 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Connected Transformer Network for Co-Learning Multi-Modality PET-CT Features
Oct 28, 2022



[18F]-Fluorodeoxyglucose (FDG) positron emission tomography - computed tomography (PET-CT) has become the imaging modality of choice for diagnosing many cancers. Co-learning complementary PET-CT imaging features is a fundamental requirement for automatic tumor segmentation and for developing computer aided cancer diagnosis systems. We propose a hyper-connected transformer (HCT) network that integrates a transformer network (TN) with a hyper connected fusion for multi-modality PET-CT images. The TN was leveraged for its ability to provide global dependencies in image feature learning, which was achieved by using image patch embeddings with a self-attention mechanism to capture image-wide contextual information. We extended the single-modality definition of TN with multiple TN based branches to separately extract image features. We introduced a hyper connected fusion to fuse the contextual and complementary image features across multiple transformers in an iterative manner. Our results with two non-small cell lung cancer and soft-tissue sarcoma datasets show that HCT achieved better performance in segmentation accuracy when compared to state-of-the-art methods. We also show that HCT produces consistent performance across various image fusion strategies and network backbones.
Graph-Based Intercategory and Intermodality Network for Multilabel Classification and Melanoma Diagnosis of Skin Lesions in Dermoscopy and Clinical Images
Apr 01, 2021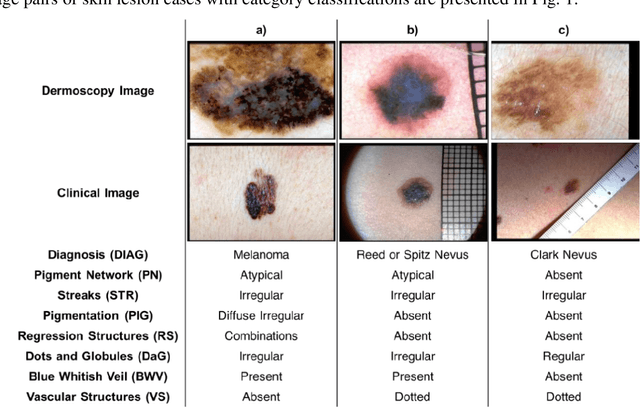
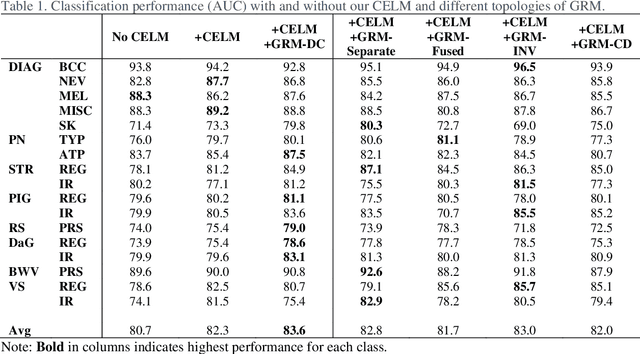
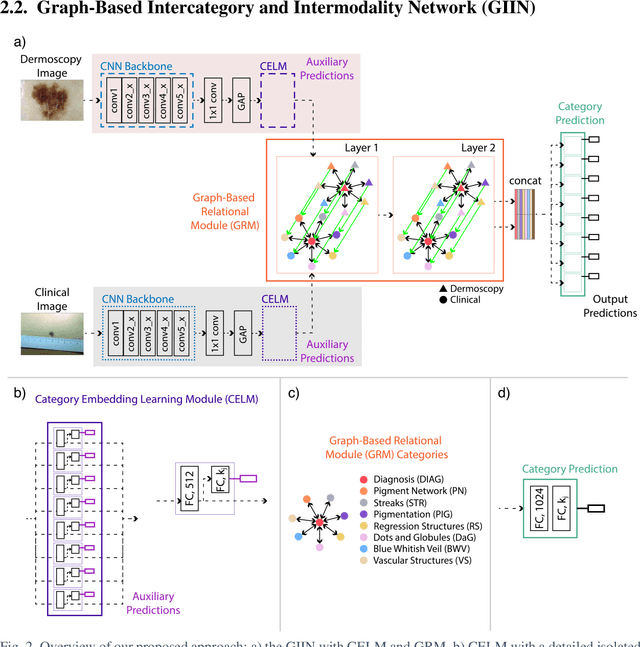

The identification of melanoma involves an integrated analysis of skin lesion images acquired using the clinical and dermoscopy modalities. Dermoscopic images provide a detailed view of the subsurface visual structures that supplement the macroscopic clinical images. Melanoma diagnosis is commonly based on the 7-point visual category checklist (7PC). The 7PC contains intrinsic relationships between categories that can aid classification, such as shared features, correlations, and the contributions of categories towards diagnosis. Manual classification is subjective and prone to intra- and interobserver variability. This presents an opportunity for automated methods to improve diagnosis. Current state-of-the-art methods focus on a single image modality and ignore information from the other, or do not fully leverage the complementary information from both modalities. Further, there is not a method to exploit the intercategory relationships in the 7PC. In this study, we address these issues by proposing a graph-based intercategory and intermodality network (GIIN) with two modules. A graph-based relational module (GRM) leverages intercategorical relations, intermodal relations, and prioritises the visual structure details from dermoscopy by encoding category representations in a graph network. The category embedding learning module (CELM) captures representations that are specialised for each category and support the GRM. We show that our modules are effective at enhancing classification performance using a public dataset of dermoscopy-clinical images, and show that our method outperforms the state-of-the-art at classifying the 7PC categories and diagnosis.
