 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEad and neCK TumOR (HECKTOR) 2025: Benchmark of Segmentation, Diagnosis, and Prognosis in Multimodal PET/CT
Jun 18, 2026Head and neck cancers (HNC) represent a significant global health burden, with accurate tumor delineation being essential for effective radiotherapy planning. The complexity of the oropharyngeal anatomy, combined with the heterogeneous appearance of tumors on imaging, makes manual segmentation time-intensive and subject to inter-observer variability. Beyond segmentation, predicting long-term clinical outcomes, such as recurrence-free survival (RFS), and determining human papillomavirus (HPV) status from noninvasive imaging, remain challenging yet clinically valuable goals. The HECKTOR 2025 challenge addresses these needs by establishing a comprehensive benchmark for automated HNC analysis using multimodal PET/CT imaging and electronic health records. Building on previous editions (2020-2022), this challenge features an expanded multi-institutional dataset comprising over 1,100 patients from 10 centers worldwide. Participants were tasked with three complementary objectives: (1) segmenting primary gross tumor volumes (GTVp) and metastatic lymph nodes (GTVn), (2) predicting recurrence-free survival, and (3) classifying HPV status. The challenge attracted 35 registered teams, with 15 final submissions evaluated on a held-out test set. Top-performing algorithms achieved a mean Dice similarity coefficient of 0.75 for segmentation, a concordance index of 0.66 for survival prediction, and a balanced accuracy of 0.56 for HPV classification. This paper presents a comprehensive analysis of the submitted methodologies, evaluates their performance across different lesion characteristics, and discusses their implications for clinical translation in automated oncology workflows and decision support systems.
Towards World Models in Biomedical Research
Jun 04, 2026A central goal of biomedicine is to understand, predict and ultimately control the dynamic mechanisms by which biological systems respond to perturbations, disease progression and therapeutic intervention. Although foundation models and large language models have accelerated biomedical data interpretation, most current systems remain focused on static pattern recognition rather than prospective simulation of biological futures. Here we propose biomedical world models as a paradigm for AI-driven discovery. These models learn latent representations of molecular, cellular, tissue and clinical states, together with intervention-conditioned dynamics that allow future trajectories to be simulated before actions are taken. We discuss how biomedical world models could function as data engines, environment simulators and scientific planning substrates across applications including virtual cells, organoids, virtual patients and surgical simulation. We outline the data infrastructure, evaluation benchmarks, safety constraints and governance frameworks required. Biomedical world models may provide a foundation for simulation-guided, closed-loop and experimentally actionable biomedical discovery.
MedCFVQA: A Causal Approach to Mitigate Modality Preference Bias in Medical Visual Question Answering
May 23, 2025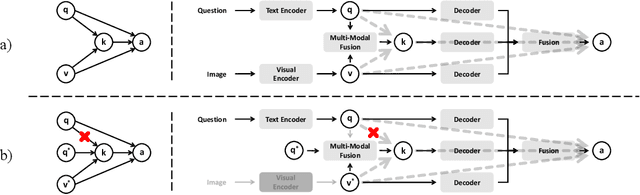
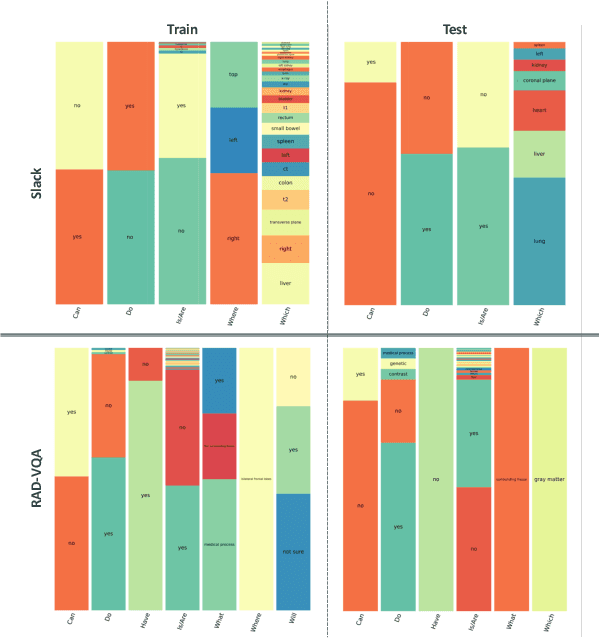
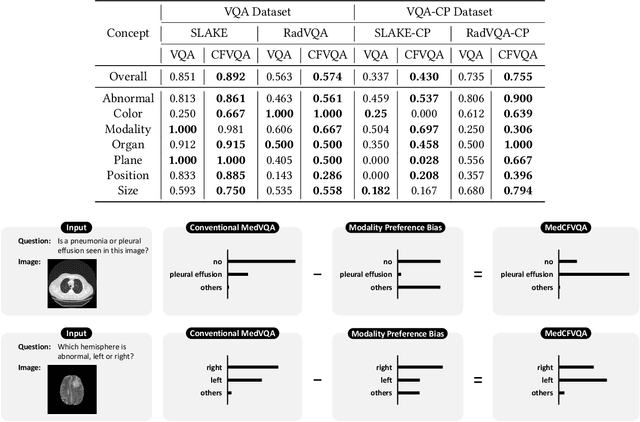
Medical Visual Question Answering (MedVQA) is crucial for enhancing the efficiency of clinical diagnosis by providing accurate and timely responses to clinicians' inquiries regarding medical images. Existing MedVQA models suffered from modality preference bias, where predictions are heavily dominated by one modality while overlooking the other (in MedVQA, usually questions dominate the answer but images are overlooked), thereby failing to learn multimodal knowledge. To overcome the modality preference bias, we proposed a Medical CounterFactual VQA (MedCFVQA) model, which trains with bias and leverages