 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemToolAgent overview with a simple restaurant booking scenario where the agent retrieves similar memories, receives feedback on an invalid time format, and generates a reflection to update its memory
Jun 06, 2026Modern large language model (LLM) agents can use external tools to help users solve complex tasks. However, for problems that require learning from long-term historical events or from previous agent-environment interactions, LLM agents are required to use memory mechanisms to store and retrieve experiences. While sophisticated memory systems exist for dialogue agents, few studies have empirically examined how to improve agents' tool-using capabilities through past user-agent conversations. We propose MemToolAgent, a framework that improves tool use through memory management. Our approach contains a memory extraction module that processes past experiences into structured memory entries, and a retrieval module that dynamically selects a subset of the stored memory entries. This enables more personalized and accurate responses aligned with user preferences and feedback without requiring LLM fine-tuning. In summary, this work has three main contributions: (1) a unified memory entry format that improves both general-purpose and personalized tool use without LLM fine-tuning, (2) a reflection-based memory extraction that uses environment and user feedback to distill wrong executions into critiques to store, and (3) a retrieval module that chooses how many past experiences to use based on the memory similarity distribution. MemToolAgent achieves 29%, 80%, and 17% relative improvements compared to strong baselines on the WorkBench, NESTFUL, and PEToolBench benchmarks, respectively.
Reducing Distraction in Long-Context Language Models by Focused Learning
Nov 08, 2024



Recent advancements in Large Language Models (LLMs) have significantly enhanced their capacity to process long contexts. However, effectively utilizing this long context remains a challenge due to the issue of distraction, where irrelevant information dominates lengthy contexts, causing LLMs to lose focus on the most relevant segments. To address this, we propose a novel training method that enhances LLMs' ability to discern relevant information through a unique combination of retrieval-based data augmentation and contrastive learning. Specifically, during fine-tuning with long contexts, we employ a retriever to extract the most relevant segments, serving as augmented inputs. We then introduce an auxiliary contrastive learning objective to explicitly ensure that outputs from the original context and the retrieved sub-context are closely aligned. Extensive experiments on long single-document and multi-document QA benchmarks demonstrate the effectiveness of our proposed method.
MATrIX -- Modality-Aware Transformer for Information eXtraction
May 17, 2022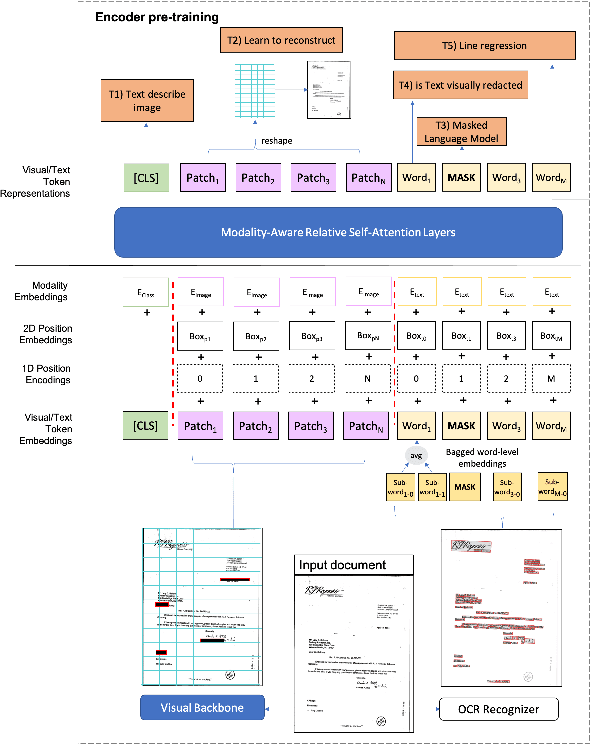
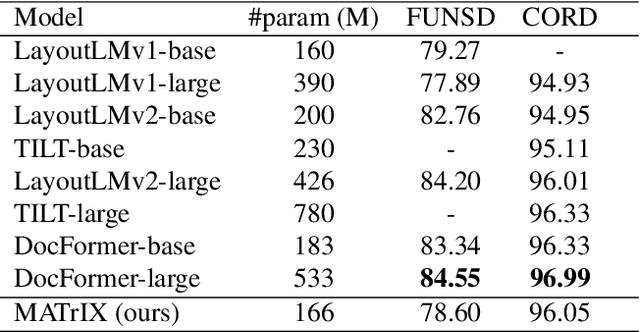

