 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAISY: Motion-Aware Image SYnthesis for Medical Image Motion Correction
May 08, 2025Patient motion during medical image acquisition causes blurring, ghosting, and distorts organs, which makes image interpretation challenging. Current state-of-the-art algorithms using Generative Adversarial Network (GAN)-based methods with their ability to learn the mappings between corrupted images and their ground truth via Structural Similarity Index Measure (SSIM) loss effectively generate motion-free images. However, we identified the following limitations: (i) they mainly focus on global structural characteristics and therefore overlook localized features that often carry critical pathological information, and (ii) the SSIM loss function struggles to handle images with varying pixel intensities, luminance factors, and variance. In this study, we propose Motion-Aware Image SYnthesis (MAISY) which initially characterize motion and then uses it for correction by: (a) leveraging the foundation model Segment Anything Model (SAM), to dynamically learn spatial patterns along anatomical boundaries where motion artifacts are most pronounced and, (b) introducing the Variance-Selective SSIM (VS-SSIM) loss which adaptively emphasizes spatial regions with high pixel variance to preserve essential anatomical details during artifact correction. Experiments on chest and head CT datasets demonstrate that our model outperformed the state-of-the-art counterparts, with Peak Signal-to-Noise Ratio (PSNR) increasing by 40%, SSIM by 10%, and Dice by 16%.
Advancing Deformable Medical Image Registration with Multi-axis Cross-covariance Attention
Dec 24, 2024



Deformable image registration is a fundamental requirement for medical image analysis. Recently, transformers have been widely used in deep learning-based registration methods for their ability to capture long-range dependency via self-attention (SA). However, the high computation and memory loads of SA (growing quadratically with the spatial resolution) hinder transformers from processing subtle textural information in high-resolution image features, e.g., at the full and half image resolutions. This limits deformable registration as the high-resolution textural information is crucial for finding precise pixel-wise correspondence between subtle anatomical structures. Cross-covariance Attention (XCA), as a "transposed" version of SA that operates across feature channels, has complexity growing linearly with the spatial resolution, providing the feasibility of capturing long-range dependency among high-resolution image features. However, existing XCA-based transformers merely capture coarse global long-range dependency, which are unsuitable for deformable image registration relying primarily on fine-grained local correspondence. In this study, we propose to improve existing deep learning-based registration methods by embedding a new XCA mechanism. To this end, we design an XCA-based transformer block optimized for deformable medical image registration, named Multi-Axis XCA (MAXCA). Our MAXCA serves as a general network block that can be embedded into various registration network architectures. It can capture both global and local long-range dependency among high-resolution image features by applying regional and dilated XCA in parallel via a multi-axis design. Extensive experiments on two well-benchmarked inter-/intra-patient registration tasks with seven public medical datasets demonstrate that our MAXCA block enables state-of-the-art registration performance.
Hyper-Fusion Network for Semi-Automatic Segmentation of Skin Lesions
Dec 14, 2024Automatic skin lesion segmentation methods based on fully convolutional networks (FCNs) are regarded as the state-of-the-art for accuracy. When there are, however, insufficient training data to cover all the variations in skin lesions, where lesions from different patients may have major differences in size/shape/texture, these methods failed to segment the lesions that have image characteristics, which are less common in the training datasets. FCN-based semi-automatic segmentation methods, which fuse user-inputs with high-level semantic image features derived from FCNs offer an ideal complement to overcome limitations of automatic segmentation methods. These semi-automatic methods rely on the automated state-of-the-art FCNs coupled with user-inputs for refinements, and therefore being able to tackle challenging skin lesions. However, there are a limited number of FCN-based semi-automatic segmentation methods and all these methods focused on early-fusion, where the first few convolutional layers are used to fuse image features and user-inputs and then derive fused image features for segmentation. For early-fusion based methods, because the user-input information can be lost after the first few convolutional layers, consequently, the user-input information will have limited guidance and constraint in segmenting the challenging skin lesions with inhomogeneous textures and fuzzy boundaries. Hence, in this work, we introduce a hyper-fusion network (HFN) to fuse the extracted user-inputs and image features over multiple stages. We separately extract complementary features which then allows for an iterative use of user-inputs along all the fusion stages to refine the segmentation. We evaluated our HFN on ISIC 2017, ISIC 2016 and PH2 datasets, and our results show that the HFN is more accurate and generalizable than the state-of-the-art methods.
Enhancing medical vision-language contrastive learning via inter-matching relation modelling
Jan 19, 2024