causal graphs to eliminate the modality preference bias during inference. Existing MedVQA datasets exhibit substantial prior dependencies between questions and answers, which results in acceptable performance even if the model significantly suffers from the modality preference bias. To address this issue, we reconstructed new datasets by leveraging existing MedVQA datasets and Changed their P3rior dependencies (CP) between questions and their answers in the training and test set. Extensive experiments demonstrate that MedCFVQA significantly outperforms its non-causal counterpart on both SLAKE, RadVQA and SLAKE-CP, RadVQA-CP datasets.
A Causal Approach to Mitigate Modality Preference Bias in Medical Visual Question Answering
May 22, 2025Medical Visual Question Answering (MedVQA) is crucial for enhancing the efficiency of clinical diagnosis by providing accurate and timely responses to clinicians' inquiries regarding medical images. Existing MedVQA models suffered from modality preference bias, where predictions are heavily dominated by one modality while overlooking the other (in MedVQA, usually questions dominate the answer but images are overlooked), thereby failing to learn multimodal knowledge. To overcome the modality preference bias, we proposed a Medical CounterFactual VQA (MedCFVQA) model, which trains with bias and leverages causal graphs to eliminate the modality preference bias during inference. Existing MedVQA datasets exhibit substantial prior dependencies between questions and answers, which results in acceptable performance even if the model significantly suffers from the modality preference bias. To address this issue, we reconstructed new datasets by leveraging existing MedVQA datasets and Changed their P3rior dependencies (CP) between questions and their answers in the training and test set. Extensive experiments demonstrate that MedCFVQA significantly outperforms its non-causal counterpart on both SLAKE, RadVQA and SLAKE-CP, RadVQA-CP datasets.
Advancing Deformable Medical Image Registration with Multi-axis Cross-covariance Attention
Dec 24, 2024



Deformable image registration is a fundamental requirement for medical image analysis. Recently, transformers have been widely used in deep learning-based registration methods for their ability to capture long-range dependency via self-attention (SA). However, the high computation and memory loads of SA (growing quadratically with the spatial resolution) hinder transformers from processing subtle textural information in high-resolution image features, e.g., at the full and half image resolutions. This limits deformable registration as the high-resolution textural information is crucial for finding precise pixel-wise correspondence between subtle anatomical structures. Cross-covariance Attention (XCA), as a "transposed" version of SA that operates across feature channels, has complexity growing linearly with the spatial resolution, providing the feasibility of capturing long-range dependency among high-resolution image features. However, existing XCA-based transformers merely capture coarse global long-range dependency, which are unsuitable for deformable image registration relying primarily on fine-grained local correspondence. In this study, we propose to improve existing deep learning-based registration methods by embedding a new XCA mechanism. To this end, we design an XCA-based transformer block optimized for deformable medical image registration, named Multi-Axis XCA (MAXCA). Our MAXCA serves as a general network block that can be embedded into various registration network architectures. It can capture both global and local long-range dependency among high-resolution image features by applying regional and dilated XCA in parallel via a multi-axis design. Extensive experiments on two well-benchmarked inter-/intra-patient registration tasks with seven public medical datasets demonstrate that our MAXCA block enables state-of-the-art registration performance.
