 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking for Public Health Surveillance tasks on Social Media with a Domain-Specific Pretrained Language Model
Apr 09, 2022
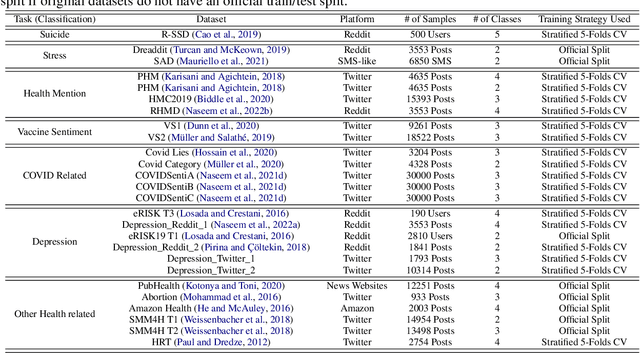
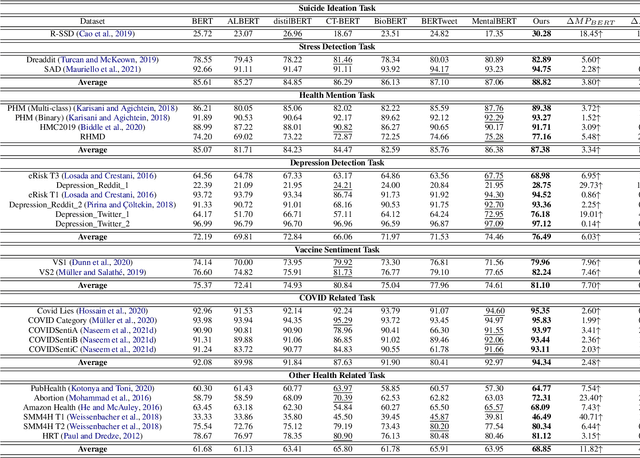
A user-generated text on social media enables health workers to keep track of information, identify possible outbreaks, forecast disease trends, monitor emergency cases, and ascertain disease awareness and response to official health correspondence. This exchange of health information on social media has been regarded as an attempt to enhance public health surveillance (PHS). Despite its potential, the technology is still in its early stages and is not ready for widespread application. Advancements in pretrained language models (PLMs) have facilitated the development of several domain-specific PLMs and a variety of downstream applications. However, there are no PLMs for social media tasks involving PHS. We present and release PHS-BERT, a transformer-based PLM, to identify tasks related to public health surveillance on social media. We compared and benchmarked the performance of PHS-BERT on 25 datasets from different social medial platforms related to 7 different PHS tasks. Compared with existing PLMs that are mainly evaluated on limited tasks, PHS-BERT achieved state-of-the-art performance on all 25 tested datasets, showing that our PLM is robust and generalizable in the common PHS tasks. By making PHS-BERT available, we aim to facilitate the community to reduce the computational cost and introduce new baselines for future works across various PHS-related tasks.