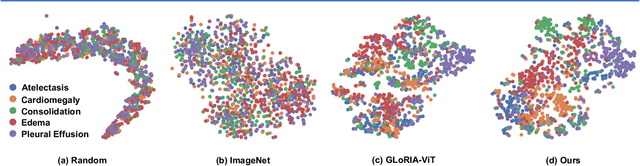

Medical image representations can be learned through medical vision-language contrastive learning (mVLCL) where medical imaging reports are used as weak supervision through image-text alignment. These learned image representations can be transferred to and benefit various downstream medical vision tasks such as disease classification and segmentation. Recent mVLCL methods attempt to align image sub-regions and the report keywords as local-matchings. However, these methods aggregate all local-matchings via simple pooling operations while ignoring the inherent relations between them. These methods therefore fail to reason between local-matchings that are semantically related, e.g., local-matchings that correspond to the disease word and the location word (semantic-relations), and also fail to differentiate such clinically important local-matchings from others that correspond to less meaningful words, e.g., conjunction words (importance-relations). Hence, we propose a mVLCL method that models the inter-matching relations between local-matchings via a relation-enhanced contrastive learning framework (RECLF). In RECLF, we introduce a semantic-relation reasoning module (SRM) and an importance-relation reasoning module (IRM) to enable more fine-grained report supervision for image representation learning. We evaluated our method using four public benchmark datasets on four downstream tasks, including segmentation, zero-shot classification, supervised classification, and cross-modal retrieval. Our results demonstrated the superiority of our RECLF over the state-of-the-art mVLCL methods with consistent improvements across single-modal and cross-modal tasks. These results suggest that our RECLF, by modelling the inter-matching relations, can learn improved medical image representations with better generalization capabilities.
PET Synthesis via Self-supervised Adaptive Residual Estimation Generative Adversarial Network
Oct 24, 2023



Positron emission tomography (PET) is a widely used, highly sensitive molecular imaging in clinical diagnosis. There is interest in reducing the radiation exposure from PET but also maintaining adequate image quality. Recent methods using convolutional neural networks (CNNs) to generate synthesized high-quality PET images from low-dose counterparts have been reported to be state-of-the-art for low-to-high image recovery methods. However, these methods are prone to exhibiting discrepancies in texture and structure between synthesized and real images. Furthermore, the distribution shift between low-dose PET and standard PET has not been fully investigated. To address these issues, we developed a self-supervised adaptive residual estimation generative adversarial network (SS-AEGAN). We introduce (1) An adaptive residual estimation mapping mechanism, AE-Net, designed to dynamically rectify the preliminary synthesized PET images by taking the residual map between the low-dose PET and synthesized output as the input, and (2) A self-supervised pre-training strategy to enhance the feature representation of the coarse generator. Our experiments with a public benchmark dataset of total-body PET images show that SS-AEGAN consistently outperformed the state-of-the-art synthesis methods with various dose reduction factors.
AutoFuse: Automatic Fusion Networks for Deformable Medical Image Registration
Sep 11, 2023



