 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATrIX -- Modality-Aware Transformer for Information eXtraction
Paper and Code
May 17, 2022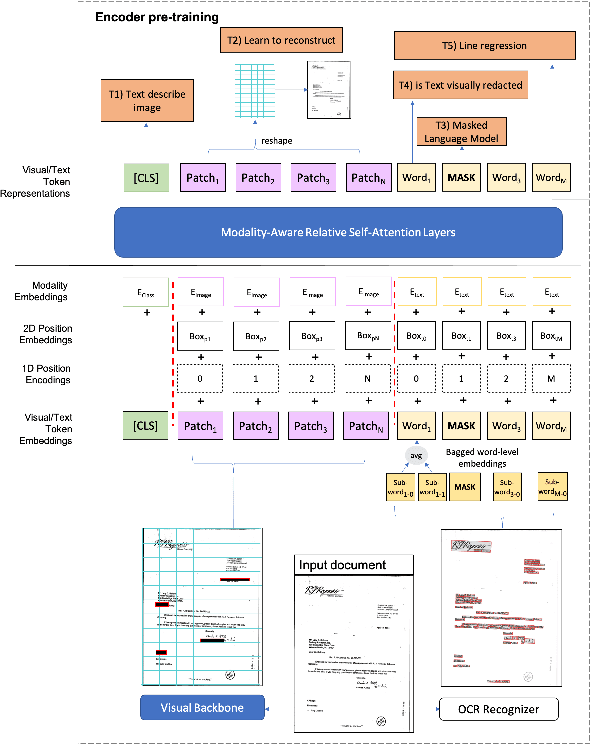
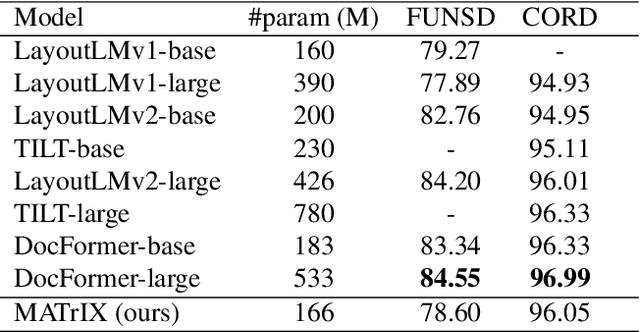

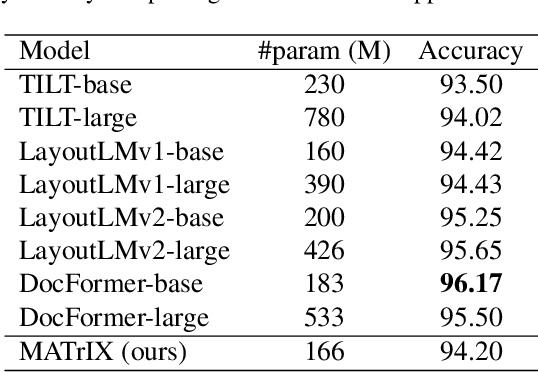
We present MATrIX - a Modality-Aware Transformer for Information eXtraction in the Visual Document Understanding (VDU) domain. VDU covers information extraction from visually rich documents such as forms, invoices, receipts, tables, graphs, presentations, or advertisements. In these, text semantics and visual information supplement each other to provide a global understanding of the document. MATrIX is pre-trained in an unsupervised way with specifically designed tasks that require the use of multi-modal information (spatial, visual, or textual). We consider the spatial and text modalities all at once in a single token set. To make the attention more flexible, we use a learned modality-aware relative bias in the attention mechanism to modulate the attention between the tokens of different modalities. We evaluate MATrIX on 3 different datasets each with strong baselines.