 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen is it permissible for artificial intelligence to lie? A trust-based approach
Mar 14, 2021Conversational Artificial Intelligence (AI) used in industry settings can be trained to closely mimic human behaviors, including lying and deception. However, lying is often a necessary part of negotiation. To address this, we develop a normative framework for when it is ethical or unethical for a conversational AI to lie to humans, based on whether there is what we call "invitation of trust" in a particular scenario. Importantly, cultural norms play an important role in determining whether there is invitation of trust across negotiation settings, and thus an AI trained in one culture may not be generalizable to others. Moreover, individuals may have different expectations regarding the invitation of trust and propensity to lie for human vs. AI negotiators, and these expectations may vary across cultures as well. Finally, we outline how a conversational chatbot can be trained to negotiate ethically by applying autoregressive models to large dialog and negotiations datasets.
Portfolio Optimization with 2D Relative-Attentional Gated Transformer
Dec 27, 2020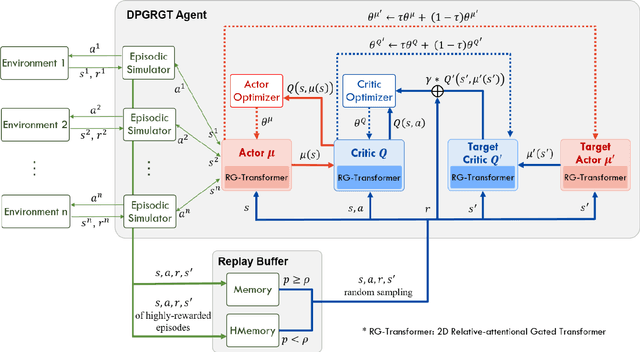

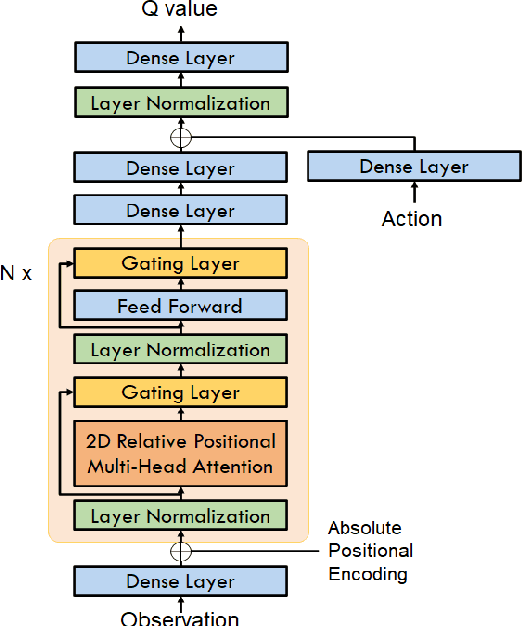
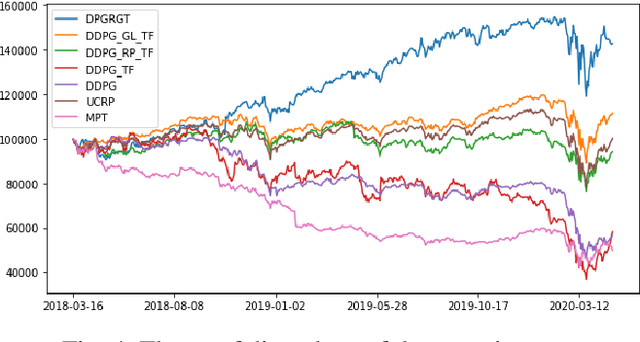
Portfolio optimization is one of the most attentive fields that have been researched with machine learning approaches. Many researchers attempted to solve this problem using deep reinforcement learning due to its efficient inherence that can handle the property of financial markets. However, most of them can hardly be applicable to real-world trading since they ignore or extremely simplify the realistic constraints of transaction costs. These constraints have a significantly negative impact on portfolio profitability. In our research, a conservative level of transaction fees and slippage are considered for the realistic experiment. To enhance the performance under those constraints, we propose a novel Deterministic Policy Gradient with 2D Relative-attentional Gated Transformer (DPGRGT) model. Applying learnable relative positional embeddings for the time and assets axes, the model better understands the peculiar structure of the financial data in the portfolio optimization domain. Also, gating layers and layer reordering are employed for stable convergence of Transformers in reinforcement learning. In our experiment using U.S. stock market data of 20 years, our model outperformed baseline models and demonstrated its effectiveness.