Learning Non-Stationary Time-Series with Dynamic Pattern Extractions
Nov 20, 2021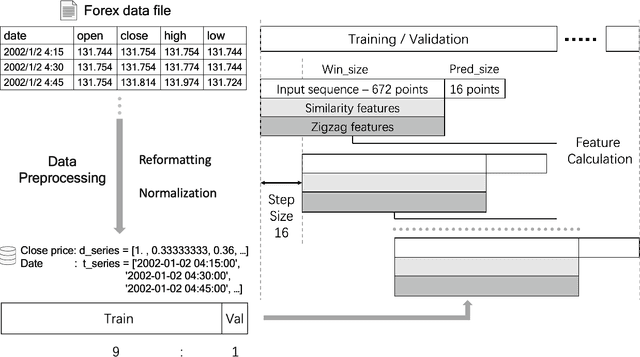
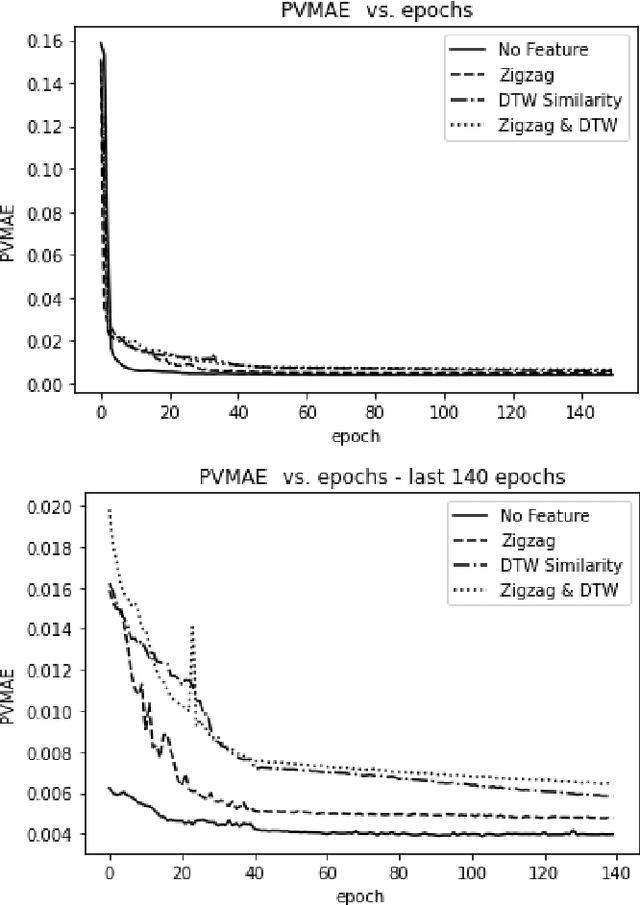
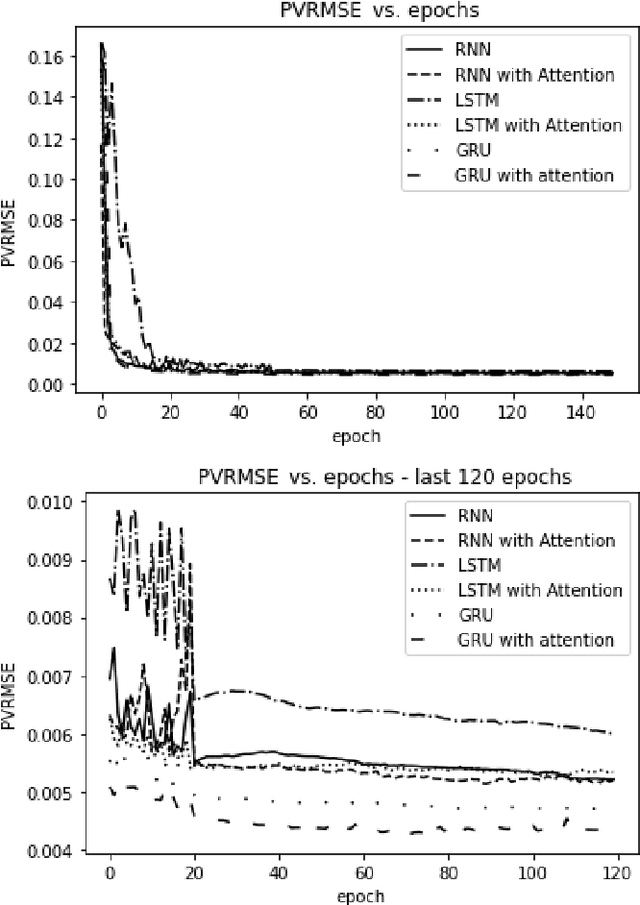
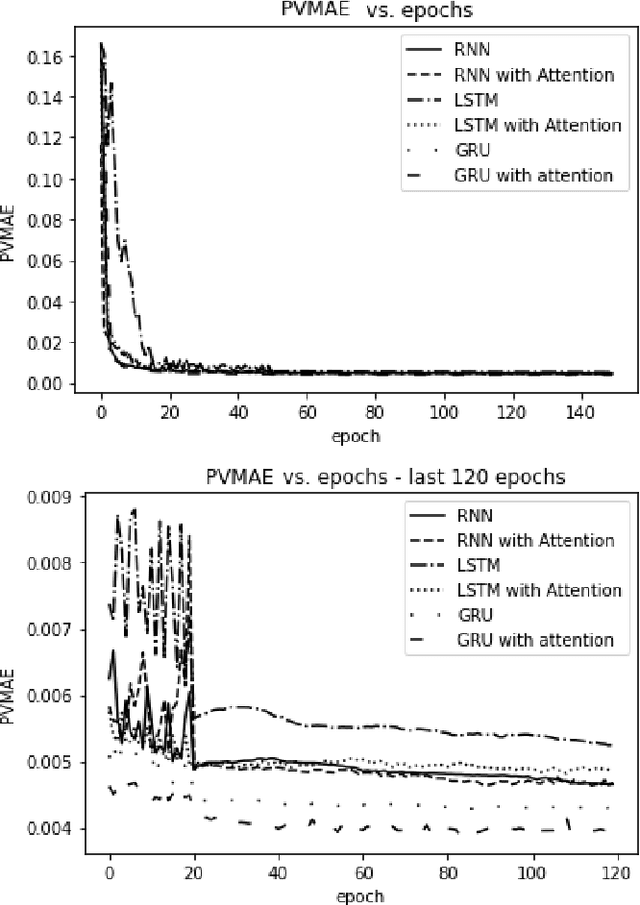
The era of information explosion had prompted the accumulation of a tremendous amount of time-series data, including stationary and non-stationary time-series data. State-of-the-art algorithms have achieved a decent performance in dealing with stationary temporal data. However, traditional algorithms that tackle stationary time-series do not apply to non-stationary series like Forex trading. This paper investigates applicable models that can improve the accuracy of forecasting future trends of non-stationary time-series sequences. In particular, we focus on identifying potential models and investigate the effects of recognizing patterns from historical data. We propose a combination of \rebuttal{the} seq2seq model based on RNN, along with an attention mechanism and an enriched set features extracted via dynamic time warping and zigzag peak valley indicators. Customized loss functions and evaluating metrics have been designed to focus more on the predicting sequence's peaks and valley points. Our results show that our model can predict 4-hour future trends with high accuracy in the Forex dataset, which is crucial in realistic scenarios to assist foreign exchange trading decision making. We further provide evaluations of the effects of various loss functions, evaluation metrics, model variants, and components on model performance.
