 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSight-Former: Modeling Structural Differences and Temporal Dynamics for Glaucoma Progression Prediction
Jun 08, 2026Glaucoma is a leading cause of irreversible blindness worldwide, and early detection from fundus images is critical for effective disease management. While deep learning has achieved promising performance in fundus image analysis, most existing methods rely on single time-point images and fail to capture longitudinal structural and vascular changes associated with disease progression. Sequential fundus images acquired during clinical follow-up provide valuable temporal information; however, current sequential models often struggle to detect subtle early progression signals and commonly depend on fixed-length inputs or diagnostic cues from already glaucomatous images, limiting their clinical utility for early prediction. To address these limitations, we propose DiffSight-Former, a framework for glaucoma progression prediction from sequential fundus images. It incorporates a time-variant feature extraction module based on a fundus-specific foundation model to obtain robust anatomical representations. A multi-structure difference modeling module is introduced to quantify progression-related changes in the optic disc/cup region and retinal vasculature. These representations are integrated with temporal interval embeddings and processed by a time-aware Transformer to model disease progression and estimate the probability of future glaucoma onset. Experiments were conducted on two longitudinal datasets, SIGF (405 sequences) and GRAPE (263 sequences). On SIGF, DiffSight-Former achieved an AUC of 91.54% and a sensitivity of 92.16% for progression prediction. On GRAPE, it achieved an average accuracy of 87.48% across three clinical visual-field progression criteria. Compared with existing approaches, DiffSight-Former demonstrates strong performance and robustness across different temporal settings, highlighting its potential for longitudinal glaucoma monitoring and early risk prediction.
EasyLens: A Training-Free Plug-and-Play Subtle-Lesion Representation Amplifier for Medical Vision-Language Models
Jun 04, 2026Medical vision-language models (VLMs) have shown increasing potential for clinical image interpretation, including lesion detection and report generation. However, their practical utility remains limited by insufficient sensitivity to subtle lesions, whose visual evidence is often sparse, low-contrast, and embedded within complex anatomical context. As local visual tokens are aggregated, these weak lesion cues can become underrepresented in global image representations, making them difficult for medical VLMs to recognize. Existing efforts to improve lesion sensitivity mainly rely on medical-domain vision-encoder pre-training, clinical-term-guided alignment, or trainable pathological representation enhancement. Although effective, these approaches usually require additional training or model-specific adaptation and may overfit to particular disease morphologies, limiting their applicability to frozen medical VLMs. To address these limitations, we propose EasyLens, a training-free plug-and-play subtle-lesion representation amplifier for medical VLMs. EasyLens first constructs EasyBank, a pathology-anatomy prototype space that provides lesion-related prototypes and anatomy-aware normal references for comparing suspicious patches against both pathological and normal anatomical patterns. To avoid blindly amplifying normal tissues, EasyTag selects lesion-relevant patches through counterfactual prototype reasoning. To counteract the dilution of subtle lesion cues in global image representations, EasyAmplifier strengthens the selected lesion-relevant patch representations through morphology-guided residual enhancement, thereby increasing their contribution to the global image embedding. Experiments on multiple medical image datasets and frozen medical VLM backbones show that EasyLens improves subtle-lesion detection and outperforms existing encoder-enhancement baselines.
HyDAR-Pano3D: A Hybrid Disentangled Anatomical Recovery Framework for Panoramic-to-3D Reconstruction
May 20, 2026Panoramic radiograph (PR) is fundamentally used in routine dental care, but it inherently provides only a two-dimensional (2D) projection of complex three-dimensional (3D) craniofacial anatomy. Most existing learning-based methods attempt to computationally recover this 3D information by directly regressing native cone-beam computed tomography (CBCT) volumes from PR. However, this direct mapping requires the model to simultaneously learn common anatomical structures and patient-specific morphological variations. This entangled formulation makes the ill-posed 2D-to-3D inverse problem highly ambiguous, often producing over-smoothed reconstructions with blurred anatomical boundaries. To address this, we propose HyDAR-Pano3D, a two-stage framework that reformulates PR-to-CBCT reconstruction as a disentangled anatomical recovery problem. In Stage 1, a dual-encoder network integrates radiographic features with SAM-derived semantic priors to reconstruct an arch-normalized canonical volume. In Stage 2, an Anatomical Restoration Network predicts a prior-constrained structured deformation field to map this canonical volume back to the native space, restoring individual morphological variations. Experiments on three large-scale datasets show that HyDAR-Pano3D significantly outperforms baseline methods ($p < 0.05$), achieving a 25.76 dB PSNR, 85.70\% SSIM, and an 83.83\% overall anatomical Dice score. The synthesized volumes successfully support downstream segmentation of whole teeth (82.4\% Dice) and the inferior alveolar canal (72.2\% Dice), demonstrating that our disentangled approach preserves clinically relevant structures to enable robust anatomy-aware assessment when CBCT data is unavailable.
