 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVQI: A Multi-task, Hardware-integrated Artificial Intelligence System for Automated Visual Inspection in Electronics Manufacturing
Dec 14, 2023

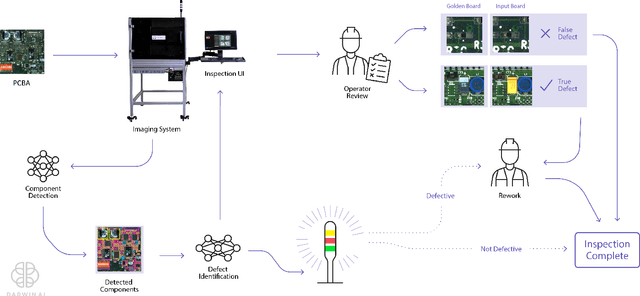
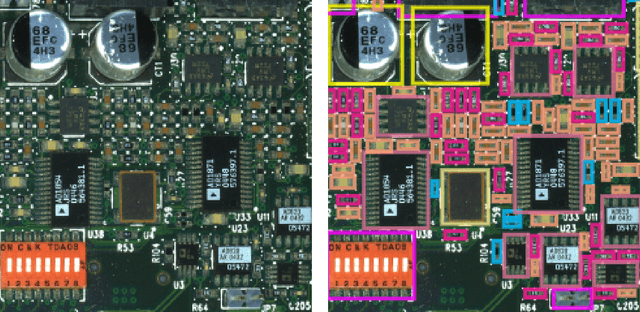
As electronics manufacturers continue to face pressure to increase production efficiency amid difficulties with supply chains and labour shortages, many printed circuit board assembly (PCBA) manufacturers have begun to invest in automation and technological innovations to remain competitive. One such method is to leverage artificial intelligence (AI) to greatly augment existing manufacturing processes. In this paper, we present the DarwinAI Visual Quality Inspection (DVQI) system, a hardware-integration artificial intelligence system for the automated inspection of printed circuit board assembly defects in an electronics manufacturing environment. The DVQI system enables multi-task inspection via minimal programming and setup for manufacturing engineers while improving cycle time relative to manual inspection. We also present a case study of the deployed DVQI system's performance and impact for a top electronics manufacturer.
COVID-Net Biochem: An Explainability-driven Framework to Building Machine Learning Models for Predicting Survival and Kidney Injury of COVID-19 Patients from Clinical and Biochemistry Data
Apr 24, 2022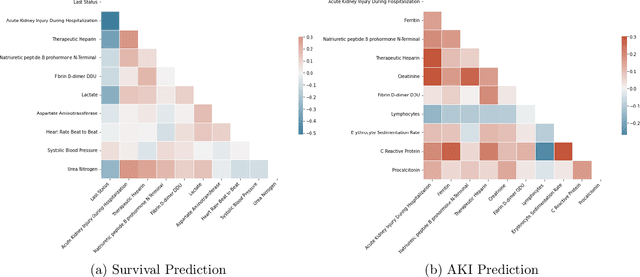
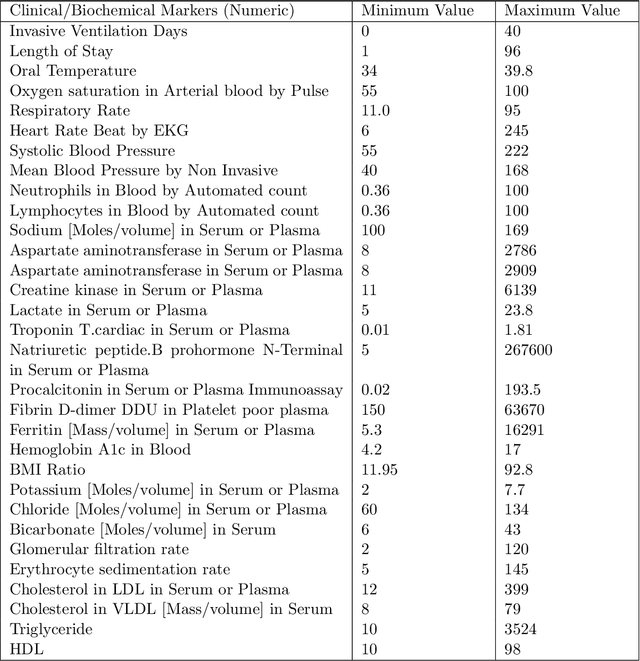
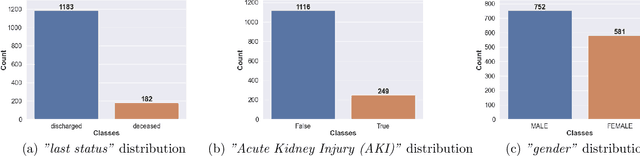
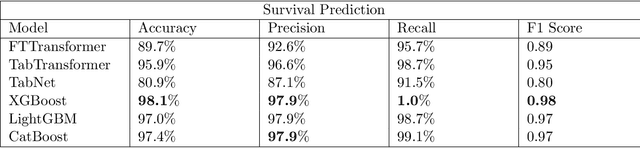
Ever since the declaration of COVID-19 as a pandemic by the World Health Organization in 2020, the world has continued to struggle in controlling and containing the spread of the COVID-19 pandemic caused by the SARS-CoV-2 virus. This has been especially challenging with the rise of the Omicron variant and its subvariants and recombinants, which has led to a significant increase in patients seeking treatment and has put a tremendous burden on hospitals and healthcare