 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantity over Quality: Training an AV Motion Planner with Large Scale Commodity Vision Data
Mar 03, 2022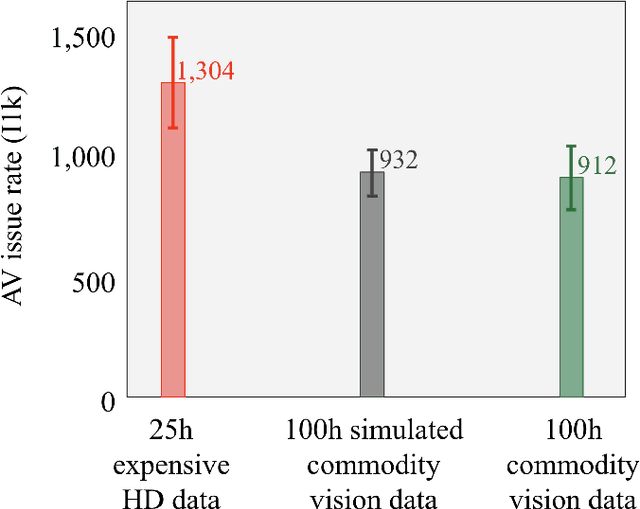
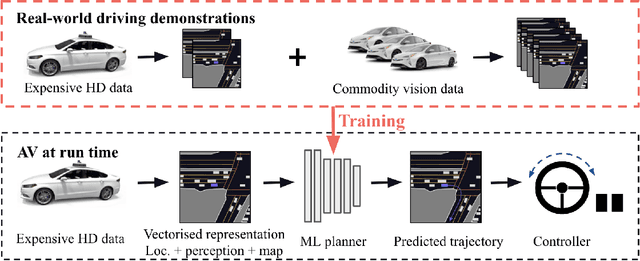
With the Autonomous Vehicle (AV) industry shifting towards Autonomy 2.0, the performance of self-driving systems starts to rely heavily on large quantities of expert driving demonstrations. However, collecting this demonstration data typically involves expensive HD sensor suites (LiDAR + RADAR + cameras), which quickly becomes financially infeasible at the scales required. This motivates the use of commodity vision sensors for data collection, which are an order of magnitude cheaper than the HD sensor suites, but offer lower fidelity. If it were possible to leverage these for training an AV motion planner, observing the `long tail' of driving events would become a financially viable strategy. As our main contribution we show it is possible to train a high-performance motion planner using commodity vision data which outperforms planners trained on HD-sensor data for a fraction of the cost. We do this by comparing the autonomy system performance when training on these two different sensor configurations, and showing that we can compensate for the lower sensor fidelity by means of increased quantity: a planner trained on 100h of commodity vision data outperforms one with 25h of expensive HD data. We also share the technical challenges we had to tackle to make this work. To the best of our knowledge, we are the first to demonstrate that this is possible using real-world data.
Autonomy 2.0: Why is self-driving always 5 years away?
Aug 09, 2021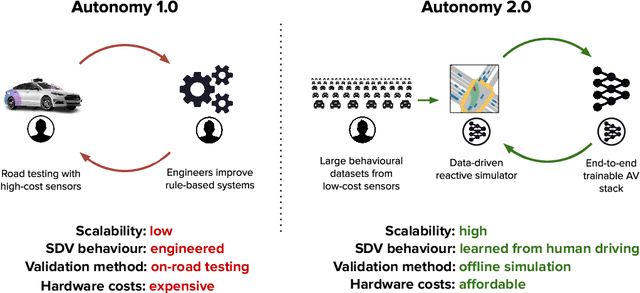

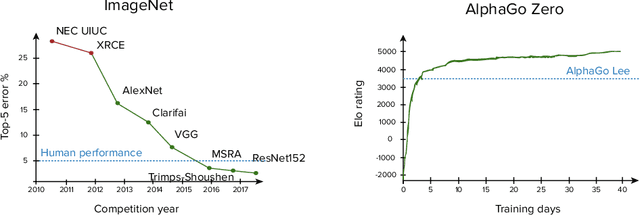
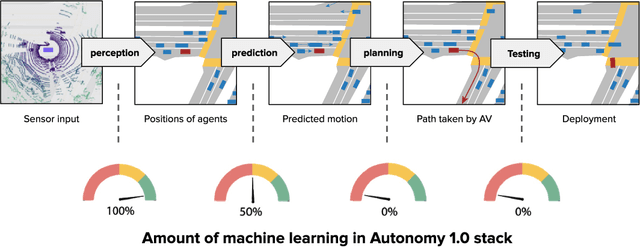
Despite the numerous successes of machine learning over the past decade (image recognition, decision-making, NLP, image synthesis), self-driving technology has not yet followed the same trend. In this paper, we study the history, composition, and development bottlenecks of the modern self-driving stack. We argue that the slow progress is caused by approaches that require too much hand-engineering, an over-reliance on road testing, and high fleet deployment costs. We observe that the classical stack has several bottlenecks that preclude the necessary scale needed to capture the long tail of rare events. To resolve these problems, we outline the principles of Autonomy 2.0, an ML-first approach to self-driving, as a viable alternative to the currently adopted state-of-the-art. This approach is based on (i) a fully differentiable AV stack trainable from human demonstrations, (ii) closed-loop data-driven reactive simulation, and (iii) large-scale, low-cost data collections as critical solutions towards scalability issues. We outline the general architecture, survey promising works in this direction and propose key challenges to be addressed by the community in the future.