Patient4D: Temporally Consistent Patient Body Mesh Recovery from Monocular Operating Room Video
Mar 17, 2026Recovering a dense 3D body mesh from monocular video remains challenging under occlusion from draping and continuously moving camera viewpoints. This configuration arises in surgical augmented reality (AR), where an anesthetized patient lies under surgical draping while a surgeon's head-mounted camera continuously changes viewpoint. Existing human mesh recovery (HMR) methods are typically trained on upright, moving subjects captured from relatively stable cameras, leading to performance degradation under such conditions. To address this, we present Patient4D, a stationarity-constrained reconstruction pipeline that explicitly exploits the stationarity prior. The pipeline combines image-level foundation models for perception with lightweight geometric mechanisms that enforce temporal consistency across frames. Two key components enable robust reconstruction: Pose Locking, which anchors pose parameters using stable keyframes, and Rigid Fallback, which recovers meshes under severe occlusion through silhouette-guided rigid alignment. Together, these mechanisms stabilize predictions while remaining compatible with off-the-shelf HMR models. We evaluate Patient4D on 4,680 synthetic surgical sequences and three public HMR video benchmarks. Under surgical drape occlusion, Patient4D achieves a 0.75 mean IoU, reducing failure frames from 30.5% to 1.3% compared to the best baseline. Our findings demonstrate that exploiting stationarity priors can substantially improve monocular reconstruction in clinical AR scenarios.
Beyond Calibration: Confounding Pathology Limits Foundation Model Specificity in Abdominal Trauma CT
Feb 10, 2026Purpose: Translating foundation models into clinical practice requires evaluating their performance under compound distribution shift, where severe class imbalance coexists with heterogeneous imaging appearances. This challenge is relevant for traumatic bowel injury, a rare but high-mortality diagnosis. We investigated whether specificity deficits in foundation models are associated with heterogeneity in the negative class. Methods: This retrospective study used the multi-institutional, RSNA Abdominal Traumatic Injury CT dataset (2019-2023), comprising scans from 23 centres. Two foundation models (MedCLIP, zero-shot; RadDINO, linear probe) were compared against three task-specific approaches (CNN, Transformer, Ensemble). Models were trained on 3,147 patients (2.3% bowel injury prevalence) and evaluated on an enriched 100-patient test set. To isolate negative-class effects, specificity was assessed in patients without bowel injury who had concurrent solid organ injury (n=58) versus no abdominal pathology (n=50). Results: Foundation models achieved equivalent discrimination to task-specific models (AUC, 0.64-0.68 versus 0.58-0.64) with higher sensitivity (79-91% vs 41-74%) but lower specificity (33-50% vs 50-88%). All models demonstrated high specificity in patients without abdominal pathology (84-100%). When solid organ injuries were present, specificity declined substantially for foundation models (50-51 percentage points) compared with smaller reductions of 12-41 percentage points for task-specific models. Conclusion: Foundation models matched task-specific discrimination without task-specific training, but their specificity deficits were driven primarily by confounding negative-class heterogeneity rather than prevalence alone. Susceptibility to negative-class heterogeneity decreased progressively with labelled training, suggesting adaptation is required before clinical implementation.