systems. A major challenge faced during the pandemic has been the prediction of survival and the risk for additional injuries in individual patients, which requires significant clinical expertise and additional resources to avoid further complications. In this study we propose COVID-Net Biochem, an explainability-driven framework for building machine learning models to predict patient survival and the chance of developing kidney injury during hospitalization from clinical and biochemistry data in a transparent and systematic manner. In the first "clinician-guided initial design" phase, we prepared a benchmark dataset of carefully selected clinical and biochemistry data based on clinician assessment, which were curated from a patient cohort of 1366 patients at Stony Brook University. A collection of different machine learning models with a diversity of gradient based boosting tree architectures and deep transformer architectures was designed and trained specifically for survival and kidney injury prediction based on the carefully selected clinical and biochemical markers.
COVID-Net Clinical ICU: Enhanced Prediction of ICU Admission for COVID-19 Patients via Explainability and Trust Quantification
Sep 14, 2021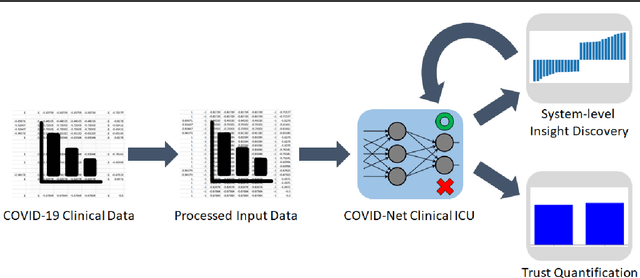
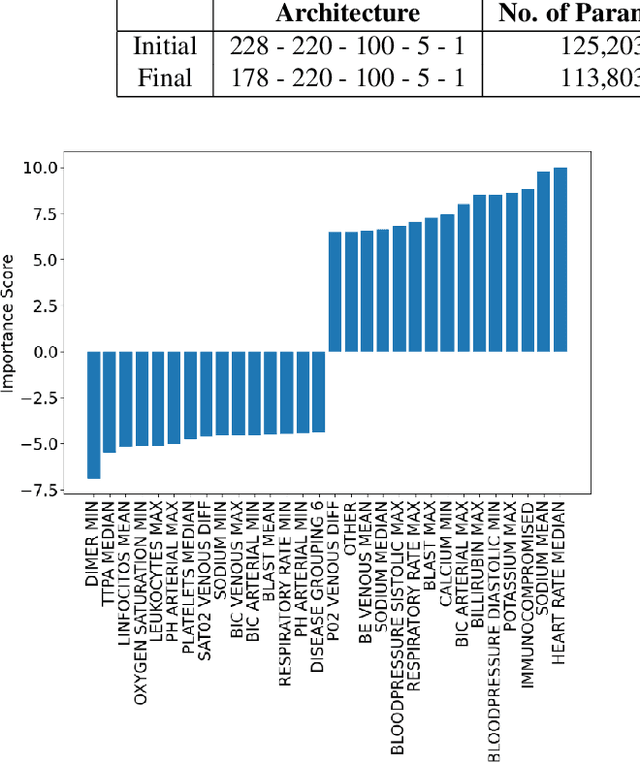
The COVID-19 pandemic continues to have a devastating global impact, and has placed a tremendous burden on struggling healthcare systems around the world. Given the limited resources, accurate patient triaging and care planning is critical in the fight against COVID-19, and one crucial task within care planning is determining if a patient should be admitted to a hospital's intensive care unit (ICU). Motivated by the need for transparent and trustworthy ICU admission clinical decision support, we introduce COVID-Net Clinical ICU, a neural network for ICU admission prediction based on patient clinical data. Driven by a transparent, trust-centric methodology, the proposed COVID-Net Clinical ICU was built using a clinical dataset from Hospital