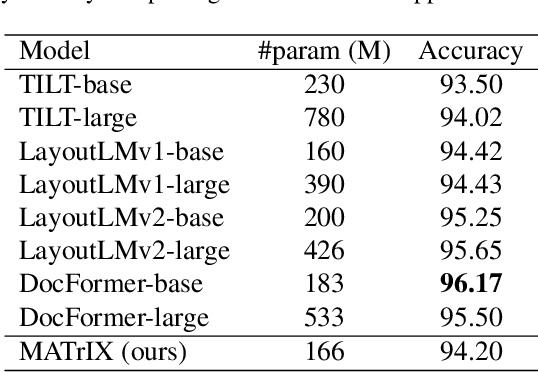
We present MATrIX - a Modality-Aware Transformer for Information eXtraction in the Visual Document Understanding (VDU) domain. VDU covers information extraction from visually rich documents such as forms, invoices, receipts, tables, graphs, presentations, or advertisements. In these, text semantics and visual information supplement each other to provide a global understanding of the document. MATrIX is pre-trained in an unsupervised way with specifically designed tasks that require the use of multi-modal information (spatial, visual, or textual). We consider the spatial and text modalities all at once in a single token set. To make the attention more flexible, we use a learned modality-aware relative bias in the attention mechanism to modulate the attention between the tokens of different modalities. We evaluate MATrIX on 3 different datasets each with strong baselines.
A Computationally Efficient Pipeline Approach to Full Page Offline Handwritten Text Recognition
Oct 01, 2019
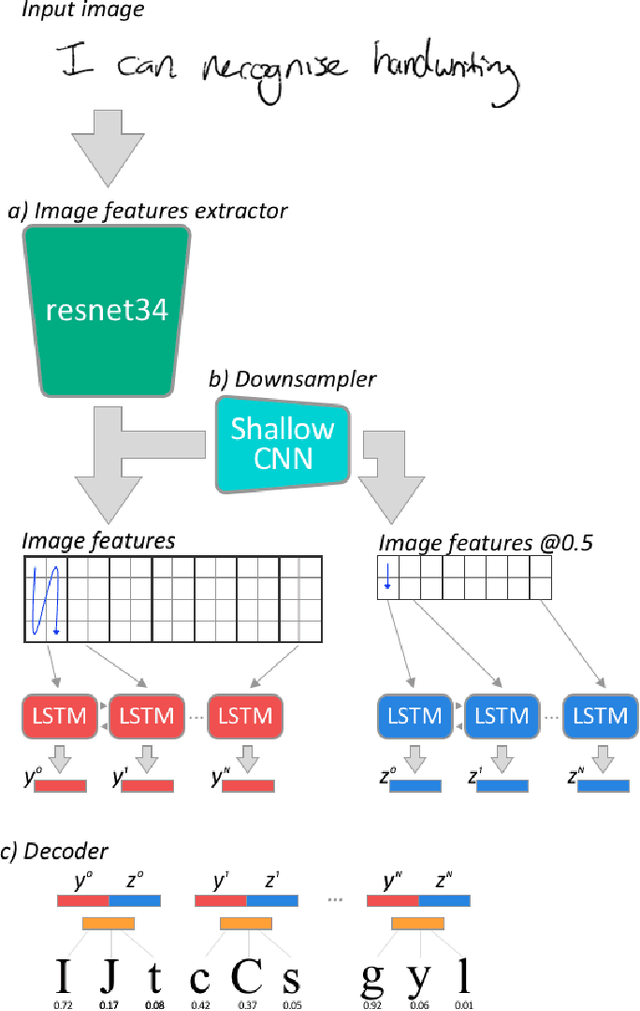

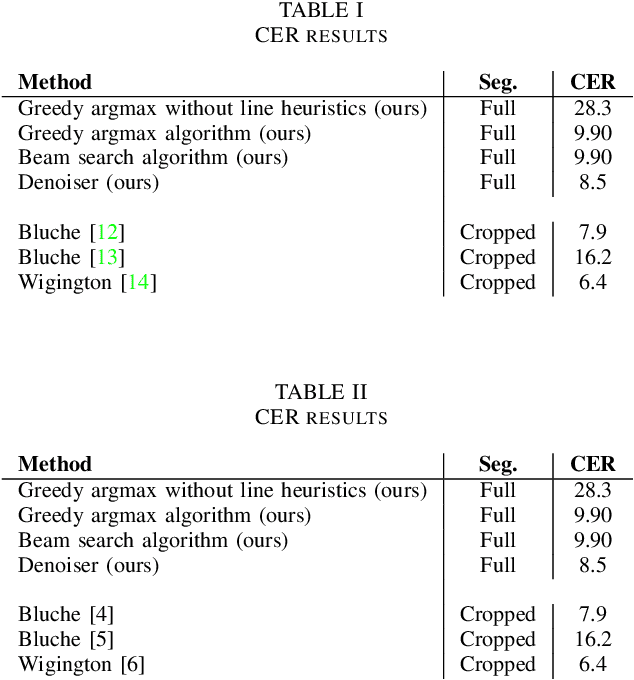
Offline handwriting recognition with deep neural networks is usually limited to words or lines due to large computational costs. In this paper, a less computationally expensive full page offline handwritten text recognition framework is introduced. This framework includes a pipeline that locates handwritten text with an object detection neural network and recognises the text within the detected regions using features extracted with a multi-scale convolutional neural network (CNN) fed into a bidirectional long short term memory (LSTM) network. This framework achieves comparable error rates to state of the art frameworks while using less memory and time. The results in this paper demonstrate the potential of this framework and future work can investigate production ready and deployable handwritten text recognisers.