Language-guided Medical Image Segmentation with Target-informed Multi-level Contrastive Alignments
Dec 18, 2024
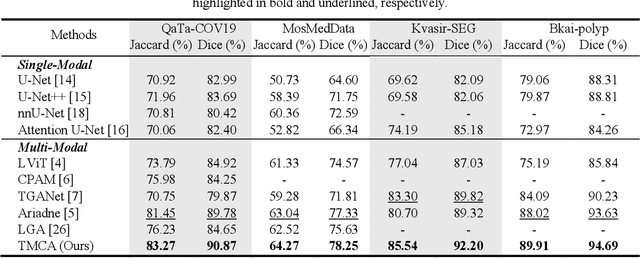
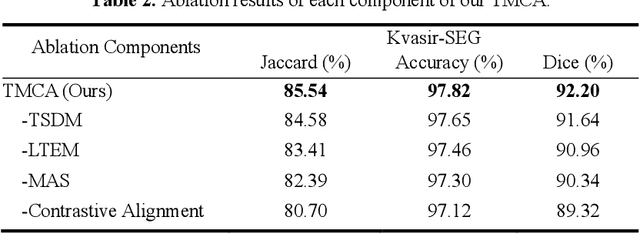
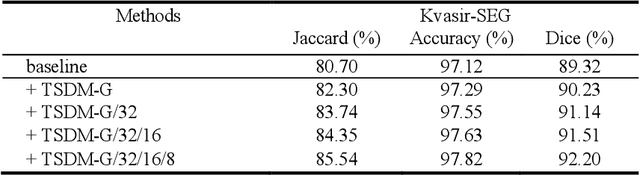
Medical image segmentation is crucial in modern medical image analysis, which can aid into diagnosis of various disease conditions. Recently, language-guided segmentation methods have shown promising results in automating image segmentation where text reports are incorporated as guidance. These text reports, containing image impressions and insights given by clinicians, provides auxiliary guidance. However, these methods neglect the inherent pattern gaps between the two distinct modalities, which leads to sub-optimal image-text feature fusion without proper cross-modality feature alignments. Contrastive alignments are widely used to associate image-text semantics in representation learning; however, it has not been exploited to bridge the pattern gaps in language-guided segmentation that relies on subtle low level image details to represent diseases. Existing contrastive alignment methods typically algin high-level global image semantics without involving low-level, localized target information, and therefore fails to explore fine-grained text guidance for language-guided segmentation. In this study, we propose a language-guided segmentation network with Target-informed Multi-level Contrastive Alignments (TMCA). TMCA enables target-informed cross-modality alignments and fine-grained text guidance to bridge the pattern gaps in language-guided segmentation. Specifically, we introduce: 1) a target-sensitive semantic distance module that enables granular image-text alignment modelling, and 2) a multi-level alignment strategy that directs text guidance on low-level image features. In addition, a language-guided target enhancement module is proposed to leverage the aligned text to redirect attention to focus on critical localized image features. Extensive experiments on 4 image-text datasets, involving 3 medical imaging modalities, demonstrated that our TMCA achieved superior performances.