Sirio-Libanes comprising of 1,925 COVID-19 patients, and is able to predict when a COVID-19 positive patient would require ICU admission with an accuracy of 96.9% to facilitate better care planning for hospitals amidst the on-going pandemic. We conducted system-level insight discovery using a quantitative explainability strategy to study the decision-making impact of different clinical features and gain actionable insights for enhancing predictive performance. We further leveraged a suite of trust quantification metrics to gain deeper insights into the trustworthiness of COVID-Net Clinical ICU. By digging deeper into when and why clinical predictive models makes certain decisions, we can uncover key factors in decision making for critical clinical decision support tasks such as ICU admission prediction and identify the situations under which clinical predictive models can be trusted for greater accountability.
AttendSeg: A Tiny Attention Condenser Neural Network for Semantic Segmentation on the Edge
Apr 29, 2021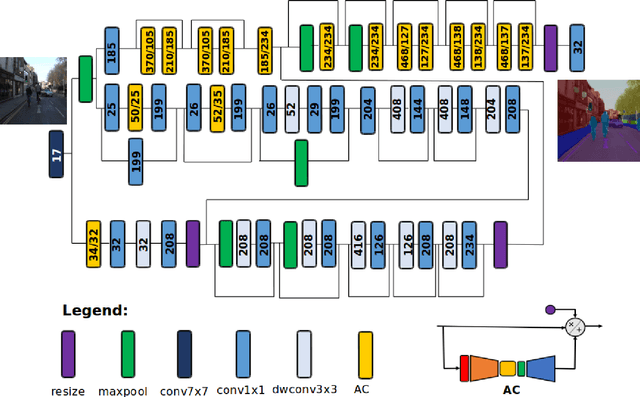


In this study, we introduce \textbf{AttendSeg}, a low-precision, highly compact deep neural network tailored for on-device semantic segmentation. AttendSeg possesses a self-attention network architecture comprising of light-weight attention condensers for improved spatial-channel selective attention at a very low complexity. The unique macro-architecture and micro-architecture design properties of AttendSeg strike a strong balance between representational power and efficiency, achieved via a machine-driven design exploration strategy tailored specifically for the task at hand. Experimental results demonstrated that the proposed AttendSeg can achieve segmentation accuracy comparable to much larger deep neural networks with greater complexity while possessing a significantly lower architecture and computational complexity (requiring as much as >27x fewer MACs, >72x fewer parameters, and >288x lower weight memory requirements), making it well-suited for TinyML applications on the edge.