SimNet: Learning Reactive Self-driving Simulations from Real-world Observations
May 26, 2021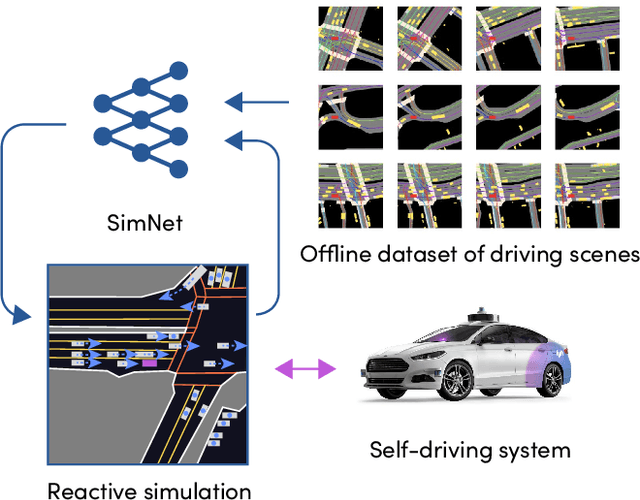
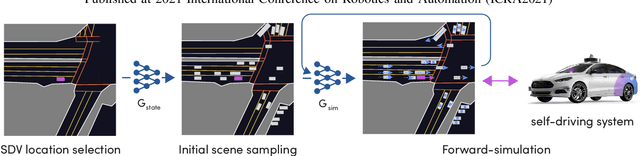
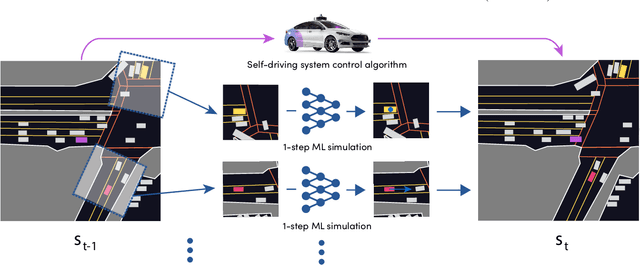
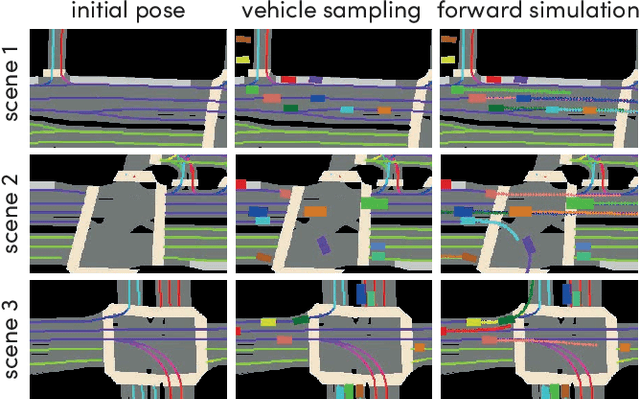
In this work, we present a simple end-to-end trainable machine learning system capable of realistically simulating driving experiences. This can be used for the verification of self-driving system performance without relying on expensive and time-consuming road testing. In particular, we frame the simulation problem as a Markov Process, leveraging deep neural networks to model both state distribution and transition function. These are trainable directly from the existing raw observations without the need for any handcrafting in the form of plant or kinematic models. All that is needed is a dataset of historical traffic episodes. Our formulation allows the system to construct never seen scenes that unfold realistically reacting to the self-driving car's behaviour. We train our system directly from 1,000 hours of driving logs and measure both realism, reactivity of the simulation as the two key properties of the simulation. At the same time, we apply the method to evaluate the performance of a recently proposed state-of-the-art ML planning system trained from human driving logs. We discover this planning system is prone to previously unreported causal confusion issues that are difficult to test by non-reactive simulation. To the best of our knowledge, this is the first work that directly merges highly realistic data-driven simulations with a closed-loop evaluation for self-driving vehicles. We make the data, code, and pre-trained models publicly available to further stimulate simulation development.
