 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights into Fairness through Trust: Multi-scale Trust Quantification for Financial Deep Learning
Nov 03, 2020
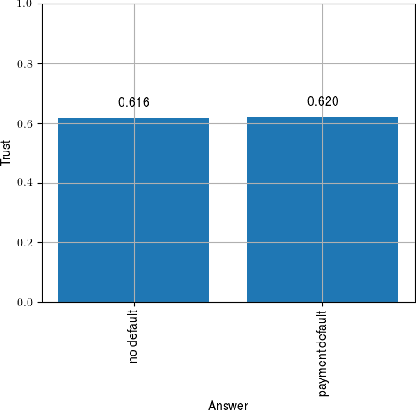
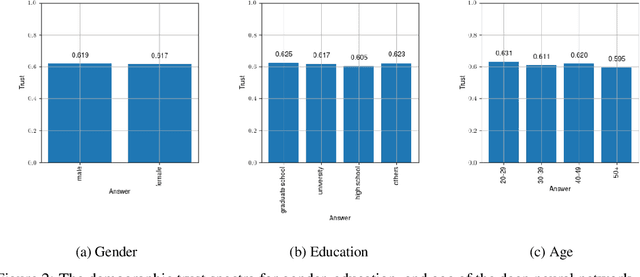
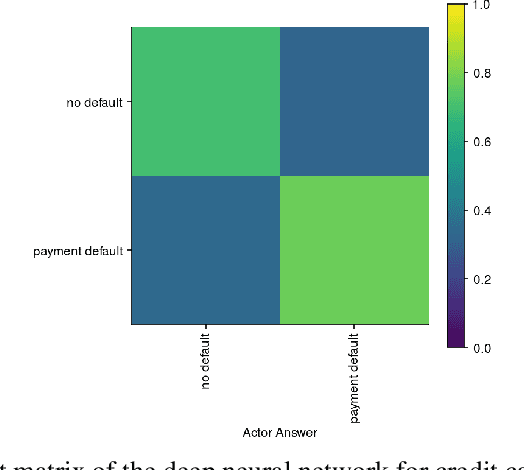
The success of deep learning in recent years have led to a significant increase in interest and prevalence for its adoption to tackle financial services tasks. One particular question that often arises as a barrier to adopting deep learning for financial services is whether the developed financial deep learning models are fair in their predictions, particularly in light of strong governance and regulatory compliance requirements in the financial services industry. A fundamental aspect of fairness that has not been explored in financial deep learning is the concept of trust, whose variations may point to an egocentric view of fairness and thus provide insights into the fairness of models. In this study we explore the feasibility and utility of a multi-scale trust quantification strategy to gain insights into the fairness of a financial deep learning model, particularly under different scenarios at different scales. More specifically, we conduct multi-scale trust quantification on a deep neural network for the purpose of credit card default prediction to study: 1) the overall trustworthiness of the model 2) the trust level under all possible prediction-truth relationships, 3) the trust level across the spectrum of possible predictions, 4) the trust level across different demographic groups (e.g., age, gender, and education), and 5) distribution of overall trust for an individual prediction scenario. The insights for this proof-of-concept study demonstrate that such a multi-scale trust quantification strategy may be helpful for data scientists and regulators in financial services as part of the verification and certification of financial deep learning solutions to gain insights into fairness and trust of these solutions.