Inter-layer Information Similarity Assessment of Deep Neural Networks Via Topological Similarity and Persistence Analysis of Data Neighbour Dynamics
Dec 07, 2020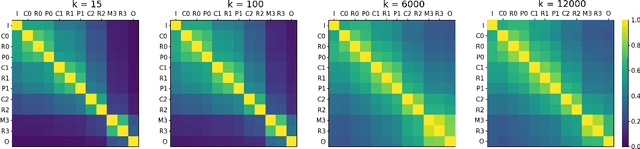
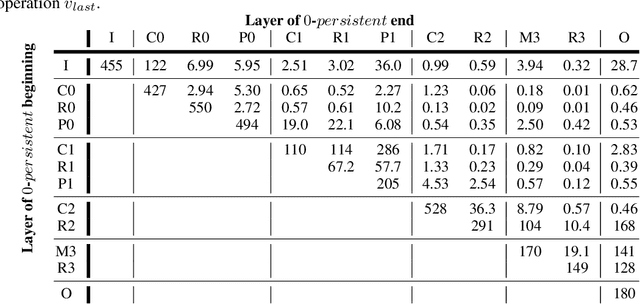
The quantitative analysis of information structure through a deep neural network (DNN) can unveil new insights into the theoretical performance of DNN architectures. Two very promising avenues of research towards quantitative information structure analysis are: 1) layer similarity (LS) strategies focused on the inter-layer feature similarity, and 2) intrinsic dimensionality (ID) strategies focused on layer-wise data dimensionality using pairwise information. Inspired by both LS and ID strategies for quantitative information structure analysis, we introduce two novel complimentary methods for inter-layer information similarity assessment premised on the interesting idea of studying a data sample's neighbourhood dynamics as it traverses through a DNN. More specifically, we introduce the concept of Nearest Neighbour Topological Similarity (NNTS) for quantifying the information topology similarity between layers of a DNN. Furthermore, we introduce the concept of Nearest Neighbour Topological Persistence (NNTP) for quantifying the inter-layer persistence of data neighbourhood relationships throughout a DNN. The proposed strategies facilitate the efficient inter-layer information similarity assessment by leveraging only local topological information, and we demonstrate their efficacy in this study by performing analysis on a deep convolutional neural network architecture on image data to study the insights that can be gained with respect to the theoretical performance of a DNN.
Insights into Fairness through Trust: Multi-scale Trust Quantification for Financial Deep Learning
Nov 03, 2020
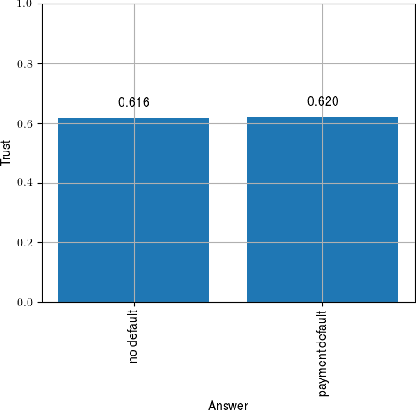
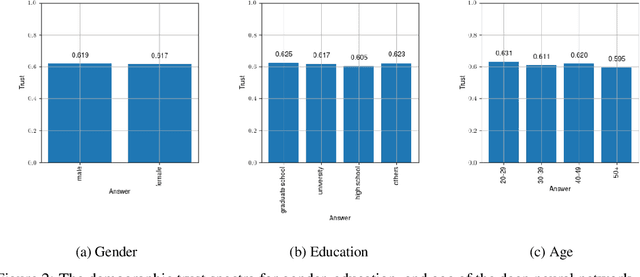
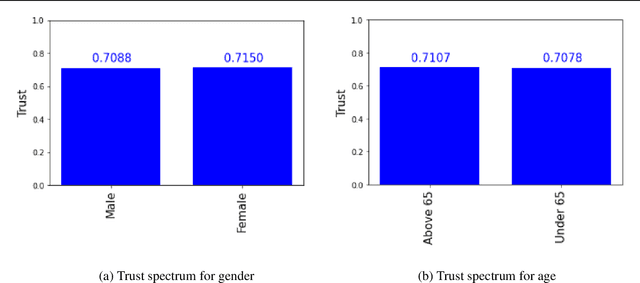