Benchmarking for Biomedical Natural Language Processing Tasks with a Domain Specific ALBERT
Jul 09, 2021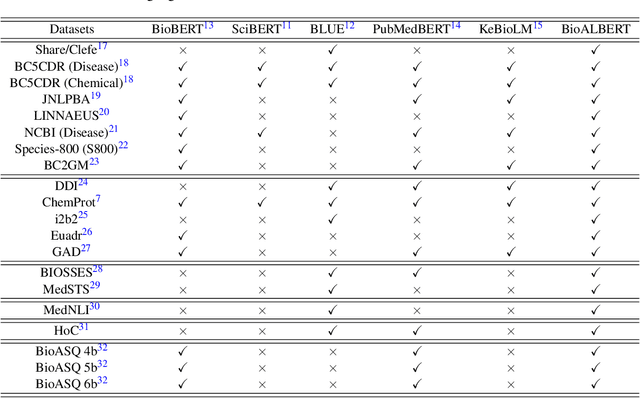


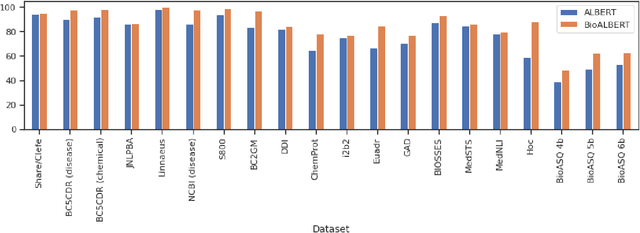
The availability of biomedical text data and advances in natural language processing (NLP) have made new applications in biomedical NLP possible. Language models trained or fine tuned using domain specific corpora can outperform general models, but work to date in biomedical NLP has been limited in terms of corpora and tasks. We present BioALBERT, a domain-specific adaptation of A Lite Bidirectional Encoder Representations from Transformers (ALBERT), trained on biomedical (PubMed and PubMed Central) and clinical (MIMIC-III) corpora and fine tuned for 6 different tasks across 20 benchmark datasets. Experiments show that BioALBERT outperforms the state of the art on named entity recognition (+11.09% BLURB score improvement), relation extraction (+0.80% BLURB score), sentence similarity (+1.05% BLURB score), document classification (+0.62% F1-score), and question answering (+2.83% BLURB score). It represents a new state of the art in 17 out of 20 benchmark datasets. By making BioALBERT models and data available, our aim is to help the biomedical NLP community avoid computational costs of training and establish a new set of baselines for future efforts across a broad range of biomedical NLP tasks.
