 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMPL-GPTexture: Dual-View 3D Human Texture Estimation using Text-to-Image Generation Models
Apr 17, 2025Generating high-quality, photorealistic textures for 3D human avatars remains a fundamental yet challenging task in computer vision and multimedia field. However, real paired front and back images of human subjects are rarely available with privacy, ethical and cost of acquisition, which restricts scalability of the data. Additionally, learning priors from image inputs using deep generative models, such as GANs or diffusion models, to infer unseen regions such as the human back often leads to artifacts, structural inconsistencies, or loss of fine-grained detail. To address these issues, we present SMPL-GPTexture (skinned multi-person linear model - general purpose Texture), a novel pipeline that takes natural language prompts as input and leverages a state-of-the-art text-to-image generation model to produce paired high-resolution front and back images of a human subject as the starting point for texture estimation. Using the generated paired dual-view images, we first employ a human mesh recovery model to obtain a robust 2D-to-3D SMPL alignment between image pixels and the 3D model's UV coordinates for each views. Second, we use an inverted rasterization technique that explicitly projects the observed colour from the input images into the UV space, thereby producing accurate, complete texture maps. Finally, we apply a diffusion-based inpainting module to fill in the missing regions, and the fusion mechanism then combines these results into a unified full texture map. Extensive experiments shows that our SMPL-GPTexture can generate high resolution texture aligned with user's prompts.
Multi-modal 3D Pose and Shape Estimation with Computed Tomography
Mar 25, 2025
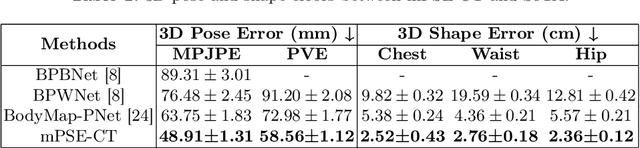


In perioperative care, precise in-bed 3D patient pose and shape estimation (PSE) can be vital in optimizing patient positioning in preoperative planning, enabling accurate overlay of medical images for augmented reality-based surgical navigation, and mitigating risks of prolonged immobility during recovery. Conventional PSE methods relying on modalities such as RGB-D, infrared, or pressure maps often struggle with occlusions caused by bedding and complex patient positioning, leading to inaccurate estimation that can affect clinical outcomes. To address these challenges, we present the first multi-modal in-bed patient 3D PSE network that fuses detailed geometric features extracted from routinely acquired computed tomography (CT) scans with depth maps (mPSE-CT). mPSE-CT incorporates a shape estimation module that utilizes probabilistic correspondence alignment, a pose estimation module with a refined neural network, and a final parameters mixing module. This multi-modal network robustly reconstructs occluded body regions and enhances the accuracy of the estimated 3D human mesh model. We validated mPSE-CT using proprietary whole-body rigid phantom and volunteer datasets in clinical scenarios. mPSE-CT outperformed the best-performing prior method by 23% and 49.16% in pose and shape estimation respectively, demonstrating its potential for improving clinical outcomes in challenging perioperative environments.