages with a precision comparable to other standard techniques. We evaluate the flow results in the context of a Bayesian framework, and show that our inferred ages recover literature values well. This work demonstrates the potential of a probabilistic data-driven solution to widen the applicability of gyrochronological stellar dating.
Monte Carlo Techniques for Addressing Large Errors and Missing Data in Simulation-based Inference
Nov 07, 2022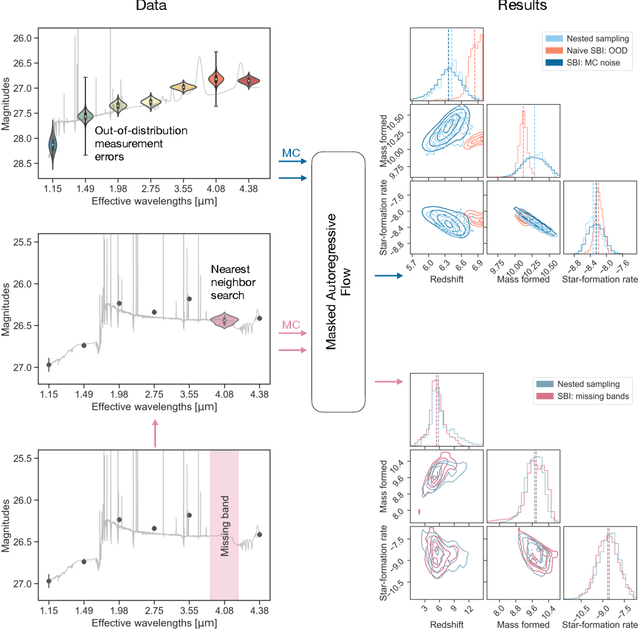

Upcoming astronomical surveys will observe billions of galaxies across cosmic time, providing a unique opportunity to map the many pathways of galaxy assembly to an incredibly high resolution. However, the huge amount of data also poses an immediate computational challenge: current tools for inferring parameters from the light of galaxies take $\gtrsim 10$ hours per fit. This is prohibitively expensive. Simulation-based Inference (SBI) is a promising solution. However, it requires simulated data with identical characteristics to the observed data, whereas real astronomical surveys are often highly heterogeneous, with missing observations and variable uncertainties determined by sky and telescope conditions. Here we present a Monte Carlo technique for treating out-of-distribution measurement errors and missing data using standard SBI tools. We show that out-of-distribution measurement errors can be approximated by using standard SBI evaluations, and that missing data can be marginalized over using SBI evaluations over nearby data realizations in the training set. While these techniques slow the inference process from $\sim 1$ sec to $\sim 1.5$ min per object, this is still significantly faster than standard approaches while also dramatically expanding the applicability of SBI. This expanded regime has broad implications for future applications to astronomical surveys.