Clustering and attention model based for Intelligent Trading
Jul 06, 2021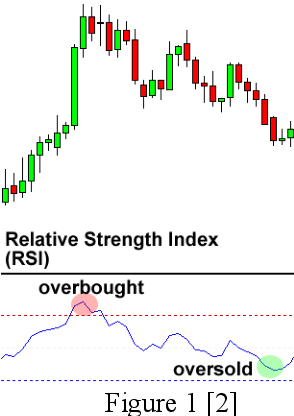



The foreign exchange market has taken an important role in the global financial market. While foreign exchange trading brings high-yield opportunities to investors, it also brings certain risks. Since the establishment of the foreign exchange market in the 20th century, foreign exchange rate forecasting has become a hot issue studied by scholars from all over the world. Due to the complexity and number of factors affecting the foreign exchange market, technical analysis cannot respond to administrative intervention or unexpected events. Our team chose several pairs of foreign currency historical data and derived technical indicators from 2005 to 2021 as the dataset and established different machine learning models for event-driven price prediction for oversold scenario.
Classifying vaccine sentiment tweets by modelling domain-specific representation and commonsense knowledge into context-aware attentive GRU
Jun 17, 2021
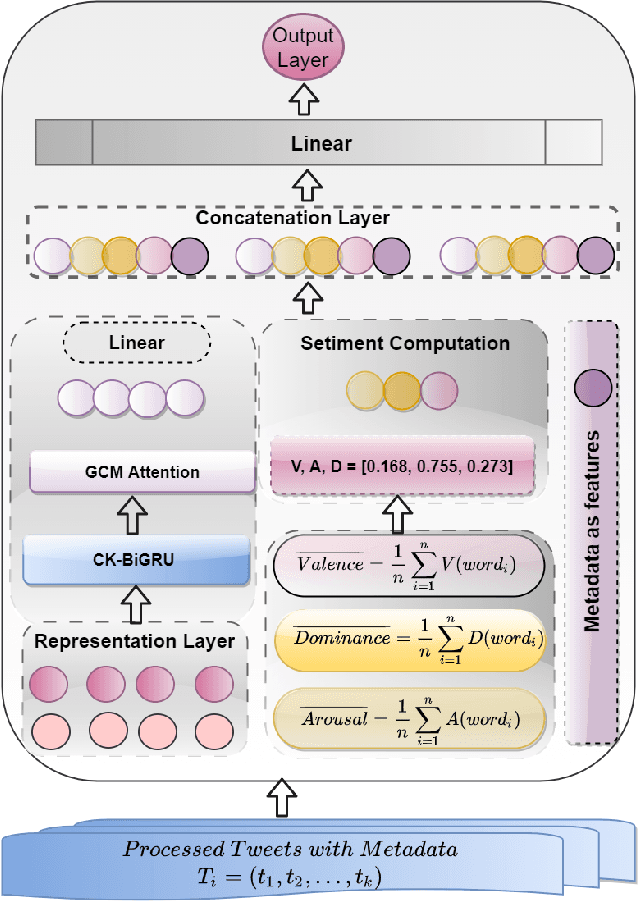
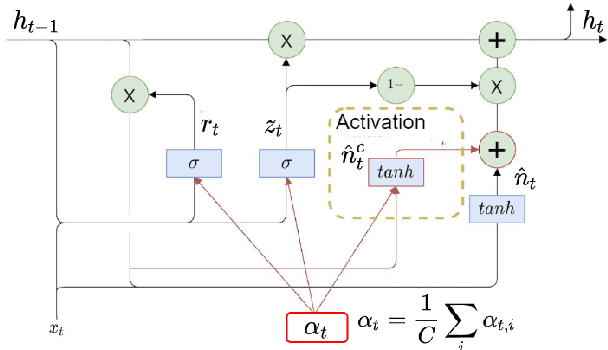
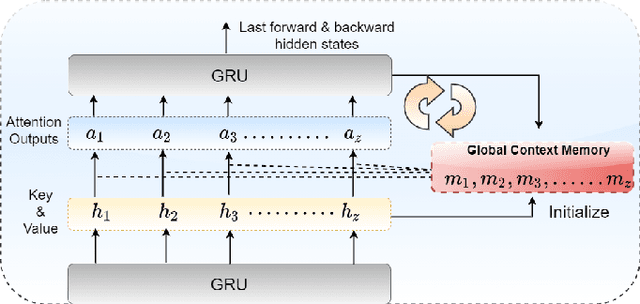
Vaccines are an important public health measure, but vaccine hesitancy and refusal can create clusters of low vaccine coverage and reduce the effectiveness of vaccination programs. Social media provides an opportunity to estimate emerging risks to vaccine acceptance by including geographical location and detailing vaccine-related concerns. Methods for classifying social media posts, such as vaccine-related tweets, use language models (LMs) trained on general domain text. However, challenges to measuring vaccine sentiment at scale arise from the absence of tonal stress and gestural cues and may not always have additional information about the user, e.g., past tweets or social connections. Another challenge in LMs is the lack of commonsense knowledge that are apparent in users metadata, i.e., emoticons, positive and negative words etc. In this study, to classify vaccine sentiment tweets with limited information, we present a novel end-to-end framework consisting of interconnected components that use domain-specific LM trained on vaccine-related tweets and models commonsense knowledge into a bidirectional gated recurrent network (CK-BiGRU) with context-aware attention. We further leverage syntactical, user metadata and sentiment information to capture the sentiment of a tweet. We experimented using two popular vaccine-related Twitter datasets and demonstrate that our proposed approach outperforms state-of-the-art models in identifying pro-vaccine, anti-vaccine and neutral tweets.