3DPX: Single Panoramic X-ray Analysis Guided by 3D Oral Structure Reconstruction
Sep 27, 2024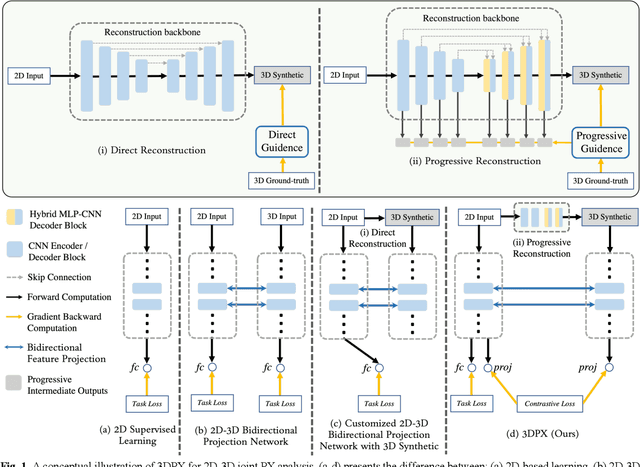
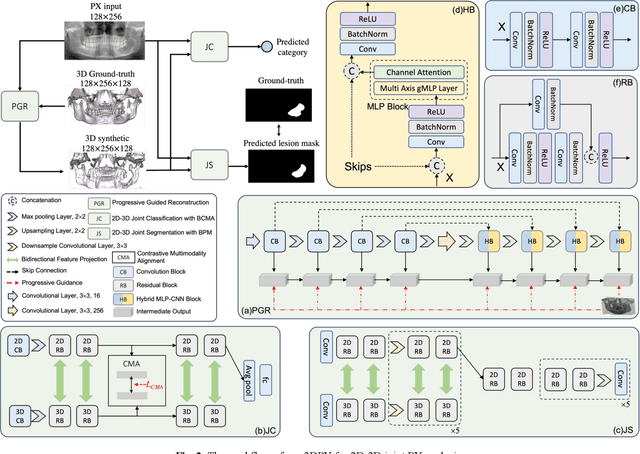
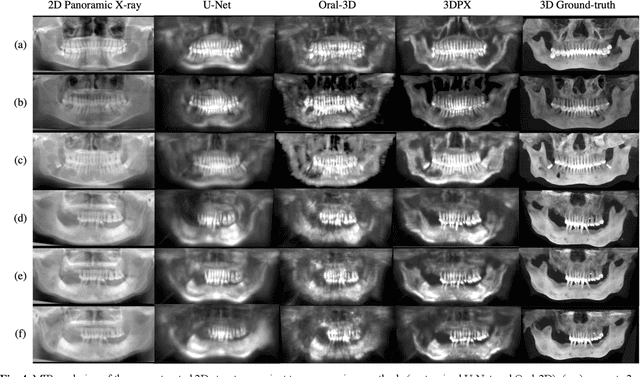
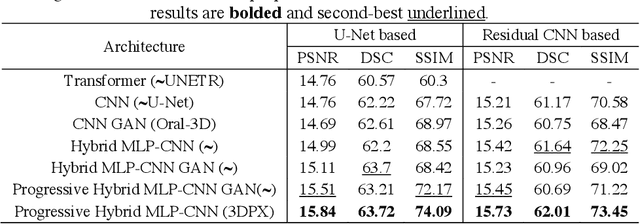
Panoramic X-ray (PX) is a prevalent modality in dentistry practice owing to its wide availability and low cost. However, as a 2D projection of a 3D structure, PX suffers from anatomical information loss and PX diagnosis is limited compared to that with 3D imaging modalities. 2D-to-3D reconstruction methods have been explored for the ability to synthesize the absent 3D anatomical information from 2D PX for use in PX image analysis. However, there are challenges in leveraging such 3D synthesized reconstructions. First, inferring 3D depth from 2D images remains a challenging task with limited accuracy. The second challenge is the joint analysis of 2D PX with its 3D synthesized counterpart, with the aim to maximize the 2D-3D synergy while minimizing the errors arising from the synthesized image. In this study, we propose a new method termed 3DPX - PX image analysis guided by 2D-to-3D reconstruction, to overcome these challenges. 3DPX consists of (i) a novel progressive reconstruction network to improve 2D-to-3D reconstruction and, (ii) a contrastive-guided bidirectional multimodality alignment module for 3D-guided 2D PX classification and segmentation tasks. The reconstruction network progressively reconstructs 3D images with knowledge imposed on the intermediate reconstructions at multiple pyramid levels and incorporates Multilayer Perceptrons to improve semantic understanding. The downstream networks leverage the reconstructed images as 3D anatomical guidance to the PX analysis through feature alignment, which increases the 2D-3D synergy with bidirectional feature projection and decease the impact of potential errors with contrastive guidance. Extensive experiments on two oral datasets involving 464 studies demonstrate that 3DPX outperforms the state-of-the-art methods in various tasks including 2D-to-3D reconstruction, PX classification and lesion segmentation.