The success of deep learning in recent years have led to a significant increase in interest and prevalence for its adoption to tackle financial services tasks. One particular question that often arises as a barrier to adopting deep learning for financial services is whether the developed financial deep learning models are fair in their predictions, particularly in light of strong governance and regulatory compliance requirements in the financial services industry. A fundamental aspect of fairness that has not been explored in financial deep learning is the concept of trust, whose variations may point to an egocentric view of fairness and thus provide insights into the fairness of models. In this study we explore the feasibility and utility of a multi-scale trust quantification strategy to gain insights into the fairness of a financial deep learning model, particularly under different scenarios at different scales. More specifically, we conduct multi-scale trust quantification on a deep neural network for the purpose of credit card default prediction to study: 1) the overall trustworthiness of the model 2) the trust level under all possible prediction-truth relationships, 3) the trust level across the spectrum of possible predictions, 4) the trust level across different demographic groups (e.g., age, gender, and education), and 5) distribution of overall trust for an individual prediction scenario. The insights for this proof-of-concept study demonstrate that such a multi-scale trust quantification strategy may be helpful for data scientists and regulators in financial services as part of the verification and certification of financial deep learning solutions to gain insights into fairness and trust of these solutions.
Where Does Trust Break Down? A Quantitative Trust Analysis of Deep Neural Networks via Trust Matrix and Conditional Trust Densities
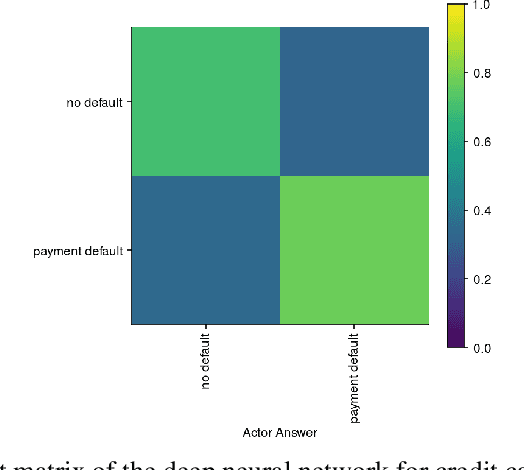
Sep 30, 2020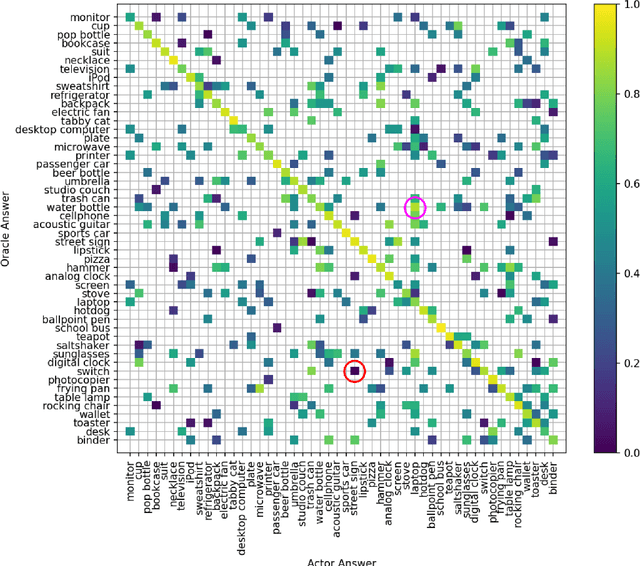
