 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Intent from Role: Adversarial Self-Play for Persona-Invariant Safety Alignment
May 03, 2026The growing capabilities of large language models (LLMs) have driven their widespread deployment across diverse domains, even in potentially high-risk scenarios. Despite advances in safety alignment techniques, current models remain vulnerable to emerging persona-based jailbreak attacks. Existing research on persona-based jailbreak has primarily focused on attack iterations, yet it lacks systemic and mechanistic constraints on the defense side. To address this challenge, we propose Persona-Invariant Alignment (PIA), an adversarial self-play framework that achieves co-evolution through Persona Lineage Evolution (PLE) on the attack side and Persona-Invariant Consistency Learning (PICL) on the defense side. Theoretically, PICL is grounded in the structural separation hypothesis, using a unilateral KL-divergence constraint to enable the structural decoupling of safety decisions from persona context, thereby maintaining safe behavior under persona-based jailbreak attacks. Experimental results demonstrate that PLE efficiently explores high-risk persona spaces by leveraging lineage-based credit propagation. Meanwhile, the PICL defense method significantly reduces the Attack Success Rate (ASR) while preserving the model's general capability, thereby validating the superiority and robustness of this alignment paradigm. Codes are available at https://github.com/JiajiaLi-1130/PIA.
MAGIC: A Co-Evolving Attacker-Defender Adversarial Game for Robust LLM Safety
Feb 02, 2026Ensuring robust safety alignment is crucial for Large Language Models (LLMs), yet existing defenses often lag behind evolving adversarial attacks due to their \textbf{reliance on static, pre-collected data distributions}. In this paper, we introduce \textbf{MAGIC}, a novel multi-turn multi-agent reinforcement learning framework that formulates LLM safety alignment as an adversarial asymmetric game. Specifically, an attacker agent learns to iteratively rewrite original queries into deceptive prompts, while a defender agent simultaneously optimizes its policy to recognize and refuse such inputs. This dynamic process triggers a \textbf{co-evolution}, where the attacker's ever-changing strategies continuously uncover long-tail vulnerabilities, driving the defender to generalize to unseen attack patterns. Remarkably, we observe that the attacker, endowed with initial reasoning ability, evolves \textbf{novel, previously unseen combinatorial strategies} through iterative RL training, underscoring our method's substantial potential. Theoretically, we provide insights into a more robust game equilibrium and derive safety guarantees. Extensive experiments validate our framework's effectiveness, demonstrating superior defense success rates without compromising the helpfulness of the model. Our code is available at https://github.com/BattleWen/MAGIC.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Contrastive Representation for Data Filtering in Cross-Domain Offline Reinforcement Learning
May 10, 2024



Cross-domain offline reinforcement learning leverages source domain data with diverse transition dynamics to alleviate the data requirement for the target domain. However, simply merging the data of two domains leads to performance degradation due to the dynamics mismatch. Existing methods address this problem by measuring the dynamics gap via domain classifiers while relying on the assumptions of the transferability of paired domains. In this paper, we propose a novel representation-based approach to measure the domain gap, where the representation is learned through a contrastive objective by sampling transitions from different domains. We show that such an objective recovers the mutual-information gap of transition functions in two domains without suffering from the unbounded issue of the dynamics gap in handling significantly different domains. Based on the representations, we introduce a data filtering algorithm that selectively shares transitions from the source domain according to the contrastive score functions. Empirical results on various tasks demonstrate that our method achieves superior performance, using only 10% of the target data to achieve 89.2% of the performance on 100% target dataset with state-of-the-art methods.