Where Does Trust Break Down? A Quantitative Trust Analysis of Deep Neural Networks via Trust Matrix and Conditional Trust Densities
Sep 30, 2020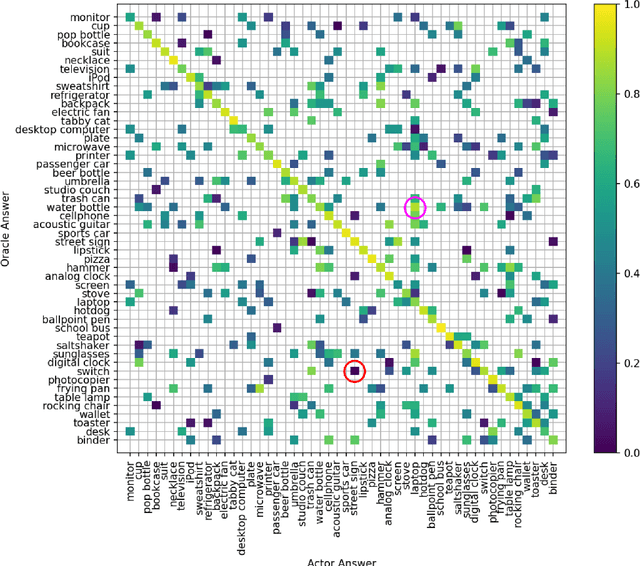
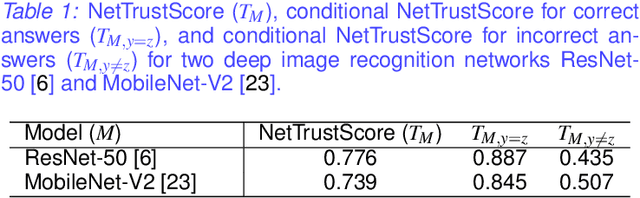
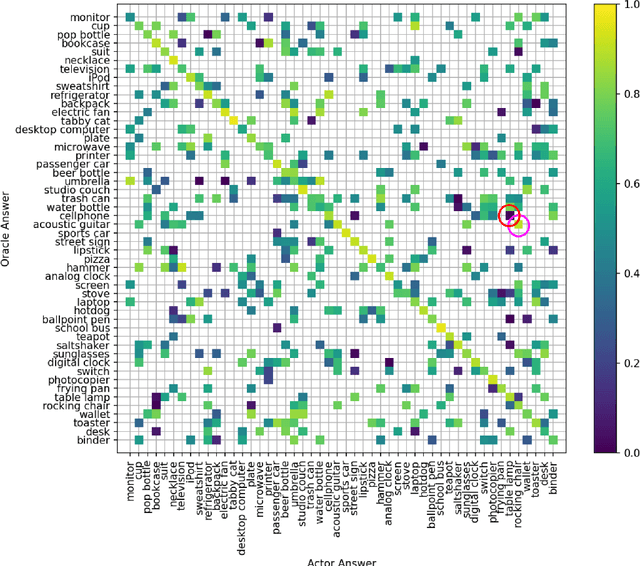
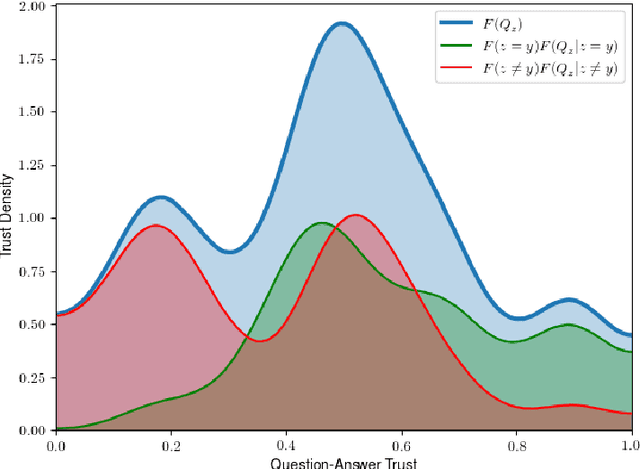
The advances and successes in deep learning in recent years have led to considerable efforts and investments into its widespread ubiquitous adoption for a wide variety of applications, ranging from personal assistants and intelligent navigation to search and product recommendation in e-commerce. With this tremendous rise in deep learning adoption comes questions about the trustworthiness of the deep neural networks that power these applications. Motivated to answer such questions, there has been a very recent interest in trust quantification. In this work, we introduce the concept of trust matrix, a novel trust quantification strategy that leverages the recently introduced question-answer trust metric by Wong et al. to provide deeper, more detailed insights into where trust breaks down for a given deep neural network given a set of questions. More specifically, a trust matrix defines the expected question-answer trust for a given actor-oracle answer scenario, allowing one to quickly spot areas of low trust that needs to be addressed to improve the trustworthiness of a deep neural network. The proposed trust matrix is simple to calculate, humanly interpretable, and to the best of the authors' knowledge is the first to study trust at the actor-oracle answer level. We further extend the concept of trust densities with the notion of conditional trust densities. We experimentally leverage trust matrices to study several well-known deep neural network architectures for image recognition, and further study the trust density and conditional trust densities for an interesting actor-oracle answer scenario. The results illustrate that trust matrices, along with conditional trust densities, can be useful tools in addition to the existing suite of trust quantification metrics for guiding practitioners and regulators in creating and certifying deep learning solutions for trusted operation.