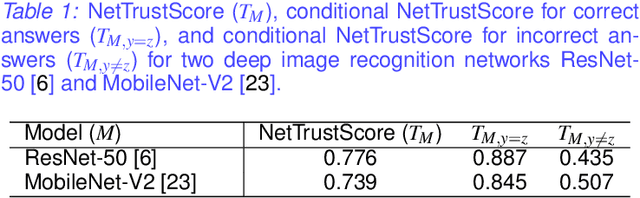
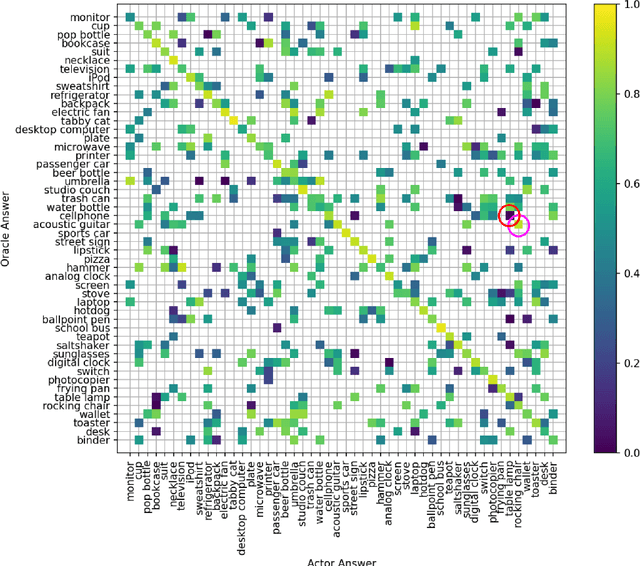
The advances and successes in deep learning in recent years have led to considerable efforts and investments into its widespread ubiquitous adoption for a wide variety of applications, ranging from personal assistants and intelligent navigation to search and product recommendation in e-commerce. With this tremendous rise in deep learning adoption comes questions about the trustworthiness of the deep neural networks that power these applications. Motivated to answer such questions, there has been a very recent interest in trust quantification. In this work, we introduce the concept of trust matrix, a novel trust quantification strategy that leverages the recently introduced question-answer trust metric by Wong et al. to provide deeper, more detailed insights into where trust breaks down for a given deep neural network given a set of questions. More specifically, a trust matrix defines the expected question-answer trust for a given actor-oracle answer scenario, allowing one to quickly spot areas of low trust that needs to be addressed to improve the trustworthiness of a deep neural network. The proposed trust matrix is simple to calculate, humanly interpretable, and to the best of the authors' knowledge is the first to study trust at the actor-oracle answer level. We further extend the concept of trust densities with the notion of conditional trust densities. We experimentally leverage trust matrices to study several well-known deep neural network architectures for image recognition, and further study the trust density and conditional trust densities for an interesting actor-oracle answer scenario. The results illustrate that trust matrices, along with conditional trust densities, can be useful tools in addition to the existing suite of trust quantification metrics for guiding practitioners and regulators in creating and certifying deep learning solutions for trusted operation.
