 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Successor Representations for Task Generalization in Offline-to-Online Reinforcement Learning
May 12, 2024In Reinforcement Learning (RL), training a policy from scratch with online experiences can be inefficient because of the difficulties in exploration. Recently, offline RL provides a promising solution by giving an initialized offline policy, which can be refined through online interactions. However, existing approaches primarily perform offline and online learning in the same task, without considering the task generalization problem in offline-to-online adaptation. In real-world applications, it is common that we only have an offline dataset from a specific task while aiming for fast online-adaptation for several tasks. To address this problem, our work builds upon the investigation of successor representations for task generalization in online RL and extends the framework to incorporate offline-to-online learning. We demonstrate that the conventional paradigm using successor features cannot effectively utilize offline data and improve the performance for the new task by online fine-tuning. To mitigate this, we introduce a novel methodology that leverages offline data to acquire an ensemble of successor representations and subsequently constructs ensemble Q functions. This approach enables robust representation learning from datasets with different coverage and facilitates fast adaption of Q functions towards new tasks during the online fine-tuning phase. Extensive empirical evaluations provide compelling evidence showcasing the superior performance of our method in generalizing to diverse or even unseen tasks.
Contrastive Representation for Data Filtering in Cross-Domain Offline Reinforcement Learning
May 10, 2024



Cross-domain offline reinforcement learning leverages source domain data with diverse transition dynamics to alleviate the data requirement for the target domain. However, simply merging the data of two domains leads to performance degradation due to the dynamics mismatch. Existing methods address this problem by measuring the dynamics gap via domain classifiers while relying on the assumptions of the transferability of paired domains. In this paper, we propose a novel representation-based approach to measure the domain gap, where the representation is learned through a contrastive objective by sampling transitions from different domains. We show that such an objective recovers the mutual-information gap of transition functions in two domains without suffering from the unbounded issue of the dynamics gap in handling significantly different domains. Based on the representations, we introduce a data filtering algorithm that selectively shares transitions from the source domain according to the contrastive score functions. Empirical results on various tasks demonstrate that our method achieves superior performance, using only 10% of the target data to achieve 89.2% of the performance on 100% target dataset with state-of-the-art methods.
Diverse Randomized Value Functions: A Provably Pessimistic Approach for Offline Reinforcement Learning
Apr 09, 2024
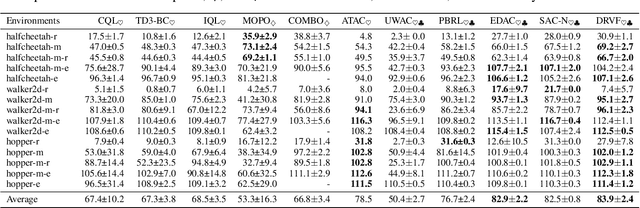

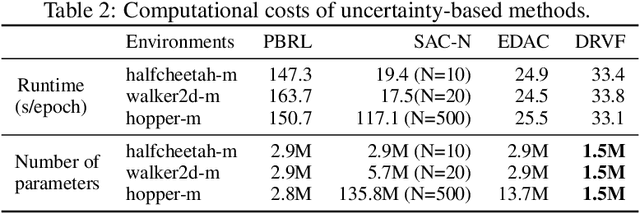
Offline Reinforcement Learning (RL) faces distributional shift and unreliable value estimation, especially for out-of-distribution (OOD) actions. To address this, existing uncertainty-based methods penalize the value function with uncertainty quantification and demand numerous ensemble networks, posing computational challenges and suboptimal outcomes. In this paper, we introduce a novel strategy employing diverse randomized value functions to estimate the posterior distribution of $Q$-values. It provides robust uncertainty quantification and estimates lower confidence bounds (LCB) of $Q$-values. By applying moderate value penalties for OOD actions, our method fosters a provably pessimistic approach. We also emphasize on diversity within randomized value functions and enhance efficiency by introducing a diversity regularization method, reducing the requisite number of networks. These modules lead to reliable value estimation and efficient policy learning from offline data. Theoretical analysis shows that our method recovers the provably efficient LCB-penalty under linear MDP assumptions. Extensive empirical results also demonstrate that our proposed method significantly outperforms baseline methods in terms of performance and parametric efficiency.
Regularized Conditional Diffusion Model for Multi-Task Preference Alignment
Apr 07, 2024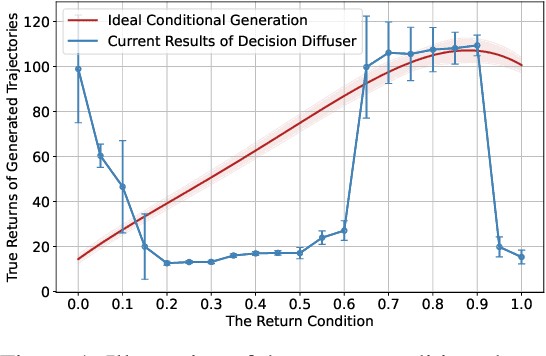