How Much Can We Really Trust You? Towards Simple, Interpretable Trust Quantification Metrics for Deep Neural Networks
Sep 20, 2020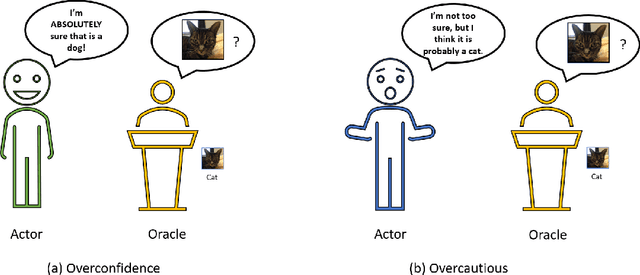

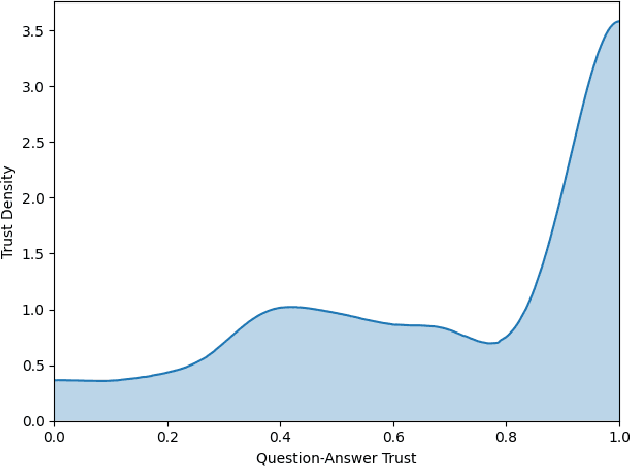
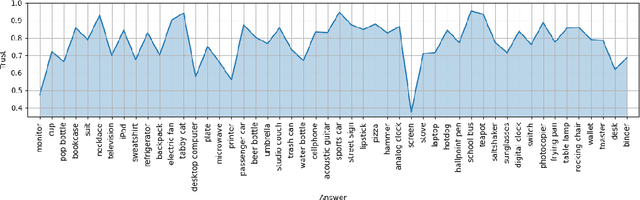
A critical step to building trustworthy deep neural networks is trust quantification, where we ask the question: How much can we trust a deep neural network? In this study, we take a step towards simple, interpretable metrics for trust quantification by introducing a suite of metrics for assessing the overall trustworthiness of deep neural networks based on their behaviour when answering a set of questions. We conduct a thought experiment and explore two key questions about trust in relation to confidence: 1) How much trust do we have in actors who give wrong answers with great confidence? and 2) How much trust do we have in actors who give right answers hesitantly? Based on insights gained, we introduce the concept of question-answer trust to quantify trustworthiness of an individual answer based on confident behaviour under correct and incorrect answer scenarios, and the concept of trust density to characterize the distribution of overall trust for an individual answer scenario. We further introduce the concept of trust spectrum for representing overall trust with respect to the spectrum of possible answer scenarios across correctly and incorrectly answered questions. Finally, we introduce NetTrustScore, a scalar metric summarizing overall trustworthiness. The suite of metrics aligns with past social psychology studies that study the relationship between trust and confidence. Leveraging these metrics, we quantify the trustworthiness of several well-known deep neural network architectures for image recognition to get a deeper understanding of where trust breaks down. The proposed metrics are by no means perfect, but the hope is to push the conversation towards better metrics to help guide practitioners and regulators in producing, deploying, and certifying deep learning solutions that can be trusted to operate in real-world, mission-critical scenarios.
Do Explanations Reflect Decisions? A Machine-centric Strategy to Quantify the Performance of Explainability Algorithms
Oct 29, 2019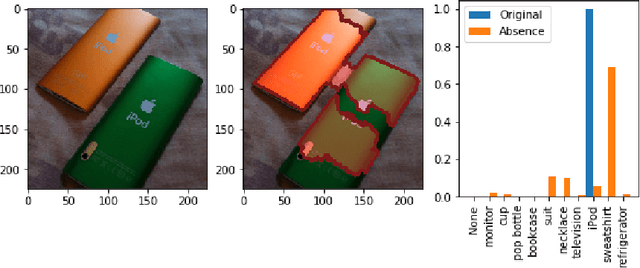
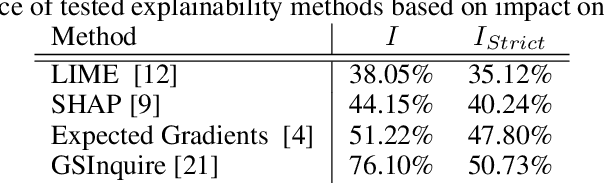
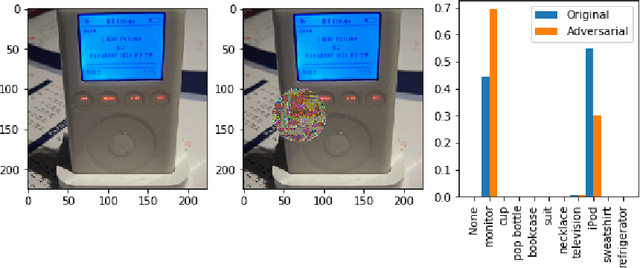

There has been a significant surge of interest recently around the concept of explainable artificial intelligence (XAI), where the goal is to produce an interpretation for a decision made by a machine learning algorithm. Of particular interest is the interpretation of how deep neural networks make decisions, given the complexity and `black box' nature of such networks. Given the infancy of the field, there has been very limited exploration into the assessment of the