Deformable image registration aims to find a dense non-linear spatial correspondence between a pair of images, which is a crucial step for many medical tasks such as tumor growth monitoring and population analysis. Recently, Deep Neural Networks (DNNs) have been widely recognized for their ability to perform fast end-to-end registration. However, DNN-based registration needs to explore the spatial information of each image and fuse this information to characterize spatial correspondence. This raises an essential question: what is the optimal fusion strategy to characterize spatial correspondence? Existing fusion strategies (e.g., early fusion, late fusion) were empirically designed to fuse information by manually defined prior knowledge, which inevitably constrains the registration performance within the limits of empirical designs. In this study, we depart from existing empirically-designed fusion strategies and develop a data-driven fusion strategy for deformable image registration. To achieve this, we propose an Automatic Fusion network (AutoFuse) that provides flexibility to fuse information at many potential locations within the network. A Fusion Gate (FG) module is also proposed to control how to fuse information at each potential network location based on training data. Our AutoFuse can automatically optimize its fusion strategy during training and can be generalizable to both unsupervised registration (without any labels) and semi-supervised registration (with weak labels provided for partial training data). Extensive experiments on two well-benchmarked medical registration tasks (inter- and intra-patient registration) with eight public datasets show that our AutoFuse outperforms state-of-the-art unsupervised and semi-supervised registration methods.
Merging-Diverging Hybrid Transformer Networks for Survival Prediction in Head and Neck Cancer
Jul 07, 2023Survival prediction is crucial for cancer patients as it provides early prognostic information for treatment planning. Recently, deep survival models based on deep learning and medical images have shown promising performance for survival prediction. However, existing deep survival models are not well developed in utilizing multi-modality images (e.g., PET-CT) and in extracting region-specific information (e.g., the prognostic information in Primary Tumor (PT) and Metastatic Lymph Node (MLN) regions). In view of this, we propose a merging-diverging learning framework for survival prediction from multi-modality images. This framework has a merging encoder to fuse multi-modality information and a diverging decoder to extract region-specific information. In the merging encoder, we propose a Hybrid Parallel Cross-Attention (HPCA) block to effectively fuse multi-modality features via parallel convolutional layers and cross-attention transformers. In the diverging decoder, we propose a Region-specific Attention Gate (RAG) block to screen out the features related to lesion regions. Our framework is demonstrated on survival prediction from PET-CT images in Head and Neck (H&N) cancer, by designing an X-shape merging-diverging hybrid transformer network (named XSurv). Our XSurv combines the complementary information in PET and CT images and extracts the region-specific prognostic information in PT and MLN regions. Extensive experiments on the public dataset of HEad and neCK TumOR segmentation and outcome prediction challenge (HECKTOR 2022) demonstrate that our XSurv outperforms state-of-the-art survival prediction methods.
Non-iterative Coarse-to-fine Transformer Networks for Joint Affine and Deformable Image Registration
Jul 07, 2023Image registration is a fundamental requirement for medical image analysis. Deep registration methods based on deep learning have been widely recognized for their capabilities to perform fast end-to-end registration. Many deep registration methods achieved state-of-the-art performance by performing coarse-to-fine registration, where multiple registration steps were iterated with cascaded networks. Recently, Non-Iterative Coarse-to-finE (NICE) registration methods have been proposed to perform coarse-to-fine registration in a single network and showed advantages in both registration accuracy and runtime. However, existing NICE registration methods mainly focus on deformable registration, while affine registration, a common prerequisite, is still reliant on time-consuming traditional optimization-based methods or extra affine registration networks. In addition, existing NICE registration methods are limited by the intrinsic locality of convolution operations. Transformers may address this limitation for their capabilities to capture long-range dependency, but the benefits of using transformers for NICE registration have not been explored. In this study, we propose a Non-Iterative Coarse-to-finE Transformer network (NICE-Trans) for image registration. Our NICE-Trans is the first deep registration method that (i) performs joint affine and deformable coarse-to-fine registration within a single network, and (ii) embeds transformers into a NICE registration framework to model long-range relevance between images. Extensive experiments with seven public datasets show that our NICE-Trans outperforms state-of-the-art registration methods on both registration accuracy and runtime.
DeepMSS: Deep Multi-Modality Segmentation-to-Survival Learning for Survival Outcome Prediction from PET/CT Images
May 17, 2023Survival prediction is a major concern for cancer management. Deep survival models based on deep learning have been widely adopted to perform end-to-end survival prediction from medical images. Recent deep survival models achieved promising performance by jointly performing tumor segmentation with survival prediction, where the models were guided to extract tumor-related information through Multi-Task Learning (MTL). However, existing deep survival models have difficulties in exploring out-of-tumor prognostic information (e.g., local lymph node metastasis and adjacent tissue invasions). In addition, existing deep survival models are underdeveloped in utilizing multi-modality images. Empirically-designed strategies were commonly adopted to fuse multi-modality information via fixed pre-designed networks. In this study, we propose a Deep Multi-modality Segmentation-to-Survival model (DeepMSS) for survival prediction from PET/CT images. Instead of adopting MTL, we propose a novel Segmentation-to-Survival Learning (SSL) strategy, where our DeepMSS is trained for tumor segmentation and survival prediction sequentially. This strategy enables the DeepMSS to initially focus on tumor regions and gradually expand its focus to include other prognosis-related regions. We also propose a data-driven strategy to fuse multi-modality image information, which realizes automatic optimization of fusion strategies based on training data during training and also improves the adaptability of DeepMSS to different training targets. Our DeepMSS is also capable of incorporating conventional radiomics features as an enhancement, where handcrafted features can be extracted from the DeepMSS-segmented tumor regions and cooperatively integrated into the DeepMSS's training and inference. Extensive experiments with two large clinical datasets show that our DeepMSS outperforms state-of-the-art survival prediction methods.
Hyper-Connected Transformer Network for Co-Learning Multi-Modality PET-CT Features
Oct 28, 2022



[18F]-Fluorodeoxyglucose (FDG) positron emission tomography - computed tomography (PET-CT) has become the imaging modality of choice for diagnosing many cancers. Co-learning complementary PET-CT imaging features is a fundamental requirement for automatic tumor segmentation and for developing computer aided cancer diagnosis systems. We propose a hyper-connected transformer (HCT) network that integrates a transformer network (TN) with a hyper connected fusion for multi-modality PET-CT images. The TN was leveraged for its ability to provide global dependencies in image feature learning, which was achieved by using image patch embeddings with a self-attention mechanism to capture image-wide contextual information. We extended the single-modality definition of TN with multiple TN based branches to separately extract image features. We introduced a hyper connected fusion to fuse the contextual and complementary image features across multiple transformers in an iterative manner. Our results with two non-small cell lung cancer and soft-tissue sarcoma datasets show that HCT achieved better performance in segmentation accuracy when compared to state-of-the-art methods. We also show that HCT produces consistent performance across various image fusion strategies and network backbones.