Attention-Enhanced Cross-Task Network for Analysing Multiple Attributes of Lung Nodules in CT
Mar 05, 2021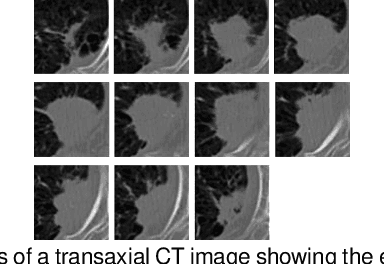
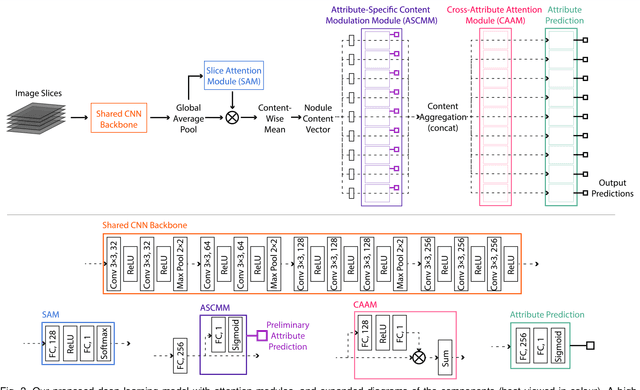
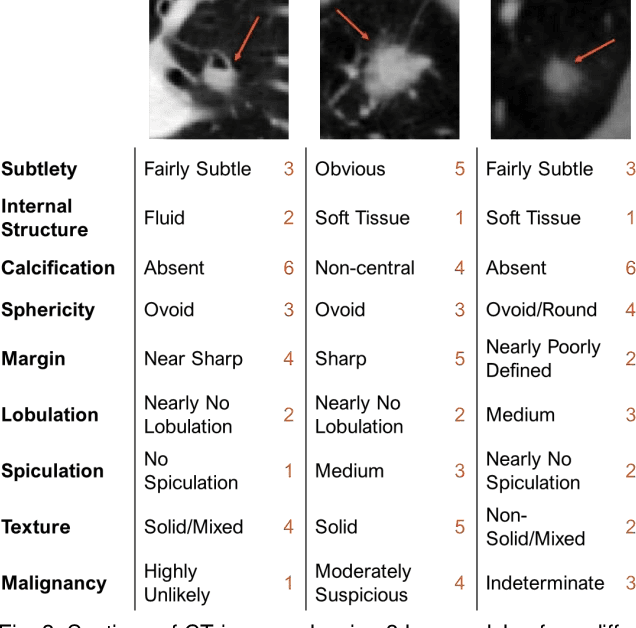
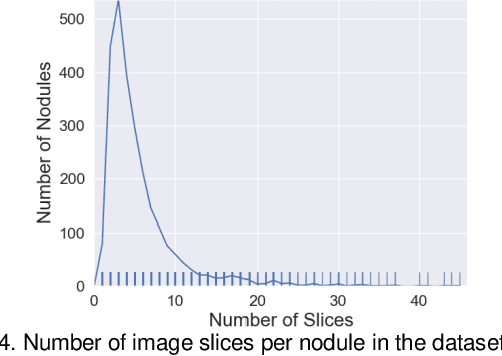
Accurate characterisation of visual attributes such as spiculation, lobulation, and calcification of lung nodules is critical in cancer management. The characterisation of these attributes is often subjective, which may lead to high inter- and intra-observer variability. Furthermore, lung nodules are often heterogeneous in the cross-sectional image slices of a 3D volume. Current state-of-the-art methods that score multiple attributes rely on deep learning-based multi-task learning (MTL) schemes. These methods, however, extract shared visual features across attributes and then examine each attribute without explicitly leveraging their inherent intercorrelations. Furthermore, current methods either treat each slice with equal importance without considering their relevance or heterogeneity, or restrict the number of input slices, which limits performance. In this study, we address these challenges with a new convolutional neural network (CNN)-based MTL model that incorporates attention modules to simultaneously score 9 visual attributes of lung nodules in computed tomography (CT) image volumes. Our model processes entire nodule volumes of arbitrary depth and uses a slice attention module to filter out irrelevant slices. We also introduce cross-attribute and attribute specialisation attention modules that learn an optimal amalgamation of meaningful representations to leverage relationships between attributes. We demonstrate that our model outperforms previous state-of-the-art methods at scoring attributes using the well-known public LIDC-IDRI dataset of pulmonary nodules from over 1,000 patients. Our attention modules also provide easy-to-interpret weights that offer insights into the predictions of the model.