HyperWalker: Dynamic Hypergraph-Based Deep Diagnosis for Multi-Hop Clinical Modeling across EHR and X-Ray in Medical VLMs
Jan 20, 2026Automated clinical diagnosis remains a core challenge in medical AI, which usually requires models to integrate multi-modal data and reason across complex, case-specific contexts. Although recent methods have advanced medical report generation (MRG) and visual question answering (VQA) with medical vision-language models (VLMs), these methods, however, predominantly operate under a sample-isolated inference paradigm, as such processing cases independently without access to longitudinal electronic health records (EHRs) or structurally related patient examples. This paradigm limits reasoning to image-derived information alone, which ignores external complementary medical evidence for potentially more accurate diagnosis. To overcome this limitation, we propose \textbf{HyperWalker}, a \textit{Deep Diagnosis} framework that reformulates clinical reasoning via dynamic hypergraphs and test-time training. First, we construct a dynamic hypergraph, termed \textbf{iBrochure}, to model the structural heterogeneity of EHR data and implicit high-order associations among multimodal clinical information. Within this hypergraph, a reinforcement learning agent, \textbf{Walker}, navigates to and identifies optimal diagnostic paths. To ensure comprehensive coverage of diverse clinical characteristics in test samples, we incorporate a \textit{linger mechanism}, a multi-hop orthogonal retrieval strategy that iteratively selects clinically complementary neighborhood cases reflecting distinct clinical attributes. Experiments on MRG with MIMIC and medical VQA on EHRXQA demonstrate that HyperWalker achieves state-of-the-art performance. Code is available at: https://github.com/Bean-Young/HyperWalker
Intersectional Fairness in Vision-Language Models for Medical Image Disease Classification
Dec 24, 2025Medical artificial intelligence (AI) systems, particularly multimodal vision-language models (VLM), often exhibit intersectional biases where models are systematically less confident in diagnosing marginalised patient subgroups. Such bias can lead to higher rates of inaccurate and missed diagnoses due to demographically skewed data and divergent distributions of diagnostic certainty. Current fairness interventions frequently fail to address these gaps or compromise overall diagnostic performance to achieve statistical parity among the subgroups. In this study, we developed Cross-Modal Alignment Consistency (CMAC-MMD), a training framework that standardises diagnostic certainty across intersectional patient subgroups. Unlike traditional debiasing methods, this approach equalises the model's decision confidence without requiring sensitive demographic data during clinical inference. We evaluated this approach using 10,015 skin lesion images (HAM10000) with external validation on 12,000 images (BCN20000), and 10,000 fundus images for glaucoma detection (Harvard-FairVLMed), stratifying performance by intersectional age, gender, and race attributes. In the dermatology cohort, the proposed method reduced the overall intersectional missed diagnosis gap (difference in True Positive Rate, $Δ$TPR) from 0.50 to 0.26 while improving the overall Area Under the Curve (AUC) from 0.94 to 0.97 compared to standard training. Similarly, for glaucoma screening, the method reduced $Δ$TPR from 0.41 to 0.31, achieving a better AUC of 0.72 (vs. 0.71 baseline). This establishes a scalable framework for developing high-stakes clinical decision support systems that are both accurate and can perform equitably across diverse patient subgroups, ensuring reliable performance without increasing privacy risks.
MRG-R1: Reinforcement Learning for Clinically Aligned Medical Report Generation
Dec 18, 2025Medical report generation (MRG) aims to automatically derive radiology-style reports from medical images to aid in clinical decision-making. However, existing methods often generate text that mimics the linguistic style of radiologists but fails to guarantee clinical correctness, because they are trained on token-level objectives which focus on word-choice and sentence structure rather than actual medical accuracy. We propose a semantic-driven reinforcement learning (SRL) method for medical report generation, adopted on a large vision-language model (LVLM). SRL adopts Group Relative Policy Optimization (GRPO) to encourage clinical-correctness-guided learning beyond imitation of language style. Specifically, we optimise a report-level reward: a margin-based cosine similarity (MCCS) computed between key radiological findings extracted from generated and reference reports, thereby directly aligning clinical-label agreement and improving semantic correctness. A lightweight reasoning format constraint further guides the model to generate structured "thinking report" outputs. We evaluate Medical Report Generation with Sematic-driven Reinforment Learning (MRG-R1), on two datasets: IU X-Ray and MIMIC-CXR using clinical efficacy (CE) metrics. MRG-R1 achieves state-of-the-art performance with CE-F1 51.88 on IU X-Ray and 40.39 on MIMIC-CXR. We found that the label-semantic reinforcement is better than conventional token-level supervision. These results indicate that optimizing a clinically grounded, report-level reward rather than token overlap,meaningfully improves clinical correctness. This work is a prior to explore semantic-reinforcement in supervising medical correctness in medical Large vision-language model(Med-LVLM) training.