End-to-end learning of keypoint detection and matching for relative pose estimation
Apr 02, 2021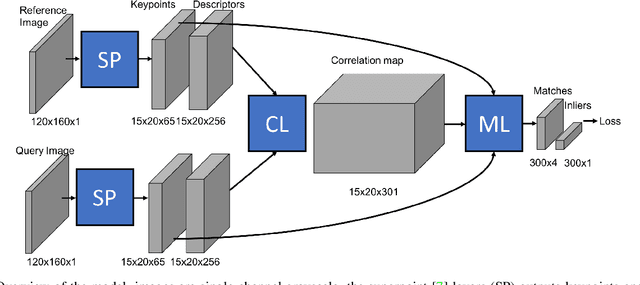
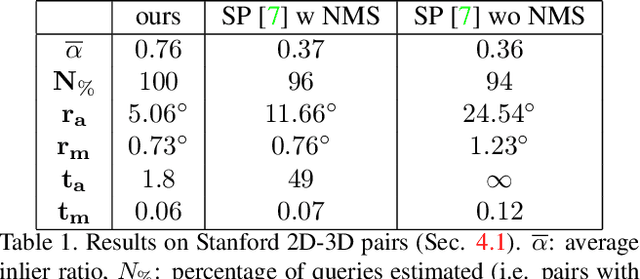
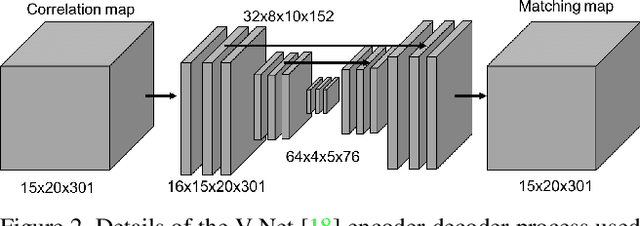

We propose a new method for estimating the relative pose between two images, where we jointly learn keypoint detection, description extraction, matching and robust pose estimation. While our architecture follows the traditional pipeline for pose estimation from geometric computer vision, all steps are learnt in an end-to-end fashion, including feature matching. We demonstrate our method for the task of visual localization of a query image within a database of images with known pose. Pairwise pose estimation has many practical applications for robotic mapping, navigation, and AR. For example, the display of persistent AR objects in the scene relies on a precise camera localization to make the digital models appear anchored to the physical environment. We train our pipeline end-to-end specifically for the problem of visual localization. We evaluate our proposed approach on localization accuracy, robustness and runtime speed. Our method achieves state of the art localization accuracy on the 7 Scenes dataset.