Multimodal Spatial Attention Module for Targeting Multimodal PET-CT Lung Tumor Segmentation
Aug 06, 2020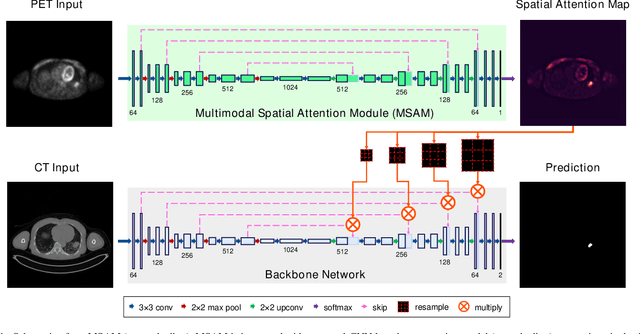
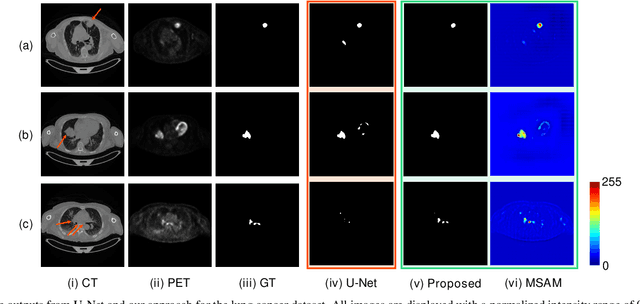
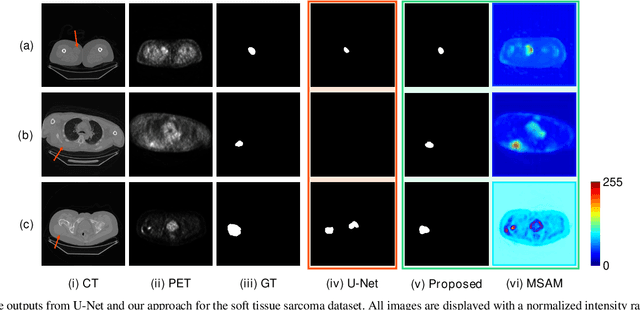
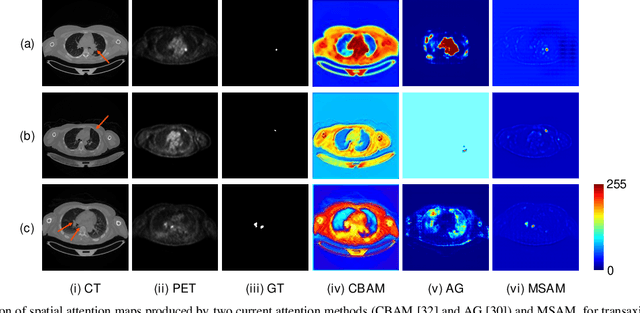
Multimodal positron emission tomography-computed tomography (PET-CT) is used routinely in the assessment of cancer. PET-CT combines the high sensitivity for tumor detection with PET and anatomical information from CT. Tumor segmentation is a critical element of PET-CT but at present, there is not an accurate automated segmentation method. Segmentation tends to be done manually by different imaging experts and it is labor-intensive and prone to errors and inconsistency. Previous automated segmentation methods largely focused on fusing information that is extracted separately from the PET and CT modalities, with the underlying assumption that each modality contains complementary information. However, these methods do not fully exploit the high PET tumor sensitivity that can guide the segmentation. We introduce a multimodal spatial attention module (MSAM) that automatically learns to emphasize regions (spatial areas) related to tumors and suppress normal regions with physiologic high-uptake. The resulting spatial attention maps are subsequently employed to target a convolutional neural network (CNN) for segmentation of areas with higher tumor likelihood. Our MSAM can be applied to common backbone architectures and trained end-to-end. Our experimental results on two clinical PET-CT datasets of non-small cell lung cancer (NSCLC) and soft tissue sarcoma (STS) validate the effectiveness of the MSAM in these different cancer types. We show that our MSAM, with a conventional U-Net backbone, surpasses the state-of-the-art lung tumor segmentation approach by a margin of 7.6% in Dice similarity coefficient (DSC).