performance of explainability methods, with most evaluations centered around subjective visual interpretation of the produced interpretations. In this study, we explore a more machine-centric strategy for quantifying the performance of explainability methods on deep neural networks via the notion of decision-making impact analysis. We introduce two quantitative performance metrics: i) Impact Score, which assesses the percentage of critical factors with either strong confidence reduction impact or decision changing impact, and ii) Impact Coverage, which assesses the percentage coverage of adversarially impacted factors in the input. A comprehensive analysis using this approach was conducted on several state-of-the-art explainability methods (LIME, SHAP, Expected Gradients, GSInquire) on a ResNet-50 deep convolutional neural network using a subset of ImageNet for the task of image classification. Experimental results show that the critical regions identified by LIME within the tested images had the lowest impact on the decision-making process of the network (~38%), with progressive increase in decision-making impact for SHAP (~44%), Expected Gradients (~51%), and GSInquire (~76%). While by no means perfect, the hope is that the proposed machine-centric strategy helps push the conversation forward towards better metrics for evaluating explainability methods and improve trust in deep neural networks.
A deep-structured fully-connected random field model for structured inference
May 27, 2015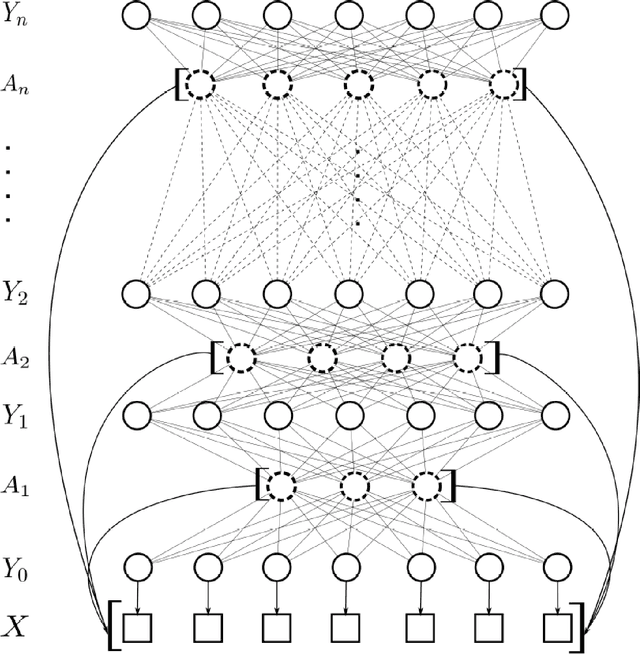
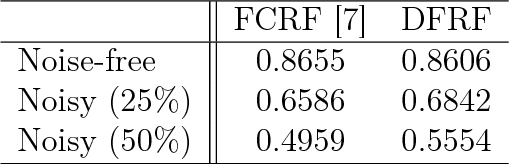

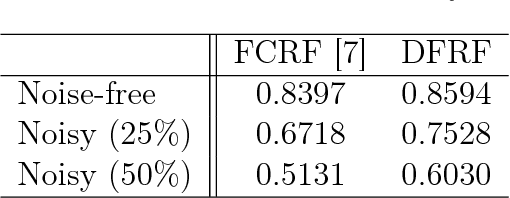
There has been significant interest in the use of fully-connected graphical models and deep-structured graphical models for the purpose of structured inference. However, fully-connected and deep-structured graphical models have been largely explored independently, leaving the unification of these two concepts ripe for exploration. A fundamental challenge with unifying these two types of models is in dealing with computational complexity. In this study, we investigate the feasibility of unifying fully-connected and deep-structured models in a computationally tractable manner for the purpose of structured inference. To accomplish this, we introduce a deep-structured fully-connected random field (DFRF) model that integrates a series of intermediate sparse auto-encoding layers placed between state layers to significantly reduce computational complexity. The problem of image segmentation was used to illustrate the feasibility of using the DFRF for structured inference in a computationally tractable manner. Results in this study show that it is feasible to unify fully-connected and deep-structured models in a computationally tractable manner for solving structured inference problems such as image segmentation.
* Accepted, 13 pages