SGSeg: Enabling Text-free Inference in Language-guided Segmentation of Chest X-rays via Self-guidance
Sep 07, 2024Segmentation of infected areas in chest X-rays is pivotal for facilitating the accurate delineation of pulmonary structures and pathological anomalies. Recently, multi-modal language-guided image segmentation methods have emerged as a promising solution for chest X-rays where the clinical text reports, depicting the assessment of the images, are used as guidance. Nevertheless, existing language-guided methods require clinical reports alongside the images, and hence, they are not applicable for use in image segmentation in a decision support context, but rather limited to retrospective image analysis after clinical reporting has been completed. In this study, we propose a self-guided segmentation framework (SGSeg) that leverages language guidance for training (multi-modal) while enabling text-free inference (uni-modal), which is the first that enables text-free inference in language-guided segmentation. We exploit the critical location information of both pulmonary and pathological structures depicted in the text reports and introduce a novel localization-enhanced report generation (LERG) module to generate clinical reports for self-guidance. Our LERG integrates an object detector and a location-based attention aggregator, weakly-supervised by a location-aware pseudo-label extraction module. Extensive experiments on a well-benchmarked QaTa-COV19 dataset demonstrate that our SGSeg achieved superior performance than existing uni-modal segmentation methods and closely matched the state-of-the-art performance of multi-modal language-guided segmentation methods.
3DPX: Progressive 2D-to-3D Oral Image Reconstruction with Hybrid MLP-CNN Networks
Aug 02, 2024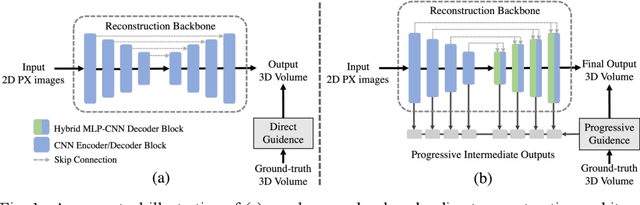
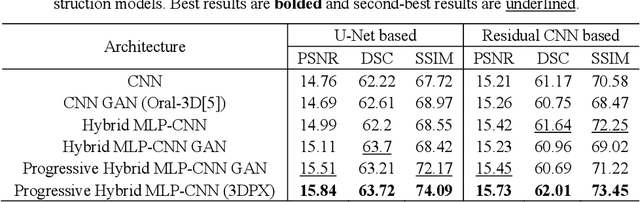
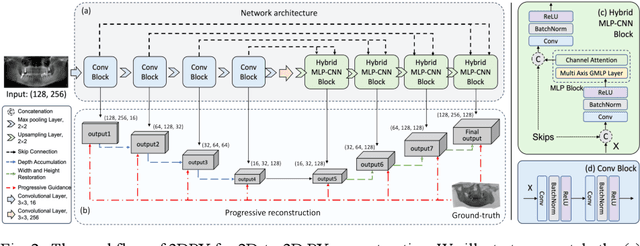
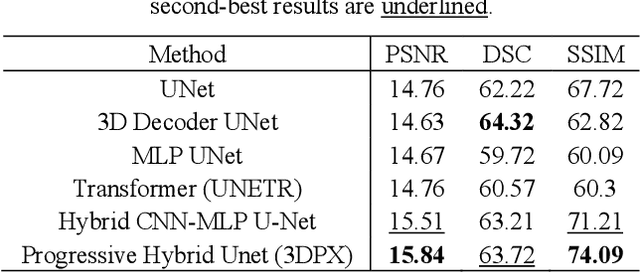
Panoramic X-ray (PX) is a prevalent modality in dental practice for its wide availability and low cost. However, as a 2D projection image, PX does not contain 3D anatomical information, and therefore has limited use in dental applications that can benefit from 3D information, e.g., tooth angular misa-lignment detection and classification. Reconstructing 3D structures directly from 2D PX has recently been explored to address limitations with existing methods primarily reliant on Convolutional Neural Networks (CNNs) for direct 2D-to-3D mapping. These methods, however, are unable to correctly infer depth-axis spatial information. In addition, they are limited by the in-trinsic locality of convolution operations, as the convolution kernels only capture the information of immediate neighborhood pixels. In this study, we propose a progressive hybrid Multilayer Perceptron (MLP)-CNN pyra-mid network (3DPX) for 2D-to-3D oral PX reconstruction. We introduce a progressive reconstruction strategy, where 3D images are progressively re-constructed in the 3DPX with guidance imposed on the intermediate recon-struction result at each pyramid level. Further, motivated by the recent ad-vancement of MLPs that show promise in capturing fine-grained long-range dependency, our 3DPX integrates MLPs and CNNs to improve the semantic understanding during reconstruction. Extensive experiments on two large datasets involving 464 studies demonstrate that our 3DPX outperforms state-of-the-art 2D-to-3D oral reconstruction methods, including standalone MLP and transformers, in reconstruction quality, and also im-proves the performance of downstream angular misalignment classification tasks.