How Much Can We Really Trust You? Towards Simple, Interpretable Trust Quantification Metrics for Deep Neural Networks
Sep 20, 2020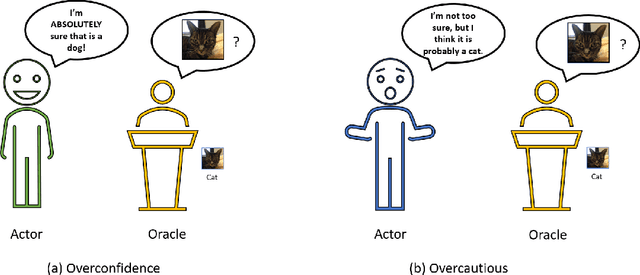

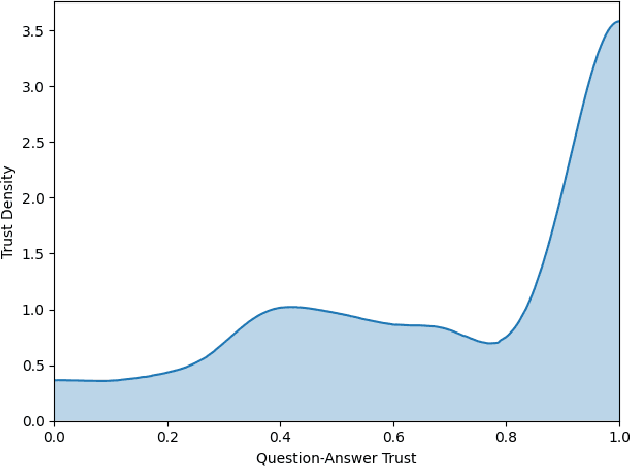
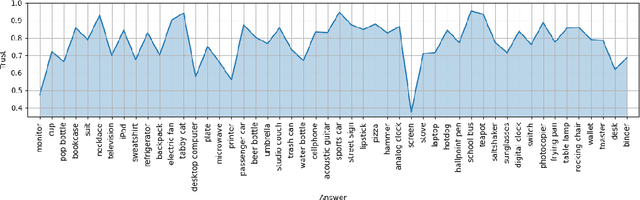
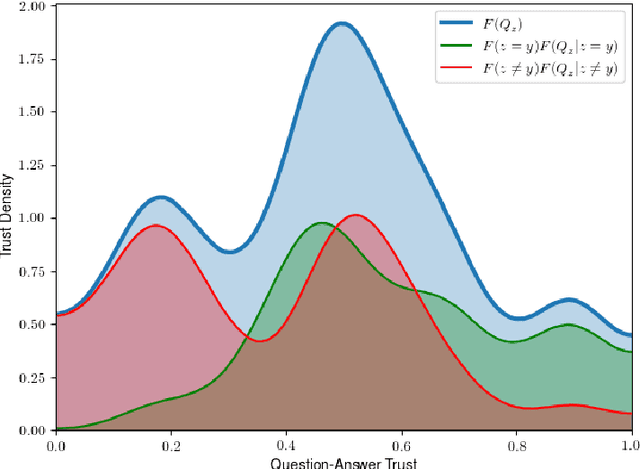
A critical step to building trustworthy deep neural networks is trust quantification, where we ask the question: How much can we trust a deep neural network? In this study, we take a step towards simple, interpretable metrics for trust quantification by introducing a suite of metrics for assessing the overall trustworthiness of deep neural networks based on their behaviour when answering a set of questions. We conduct a thought experiment and explore two key questions about trust in relation to confidence: 1) How much trust do we have in actors who give wrong answers with great confidence? and 2) How much trust do we have in actors who give right answers hesitantly? Based on insights gained, we introduce the concept of question-answer trust to quantify trustworthiness of an individual answer based on confident behaviour under correct and incorrect answer scenarios, and the concept of trust density to characterize the distribution of overall trust for an individual answer scenario. We further introduce the concept of trust spectrum for representing overall trust with respect to the spectrum of possible answer scenarios across correctly and incorrectly answered questions. Finally, we introduce NetTrustScore, a scalar metric summarizing overall trustworthiness. The suite of metrics aligns with past social psychology studies that study the relationship between trust and confidence. Leveraging these metrics, we quantify the trustworthiness of several well-known deep neural network architectures for image recognition to get a deeper understanding of where trust breaks down. The proposed metrics are by no means perfect, but the hope is to push the conversation towards better metrics to help guide practitioners and regulators in producing, deploying, and certifying deep learning solutions that can be trusted to operate in real-world, mission-critical scenarios.