SMOTE-ENC: A novel SMOTE-based method to generate synthetic data for nominal and continuous features
Mar 13, 2021



Real world datasets are heavily skewed where some classes are significantly outnumbered by the other classes. In these situations, machine learning algorithms fail to achieve substantial efficacy while predicting these under-represented instances. To solve this problem, many variations of synthetic minority over-sampling methods (SMOTE) have been proposed to balance the dataset which deals with continuous features. However, for datasets with both nominal and continuous features, SMOTE-NC is the only SMOTE-based over-sampling technique to balance the data. In this paper, we present a novel minority over-sampling method, SMOTE-ENC (SMOTE - Encoded Nominal and Continuous), in which, nominal features are encoded as numeric values and the difference between two such numeric value reflects the amount of change of association with minority class. Our experiments show that the classification model using SMOTE-ENC method offers better prediction than model using SMOTE-NC when the dataset has a substantial number of nominal features and also when there is some association between the categorical features and the target class. Additionally, our proposed method addressed one of the major limitations of SMOTE-NC algorithm. SMOTE-NC can be applied only on mixed datasets that have features consisting of both continuous and nominal features and cannot function if all the features of the dataset are nominal. Our novel method has been generalized to be applied on both mixed datasets and on nominal only datasets. The code is available from mkhushi.github.io
Feature Learning for Stock Price Prediction Shows a Significant Role of Analyst Rating
Mar 13, 2021

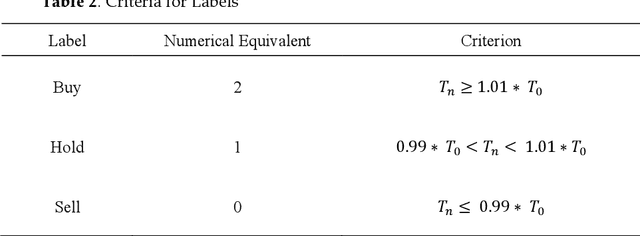
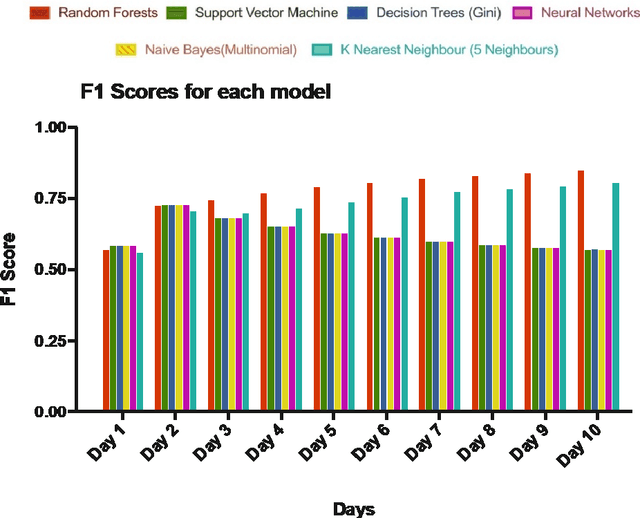
To reject the Efficient Market Hypothesis a set of 5 technical indicators and 23 fundamental indicators was identified to establish the possibility of generating excess returns on the stock market. Leveraging these data points and various classification machine learning models, trading data of the 505 equities on the US S&P500 over the past 20 years was analysed to develop a classifier effective for our cause. From any given day, we were able to predict the direction of change in price by 1% up to 10 days in the future. The predictions had an overall accuracy of 83.62% with a precision of 85% for buy signals and a recall of 100% for sell signals. Moreover, we grouped equities by their sector and repeated the experiment to see if grouping similar assets together positively effected the results