Taking Principles Seriously: A Hybrid Approach to Value Alignment
Dec 21, 2020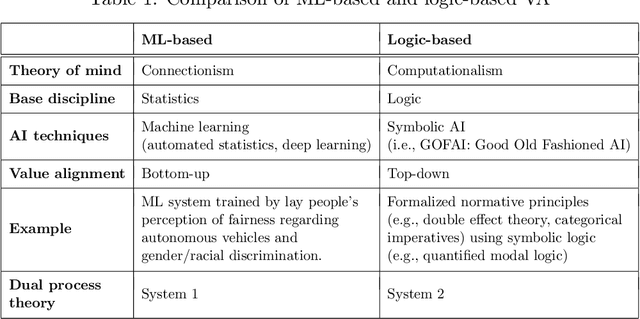
An important step in the development of value alignment (VA) systems in AI is understanding how VA can reflect valid ethical principles. We propose that designers of VA systems incorporate ethics by utilizing a hybrid approach in which both ethical reasoning and empirical observation play a role. This, we argue, avoids committing the "naturalistic fallacy," which is an attempt to derive "ought" from "is," and it provides a more adequate form of ethical reasoning when the fallacy is not committed. Using quantified model logic, we precisely formulate principles derived from deontological ethics and show how they imply particular "test propositions" for any given action plan in an AI rule base. The action plan is ethical only if the test proposition is empirically true, a judgment that is made on the basis of empirical VA. This permits empirical VA to integrate seamlessly with independently justified ethical principles.
Grounding Value Alignment with Ethical Principles
Jul 11, 2019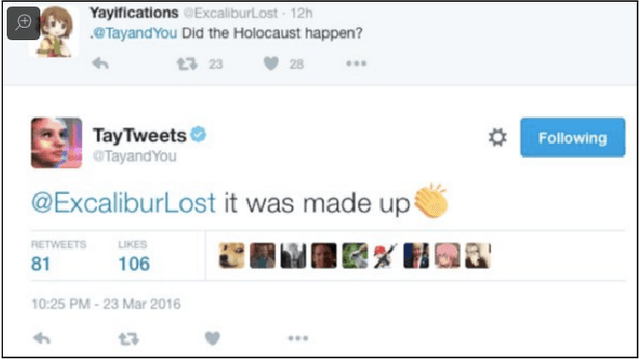


An important step in the development of value alignment (VA) systems in AI is understanding how values can interrelate with facts. Designers of future VA systems will need to utilize a hybrid approach in which ethical reasoning and empirical observation interrelate successfully in machine behavior. In this article we identify two problems about this interrelation that have been overlooked by AI discussants and designers. The first problem is that many AI designers commit inadvertently a version of what has been called by moral philosophers the "naturalistic fallacy," that is, they attempt to derive an "ought" from an "is." We illustrate when and why this occurs. The second problem is that AI designers adopt training routines that fail fully to simulate human ethical reasoning in the integration of ethical principles and facts. Using concepts of quantified modal logic, we proceed to offer an approach that promises to simulate ethical reasoning in humans by connecting ethical principles on the one hand and propositions about states of affairs on the other.
Mimetic vs Anchored Value Alignment in Artificial Intelligence
Oct 25, 2018
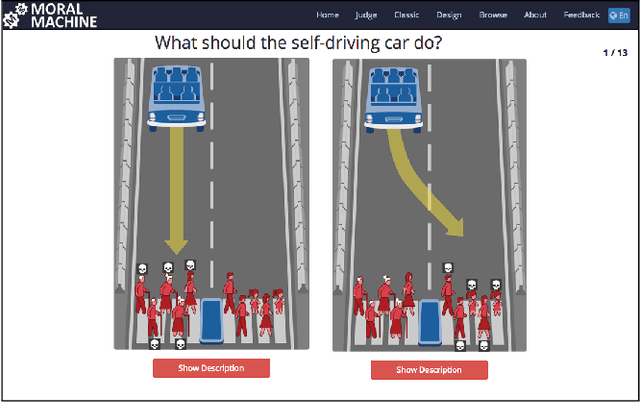
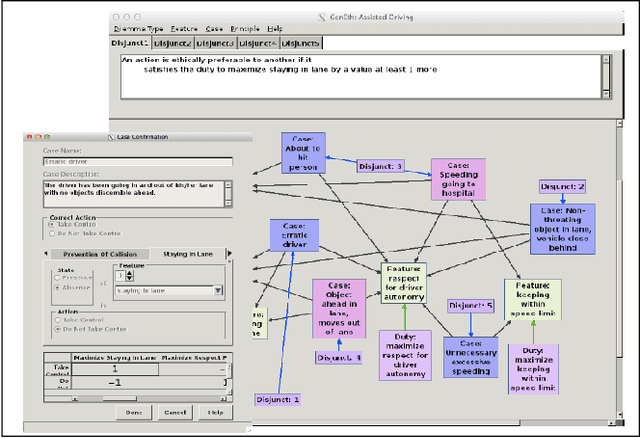
"Value alignment" (VA) is considered as one of the top priorities in AI research. Much of the existing research focuses on the "A" part and not the "V" part of "value alignment." This paper corrects that neglect by emphasizing the "value" side of VA and analyzes VA from the vantage point of requirements in value theory, in particular, of avoiding the "naturalistic fallacy"--a major epistemic caveat. The paper begins by isolating two distinct forms of VA: "mimetic" and "anchored." Then it discusses which VA approach better avoids the naturalistic fallacy. The discussion reveals stumbling blocks for VA approaches that neglect implications of the naturalistic fallacy. Such problems are more serious in mimetic VA since the mimetic process imitates human behavior that may or may not rise to the level of correct ethical behavior. Anchored VA, including hybrid VA, in contrast, holds more promise for future VA since it anchors alignment by normative concepts of intrinsic value.