Sequential decision-making is desired to align with human intents and exhibit versatility across various tasks. Previous methods formulate it as a conditional generation process, utilizing return-conditioned diffusion models to directly model trajectory distributions. Nevertheless, the return-conditioned paradigm relies on pre-defined reward functions, facing challenges when applied in multi-task settings characterized by varying reward functions (versatility) and showing limited controllability concerning human preferences (alignment). In this work, we adopt multi-task preferences as a unified condition for both single- and multi-task decision-making, and propose preference representations aligned with preference labels. The learned representations are used to guide the conditional generation process of diffusion models, and we introduce an auxiliary objective to maximize the mutual information between representations and corresponding generated trajectories, improving alignment between trajectories and preferences. Extensive experiments in D4RL and Meta-World demonstrate that our method presents favorable performance in single- and multi-task scenarios, and exhibits superior alignment with preferences.
Towards Robust Offline-to-Online Reinforcement Learning via Uncertainty and Smoothness
Sep 29, 2023
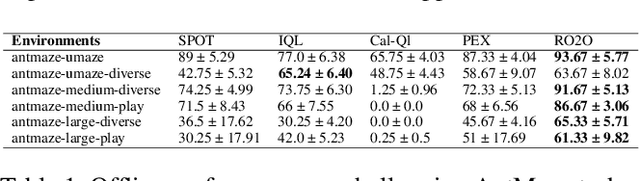
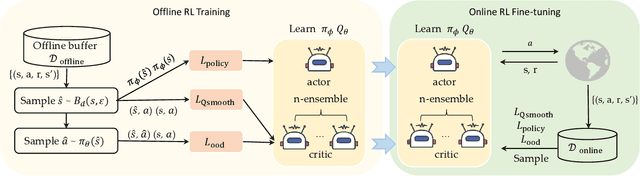
To obtain a near-optimal policy with fewer interactions in Reinforcement Learning (RL), a promising approach involves the combination of offline RL, which enhances sample efficiency by leveraging offline datasets, and online RL, which explores informative transitions by interacting with the environment. Offline-to-Online (O2O) RL provides a paradigm for improving an offline trained agent within limited online interactions. However, due to the significant distribution shift between online experiences and offline data, most offline RL algorithms suffer from performance drops and fail to achieve stable policy improvement in O2O adaptation. To address this problem, we propose the Robust Offline-to-Online (RO2O) algorithm, designed to enhance offline policies through uncertainty and smoothness, and to mitigate the performance drop in online adaptation. Specifically, RO2O incorporates Q-ensemble for uncertainty penalty and adversarial samples for policy and value smoothness, which enable RO2O to maintain a consistent learning procedure in online adaptation without requiring special changes to the learning objective. Theoretical analyses in linear MDPs demonstrate that the uncertainty and smoothness lead to a tighter optimality bound in O2O against distribution shift. Experimental results illustrate the superiority of RO2O in facilitating stable offline-to-online learning and achieving significant improvement with limited online interactions.