 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking for Biomedical Natural Language Processing Tasks with a Domain Specific ALBERT
Paper and Code
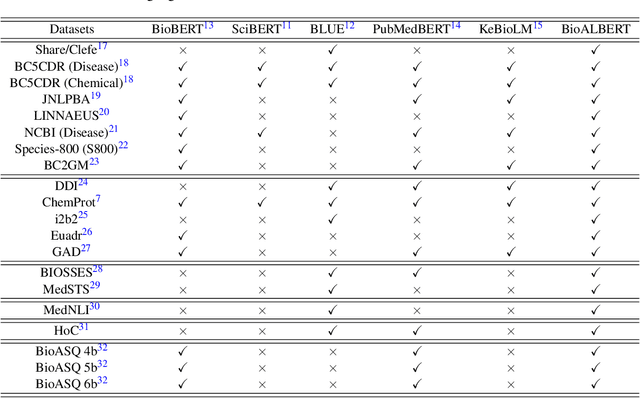


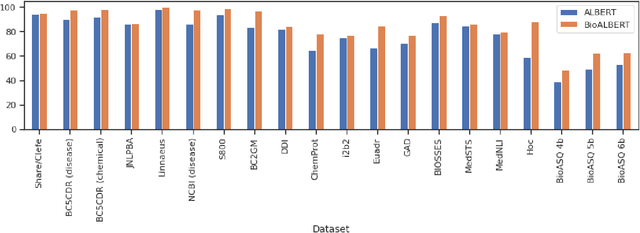
The availability of biomedical text data and advances in natural language processing (NLP) have made new applications in biomedical NLP possible. Language models trained or fine tuned using domain specific corpora can outperform general models, but work to date in biomedical NLP has been limited in terms of corpora and tasks. We present BioALBERT, a domain-specific adaptation of A Lite Bidirectional Encoder Representations from Transformers (ALBERT), trained on biomedical (PubMed and PubMed Central) and clinical (MIMIC-III) corpora and fine tuned for 6 different tasks across 20 benchmark datasets. Experiments show that BioALBERT outperforms the state of the art on named entity recognition (+11.09% BLURB score improvement), relation extraction (+0.80% BLURB score), sentence similarity (+1.05% BLURB score), document classification (+0.62% F1-score), and question answering (+2.83% BLURB score). It represents a new state of the art in 17 out of 20 benchmark datasets. By making BioALBERT models and data available, our aim is to help the biomedical NLP community avoid computational costs of training and establish a new set of baselines for future efforts across a broad range of biomedical NLP tasks.