but concluded that it showed no significant improvements in the performance rejecting the idea of sector-based analysis. Also, using feature ranking we could identify an even smaller set of 6 indicators while maintaining similar accuracies as that from the original 28 features and also uncovered the importance of buy, hold and sell analyst ratings as they came out to be the top contributors in the model. Finally, to evaluate the effectiveness of the classifier in real-life situations, it was backtested on FAANG equities using a modest trading strategy where it generated high returns of above 60% over the term of the testing dataset. In conclusion, our proposed methodology with the combination of purposefully picked features shows an improvement over the previous studies, and our model predicts the direction of 1% price changes on the 10th day with high confidence and with enough buffer to even build a robotic trading system.
Text Mining of Stocktwits Data for Predicting Stock Prices
Mar 13, 2021


Stock price prediction can be made more efficient by considering the price fluctuations and understanding the sentiments of people. A limited number of models understand financial jargon or have labelled datasets concerning stock price change. To overcome this challenge, we introduced FinALBERT, an ALBERT based model trained to handle financial domain text classification tasks by labelling Stocktwits text data based on stock price change. We collected Stocktwits data for over ten years for 25 different companies, including the major five FAANG (Facebook, Amazon, Apple, Netflix, Google). These datasets were labelled with three labelling techniques based on stock price changes. Our proposed model FinALBERT is fine-tuned with these labels to achieve optimal results. We experimented with the labelled dataset by training it on traditional machine learning, BERT, and FinBERT models, which helped us understand how these labels behaved with different model architectures. Our labelling method competitive advantage is that it can help analyse the historical data effectively, and the mathematical function can be easily customised to predict stock movement.
Portfolio Optimization with 2D Relative-Attentional Gated Transformer
Dec 27, 2020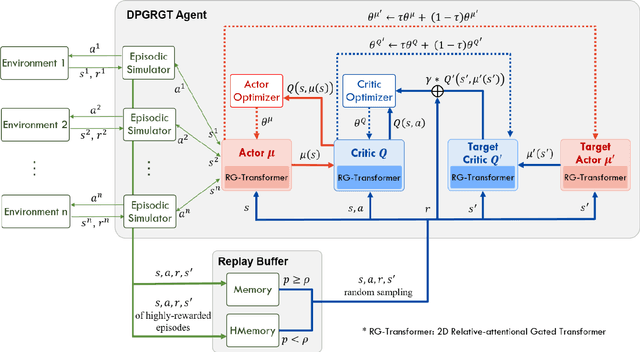

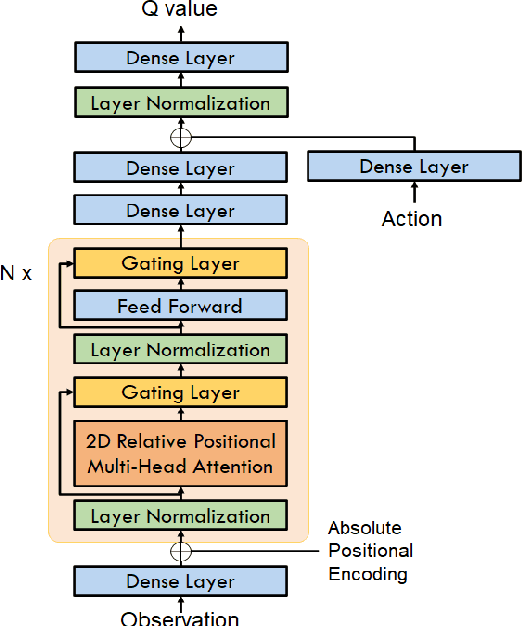
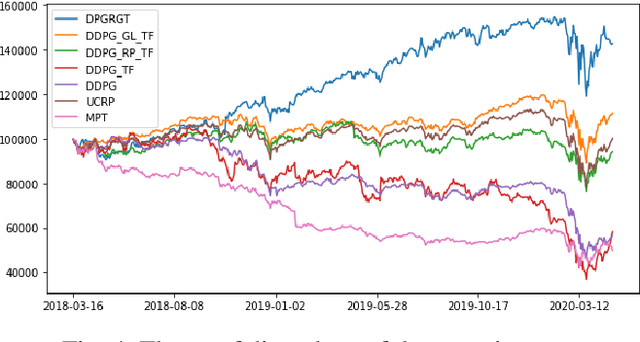