DeepLABNet: End-to-end Learning of Deep Radial Basis Networks with Fully Learnable Basis Functions
Nov 21, 2019
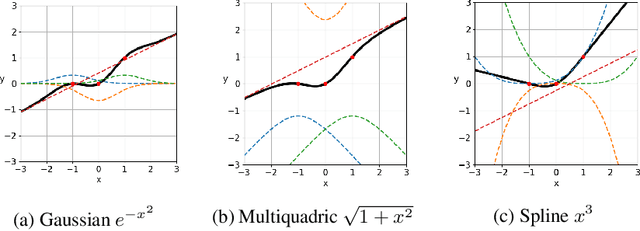

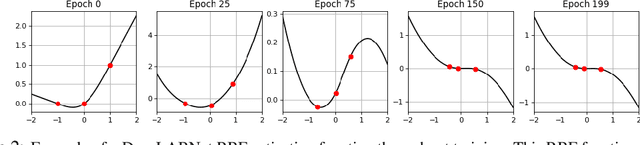
From fully connected neural networks to convolutional neural networks, the learned parameters within a neural network have been primarily relegated to the linear parameters (e.g., convolutional filters). The non-linear functions (e.g., activation functions) have largely remained, with few exceptions in recent years, parameter-less, static throughout training, and seen limited variation in design. Largely ignored by the deep learning community, radial basis function (RBF) networks provide an interesting mechanism for learning more complex non-linear activation functions in addition to the linear parameters in a network. However, the interest in RBF networks has waned over time due to the difficulty of integrating RBFs into more complex deep neural network architectures in a tractable and stable manner. In this work, we present a novel approach that enables end-to-end learning of deep RBF networks with fully learnable activation basis functions in an automatic and tractable manner. We demonstrate that our approach for enabling the use of learnable activation basis functions in deep neural networks, which we will refer to as DeepLABNet, is an effective tool for automated activation function learning within complex network architectures.
State of Compact Architecture Search For Deep Neural Networks
Oct 15, 2019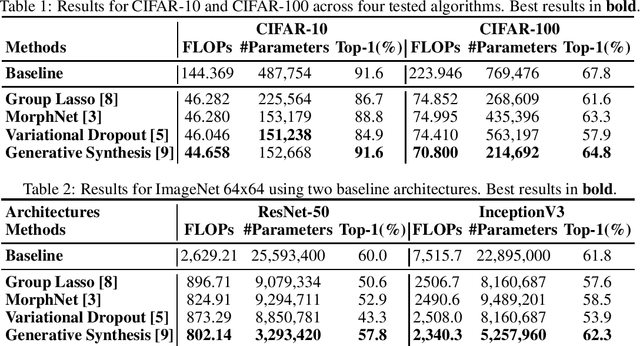
The design of compact deep neural networks is a crucial task to enable widespread adoption of deep neural networks in the real-world, particularly for edge and mobile scenarios. Due to the time-consuming and challenging nature of manually designing compact deep neural networks, there has been significant recent research interest into algorithms that automatically search for compact network architectures. A particularly interesting class of compact architecture search algorithms are those that are guided by baseline network architectures. Such algorithms have been shown to be significantly more computationally efficient than unguided methods. In this study, we explore the current state of compact architecture search for deep neural networks through both theoretical and empirical analysis of four different state-of-the-art compact architecture search algorithms: i) group lasso regularization, ii) variational dropout, iii) MorphNet, and iv) Generative Synthesis. We examine these methods in detail based on a number of different factors such as efficiency, effectiveness, and scalability. Furthermore, empirical evaluations are conducted to compare the efficacy of these compact architecture search algorithms across three well-known benchmark datasets. While by no means an exhaustive exploration, we hope that this study helps provide insights into the interesting state of this relatively new area of research in terms of diversity and real, tangible gains already achieved in architecture design improvements. Furthermore, the hope is that this study would help in pushing the conversation forward towards a deeper theoretical and empirical understanding where the research community currently stands in the landscape of compact architecture search for deep neural networks, and the practical challenges and considerations in leveraging such approaches for operational usage.