MRGAgents: A Multi-Agent Framework for Improved Medical Report Generation with Med-LVLMs
May 24, 2025Medical Large Vision-Language Models (Med-LVLMs) have been widely adopted for medical report generation. Despite Med-LVLMs producing state-of-the-art performance, they exhibit a bias toward predicting all findings as normal, leading to reports that overlook critical abnormalities. Furthermore, these models often fail to provide comprehensive descriptions of radiologically relevant regions necessary for accurate diagnosis. To address these challenges, we proposeMedical Report Generation Agents (MRGAgents), a novel multi-agent framework that fine-tunes specialized agents for different disease categories. By curating subsets of the IU X-ray and MIMIC-CXR datasets to train disease-specific agents, MRGAgents generates reports that more effectively balance normal and abnormal findings while ensuring a comprehensive description of clinically relevant regions. Our experiments demonstrate that MRGAgents outperformed the state-of-the-art, improving both report comprehensiveness and diagnostic utility.
MedCFVQA: A Causal Approach to Mitigate Modality Preference Bias in Medical Visual Question Answering
May 23, 2025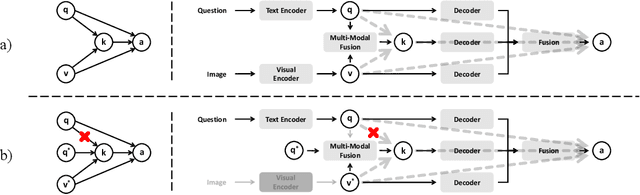
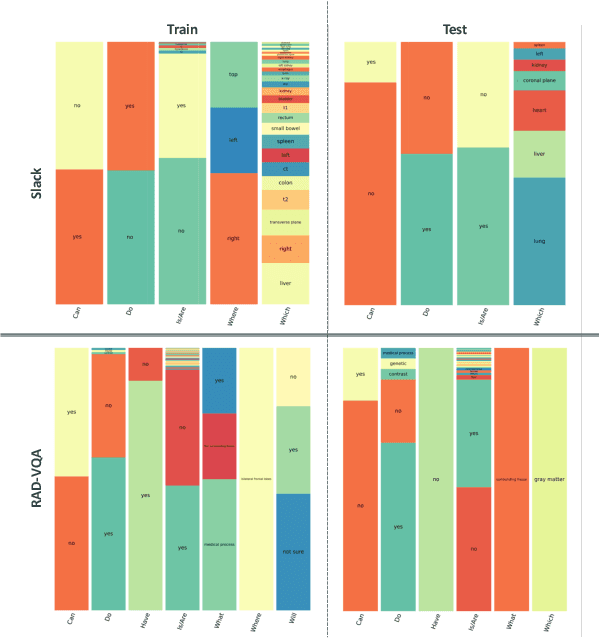
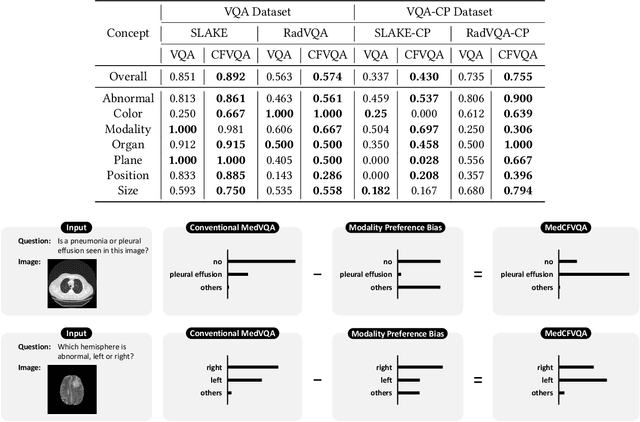
Medical Visual Question Answering (MedVQA) is crucial for enhancing the efficiency of clinical diagnosis by providing accurate and timely responses to clinicians' inquiries regarding medical images. Existing MedVQA models suffered from modality preference bias, where predictions are heavily dominated by one modality while overlooking the other (in MedVQA, usually questions dominate the answer but images are overlooked), thereby failing to learn multimodal knowledge. To overcome the modality preference bias, we proposed a Medical CounterFactual VQA (MedCFVQA) model, which trains with bias and leverages causal graphs to eliminate the modality preference bias during inference. Existing MedVQA datasets exhibit substantial prior dependencies between questions and answers, which results in acceptable performance even if the model significantly suffers from the modality preference bias. To address this issue, we reconstructed new datasets by leveraging existing MedVQA datasets and Changed their P3rior dependencies (CP) between questions and their answers in the training and test set. Extensive experiments demonstrate that MedCFVQA significantly outperforms its non-causal counterpart on both SLAKE, RadVQA and SLAKE-CP, RadVQA-CP datasets.