 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantity over Quality: Training an AV Motion Planner with Large Scale Commodity Vision Data
Mar 03, 2022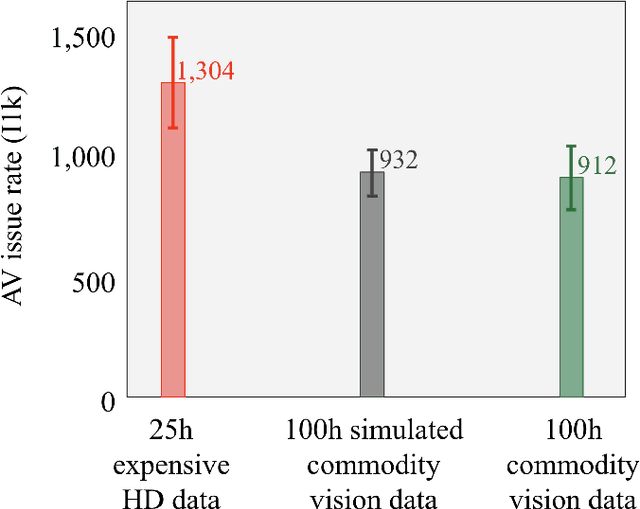
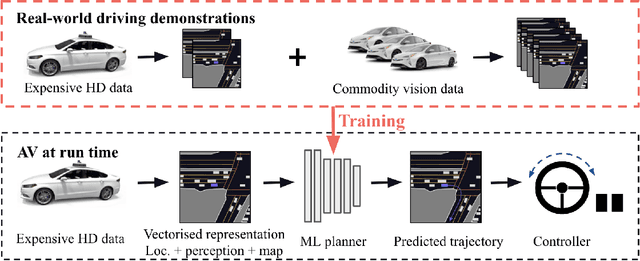
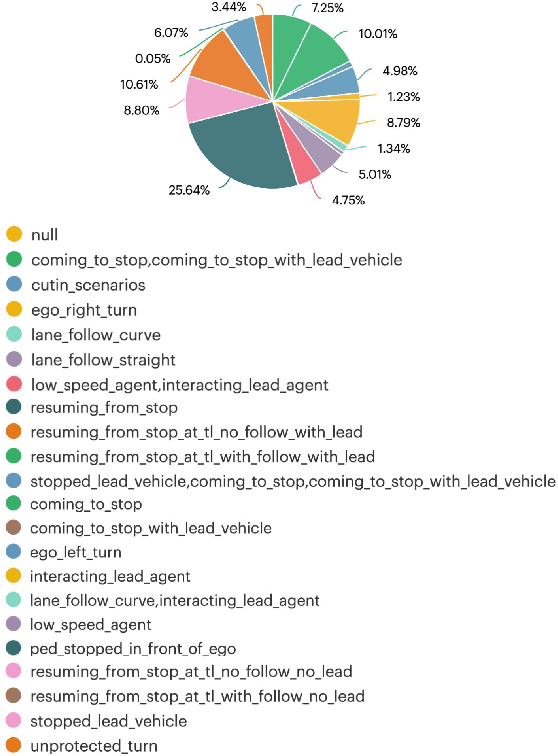
With the Autonomous Vehicle (AV) industry shifting towards Autonomy 2.0, the performance of self-driving systems starts to rely heavily on large quantities of expert driving demonstrations. However, collecting this demonstration data typically involves expensive HD sensor suites (LiDAR + RADAR + cameras), which quickly becomes financially infeasible at the scales required. This motivates the use of commodity vision sensors for data collection, which are an order of magnitude cheaper than the HD sensor suites, but offer lower fidelity. If it were possible to leverage these for training an AV motion planner, observing the `long tail' of driving events would become a financially viable strategy. As our main contribution we show it is possible to train a high-performance motion planner using commodity vision data which outperforms planners trained on HD-sensor data for a fraction of the cost. We do this by comparing the autonomy system performance when training on these two different sensor configurations, and showing that we can compensate for the lower sensor fidelity by means of increased quantity: a planner trained on 100h of commodity vision data outperforms one with 25h of expensive HD data. We also share the technical challenges we had to tackle to make this work. To the best of our knowledge, we are the first to demonstrate that this is possible using real-world data.
Scalable Primitives for Generalized Sensor Fusion in Autonomous Vehicles
Dec 01, 2021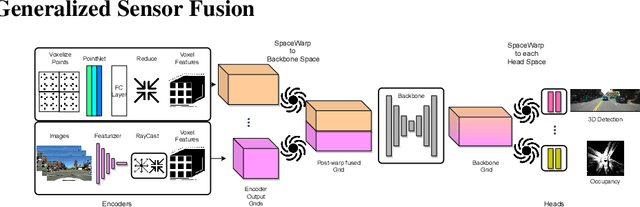
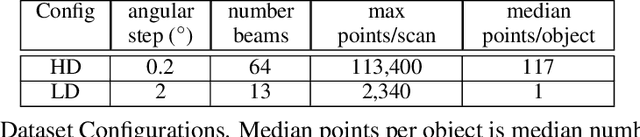
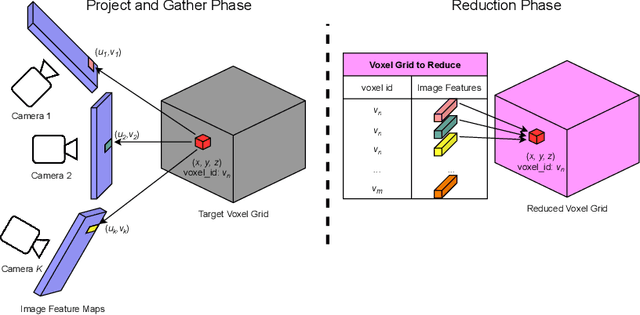

In autonomous driving, there has been an explosion in the use of deep neural networks for perception, prediction and planning tasks. As autonomous vehicles (AVs) move closer to production, multi-modal sensor inputs and heterogeneous vehicle fleets with different sets of sensor platforms are becoming increasingly common in the industry. However, neural network architectures typically target specific sensor platforms and are not robust to changes in input, making the problem of scaling and model deployment particularly difficult. Furthermore, most players still treat the problem of optimizing software and hardware as entirely independent problems. We propose a new end to end architecture, Generalized Sensor Fusion (GSF), which is designed in such a way that both sensor inputs and target tasks are modular and modifiable. This enables AV system designers to easily experiment with different sensor configurations and methods and opens up the ability to deploy on heterogeneous fleets using the same models that are shared across a large engineering organization. Using this system, we report experimental results where we demonstrate near-parity of an expensive high-density (HD) LiDAR sensor with a cheap low-density (LD) LiDAR plus camera setup in the 3D object detection task. This paves the way for the industry to jointly design hardware and software architectures as well as large fleets with heterogeneous configurations.