Correlation-aware Coarse-to-fine MLPs for Deformable Medical Image Registration
May 31, 2024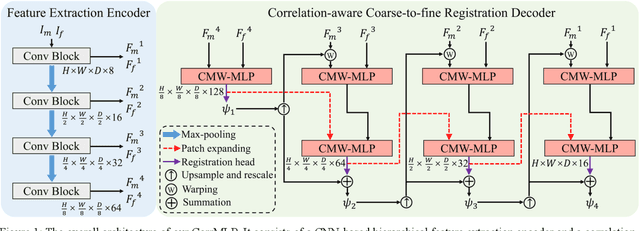
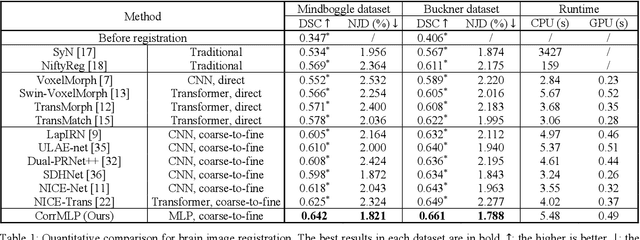
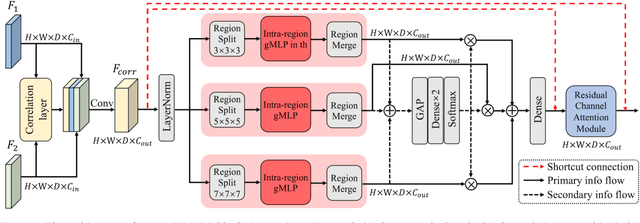
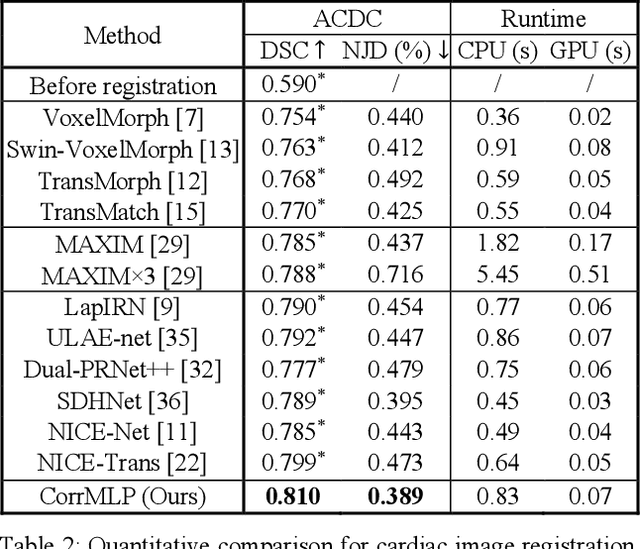
Deformable image registration is a fundamental step for medical image analysis. Recently, transformers have been used for registration and outperformed Convolutional Neural Networks (CNNs). Transformers can capture long-range dependence among image features, which have been shown beneficial for registration. However, due to the high computation/memory loads of self-attention, transformers are typically used at downsampled feature resolutions and cannot capture fine-grained long-range dependence at the full image resolution. This limits deformable registration as it necessitates precise dense correspondence between each image pixel. Multi-layer Perceptrons (MLPs) without self-attention are efficient in computation/memory usage, enabling the feasibility of capturing fine-grained long-range dependence at full resolution. Nevertheless, MLPs have not been extensively explored for image registration and are lacking the consideration of inductive bias crucial for medical registration tasks. In this study, we propose the first correlation-aware MLP-based registration network (CorrMLP) for deformable medical image registration. Our CorrMLP introduces a correlation-aware multi-window MLP block in a novel coarse-to-fine registration architecture, which captures fine-grained multi-range dependence to perform correlation-aware coarse-to-fine registration. Extensive experiments with seven public medical datasets show that our CorrMLP outperforms state-of-the-art deformable registration methods.