Towards Robust Offline-to-Online Reinforcement Learning via Uncertainty and Smoothness
Sep 29, 2023
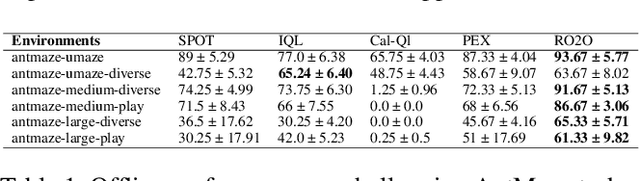
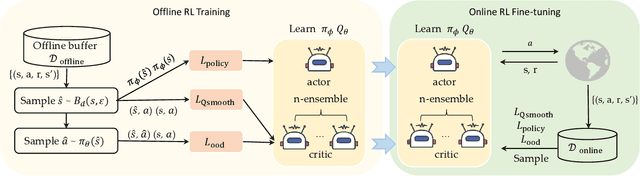
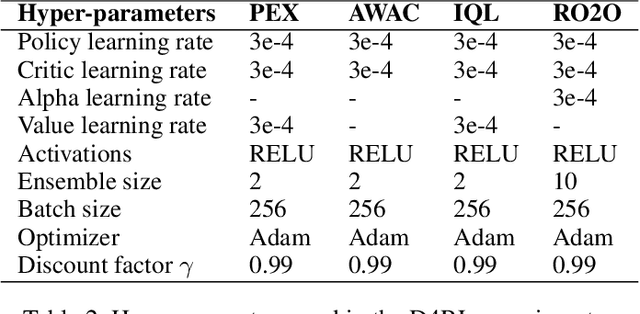
To obtain a near-optimal policy with fewer interactions in Reinforcement Learning (RL), a promising approach involves the combination of offline RL, which enhances sample efficiency by leveraging offline datasets, and online RL, which explores informative transitions by interacting with the environment. Offline-to-Online (O2O) RL provides a paradigm for improving an offline trained agent within limited online interactions. However, due to the significant distribution shift between online experiences and offline data, most offline RL algorithms suffer from performance drops and fail to achieve stable policy improvement in O2O adaptation. To address this problem, we propose the Robust Offline-to-Online (RO2O) algorithm, designed to enhance offline policies through uncertainty and smoothness, and to mitigate the performance drop in online adaptation. Specifically, RO2O incorporates Q-ensemble for uncertainty penalty and adversarial samples for policy and value smoothness, which enable RO2O to maintain a consistent learning procedure in online adaptation without requiring special changes to the learning objective. Theoretical analyses in linear MDPs demonstrate that the uncertainty and smoothness lead to a tighter optimality bound in O2O against distribution shift. Experimental results illustrate the superiority of RO2O in facilitating stable offline-to-online learning and achieving significant improvement with limited online interactions.
AttendSeg: A Tiny Attention Condenser Neural Network for Semantic Segmentation on the Edge
Apr 29, 2021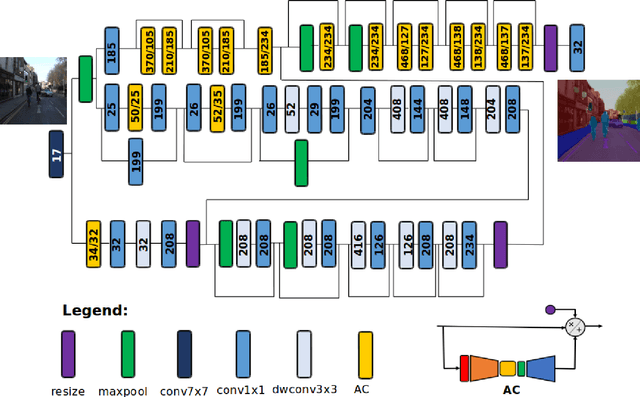


In this study, we introduce \textbf{AttendSeg}, a low-precision, highly compact deep neural network tailored for on-device semantic segmentation. AttendSeg possesses a self-attention network architecture comprising of light-weight attention condensers for improved spatial-channel selective attention at a very low complexity. The unique macro-architecture and micro-architecture design properties of AttendSeg strike a strong balance between representational power and efficiency, achieved via a machine-driven design exploration strategy tailored specifically for the task at hand. Experimental results demonstrated that the proposed AttendSeg can achieve segmentation accuracy comparable to much larger deep neural networks with greater complexity while possessing a significantly lower architecture and computational complexity (requiring as much as >27x fewer MACs, >72x fewer parameters, and >288x lower weight memory requirements), making it well-suited for TinyML applications on the edge.