Explainable artificial intelligence (XAI), the goodness criteria and the grasp-ability test
Oct 22, 2018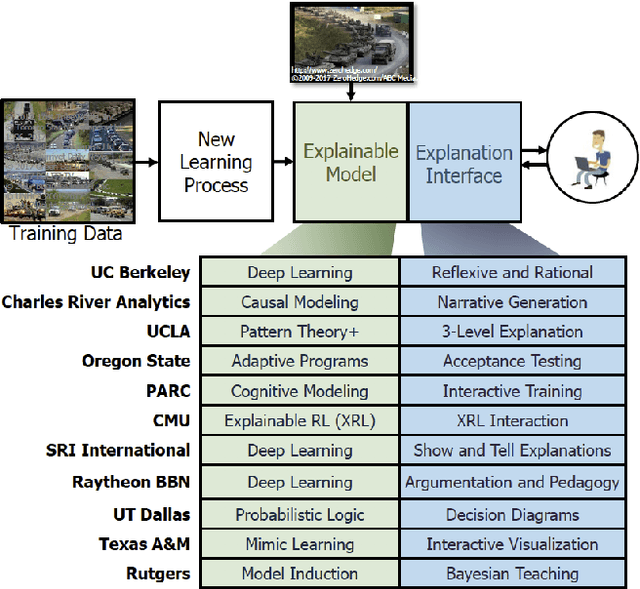
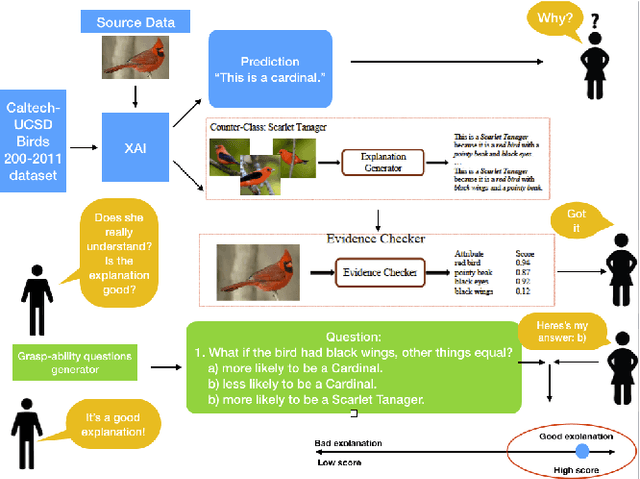
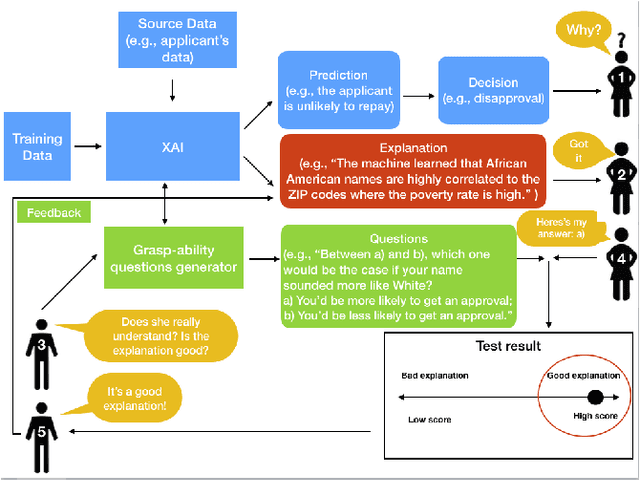
This paper introduces the "grasp-ability test" as a "goodness" criteria by which to compare which explanation is more or less meaningful than others for users to understand the automated algorithmic data processing.