 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic search for 100M+ galaxy images using AI-generated captions
Dec 12, 2025Finding scientifically interesting phenomena through slow, manual labeling campaigns severely limits our ability to explore the billions of galaxy images produced by telescopes. In this work, we develop a pipeline to create a semantic search engine from completely unlabeled image data. Our method leverages Vision-Language Models (VLMs) to generate descriptions for galaxy images, then contrastively aligns a pre-trained multimodal astronomy foundation model with these embedded descriptions to produce searchable embeddings at scale. We find that current VLMs provide descriptions that are sufficiently informative to train a semantic search model that outperforms direct image similarity search. Our model, AION-Search, achieves state-of-the-art zero-shot performance on finding rare phenomena despite training on randomly selected images with no deliberate curation for rare cases. Furthermore, we introduce a VLM-based re-ranking method that nearly doubles the recall for our most challenging targets in the top-100 results. For the first time, AION-Search enables flexible semantic search scalable to 140 million galaxy images, enabling discovery from previously infeasible searches. More broadly, our work provides an approach for making large, unlabeled scientific image archives semantically searchable, expanding data exploration capabilities in fields from Earth observation to microscopy. The code, data, and app are publicly available at https://github.com/NolanKoblischke/AION-Search
Estimating Probability Densities with Transformer and Denoising Diffusion
Jul 22, 2024Transformers are often the go-to architecture to build foundation models that ingest a large amount of training data. But these models do not estimate the probability density distribution when trained on regression problems, yet obtaining full probabilistic outputs is crucial to many fields of science, where the probability distribution of the answer can be non-Gaussian and multimodal. In this work, we demonstrate that training a probabilistic model using a denoising diffusion head on top of the Transformer provides reasonable probability density estimation even for high-dimensional inputs. The combined Transformer+Denoising Diffusion model allows conditioning the output probability density on arbitrary combinations of inputs and it is thus a highly flexible density function emulator of all possible input/output combinations. We illustrate our Transformer+Denoising Diffusion model by training it on a large dataset of astronomical observations and measured labels of stars within our Galaxy and we apply it to a variety of inference tasks to show that the model can infer labels accurately with reasonable distributions.
Scaling Laws for Galaxy Images
Apr 03, 2024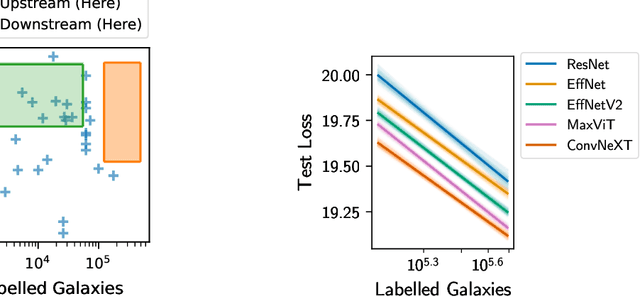
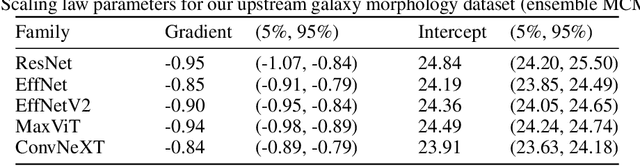
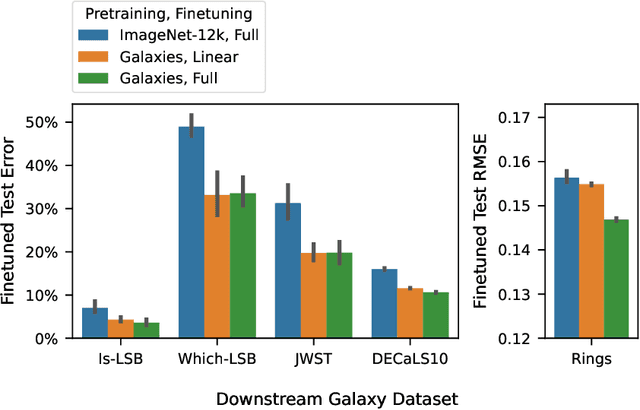
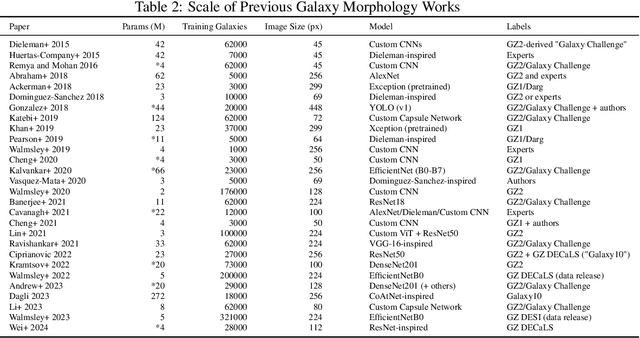
We present the first systematic investigation of supervised scaling laws outside of an ImageNet-like context - on images of galaxies. We use 840k galaxy images and over 100M annotations by Galaxy Zoo volunteers, comparable in scale to Imagenet-1K. We find that adding annotated galaxy images provides a power law improvement in performance across all architectures and all tasks, while adding trainable parameters is effective only for some (typically more subjectively challenging) tasks. We then compare the downstream performance of finetuned models pretrained on either ImageNet-12k alone vs. additionally pretrained on our galaxy images. We achieve an average relative error rate reduction of 31% across 5 downstream tasks of scientific interest. Our finetuned models are more label-efficient and, unlike their ImageNet-12k-pretrained equivalents, often achieve linear transfer performance equal to that of end-to-end finetuning. We find relatively modest additional downstream benefits from scaling model size, implying that scaling alone is not sufficient to address our domain gap, and suggest that practitioners with qualitatively different images might benefit more from in-domain adaption followed by targeted downstream labelling.