Portfolio optimization is one of the most attentive fields that have been researched with machine learning approaches. Many researchers attempted to solve this problem using deep reinforcement learning due to its efficient inherence that can handle the property of financial markets. However, most of them can hardly be applicable to real-world trading since they ignore or extremely simplify the realistic constraints of transaction costs. These constraints have a significantly negative impact on portfolio profitability. In our research, a conservative level of transaction fees and slippage are considered for the realistic experiment. To enhance the performance under those constraints, we propose a novel Deterministic Policy Gradient with 2D Relative-attentional Gated Transformer (DPGRGT) model. Applying learnable relative positional embeddings for the time and assets axes, the model better understands the peculiar structure of the financial data in the portfolio optimization domain. Also, gating layers and layer reordering are employed for stable convergence of Transformers in reinforcement learning. In our experiment using U.S. stock market data of 20 years, our model outperformed baseline models and demonstrated its effectiveness.
BioALBERT: A Simple and Effective Pre-trained Language Model for Biomedical Named Entity Recognition
Sep 19, 2020
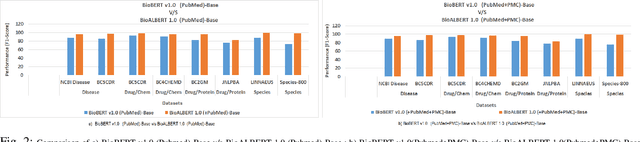
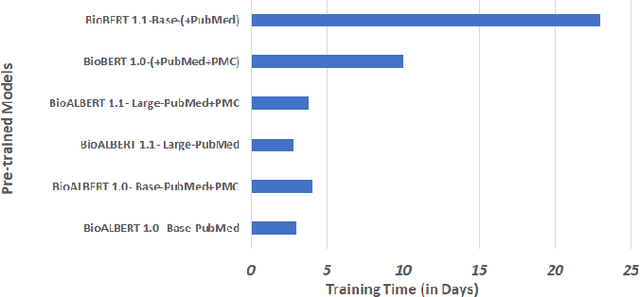

In recent years, with the growing amount of biomedical documents, coupled with advancement in natural language processing algorithms, the research on biomedical named entity recognition (BioNER) has increased exponentially. However, BioNER research is challenging as NER in the biomedical domain are: (i) often restricted due to limited amount of training data, (ii) an entity can refer to multiple types and concepts depending on its context and, (iii) heavy reliance on acronyms that are sub-domain specific. Existing BioNER approaches often neglect these issues and directly adopt the state-of-the-art (SOTA) models trained in general corpora which often yields unsatisfactory results. We propose biomedical ALBERT (A Lite Bidirectional Encoder Representations from Transformers for Biomedical Text Mining) bioALBERT, an effective domain-specific language model trained on large-scale biomedical corpora designed to capture biomedical context-dependent NER. We adopted a self-supervised loss used in ALBERT that focuses on modelling inter-sentence coherence to better learn context-dependent representations and incorporated parameter reduction techniques to lower memory consumption and increase the training speed in BioNER. In our experiments, BioALBERT outperformed comparative SOTA BioNER models on eight biomedical NER benchmark datasets with four different entity types. We trained four different variants of BioALBERT models which are available for the research community to be used in future research.