Segmentation of histological images and fibrosis identification with a convolutional neural network
Mar 20, 2018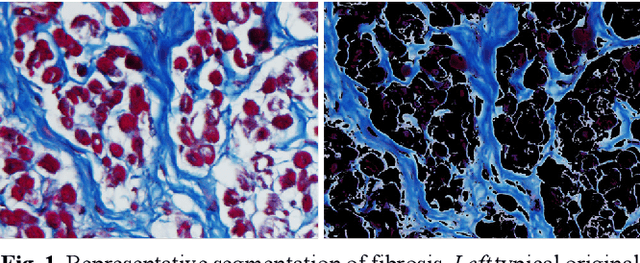
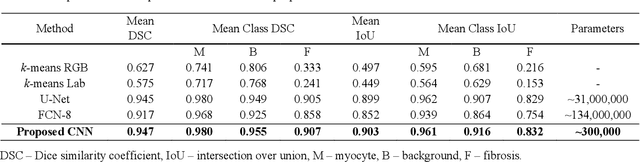
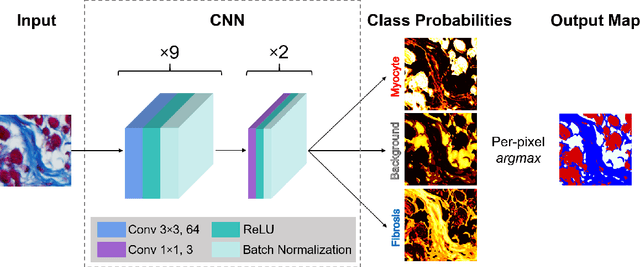
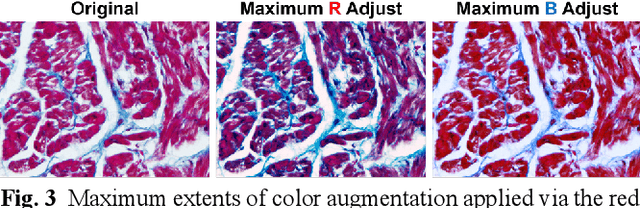
Segmentation of histological images is one of the most crucial tasks for many biomedical analyses including quantification of certain tissue type. However, challenges are posed by high variability and complexity of structural features in such images, in addition to imaging artifacts. Further, the conventional approach of manual thresholding is labor-intensive, and highly sensitive to inter- and intra-image intensity variations. An accurate and robust automated segmentation method is of high interest. We propose and evaluate an elegant convolutional neural network (CNN) designed for segmentation of histological images, particularly those with Masson's trichrome stain. The network comprises of 11 successive convolutional - rectified linear unit - batch normalization layers, and outperformed state-of-the-art CNNs on a dataset of cardiac histological images (labeling fibrosis, myocytes, and background) with a Dice similarity coefficient of 0.947. With 100 times fewer (only 300 thousand) trainable parameters, our CNN is less susceptible to overfitting, and is efficient. Additionally, it retains image resolution from input to output, captures fine-grained details, and can be trained end-to-end smoothly. To the best of our knowledge, this is the first deep CNN tailored for the problem of concern, and may be extended to solve similar segmentation tasks to facilitate investigations into pathology and clinical treatment.