Collaborative Augmented Reality on Smartphones via Life-long City-scale Maps
Nov 10, 2020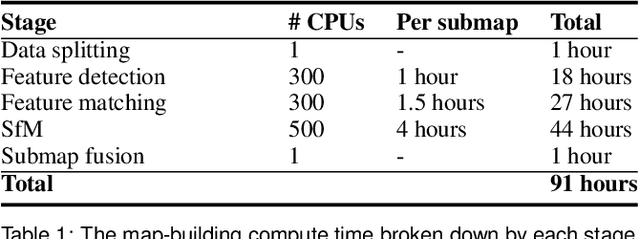
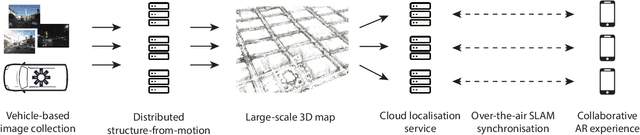
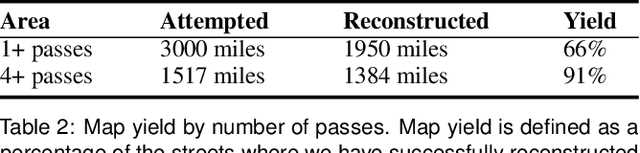
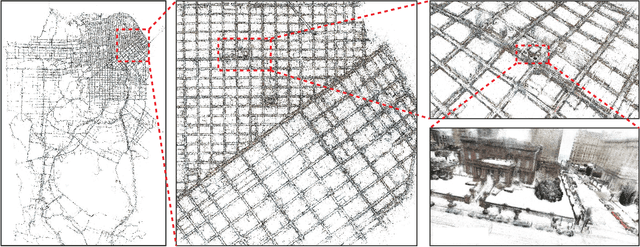
In this paper we present the first published end-to-end production computer-vision system for powering city-scale shared augmented reality experiences on mobile devices. In doing so we propose a new formulation for an experience-based mapping framework as an effective solution to the key issues of city-scale SLAM scalability, robustness, map updates and all-time all-weather performance required by a production system. Furthermore, we propose an effective way of synchronising SLAM systems to deliver seamless real-time localisation of multiple edge devices at the same time. All this in the presence of network latency and bandwidth limitations. The resulting system is deployed and tested at scale in San Francisco where it delivers AR experiences in a mapped area of several hundred kilometers. To foster further development of this area we offer the data set to the public, constituting the largest of this kind to date.
Recovering Spatiotemporal Correspondence between Deformable Objects by Exploiting Consistent Foreground Motion in Video
Aug 16, 2016

Given unstructured videos of deformable objects, we automatically recover spatiotemporal correspondences to map one object to another (such as animals in the wild). While traditional methods based on appearance fail in such challenging conditions, we exploit consistency in object motion between instances. Our approach discovers pairs of short video intervals where the object moves in a consistent manner and uses these candidates as seeds for spatial alignment. We model the spatial correspondence between the point trajectories on the object in one interval to those in the other using a time-varying Thin Plate Spline deformation model. On a large dataset of tiger and horse videos, our method automatically aligns thousands of pairs of frames to a high accuracy, and outperforms the popular SIFT Flow algorithm.
Behavior Discovery and Alignment of Articulated Object Classes from Unstructured Video
Aug 11, 2016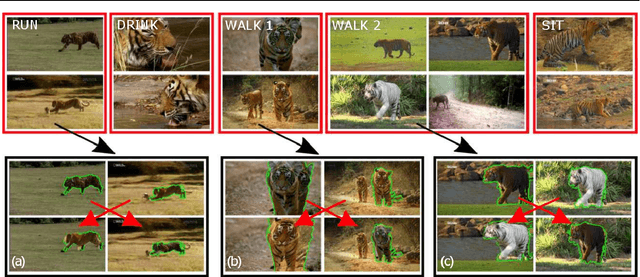
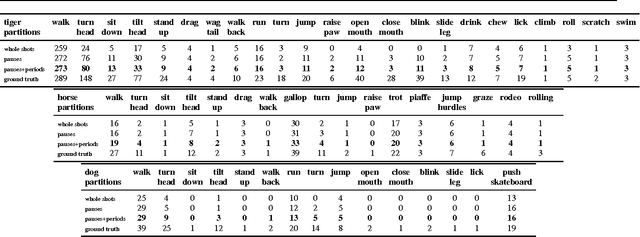
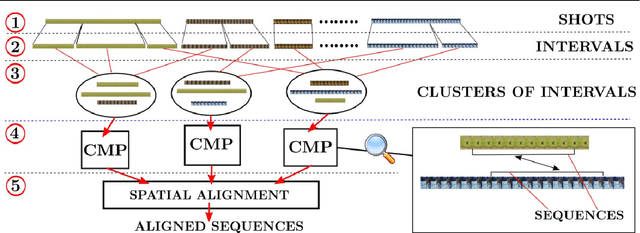
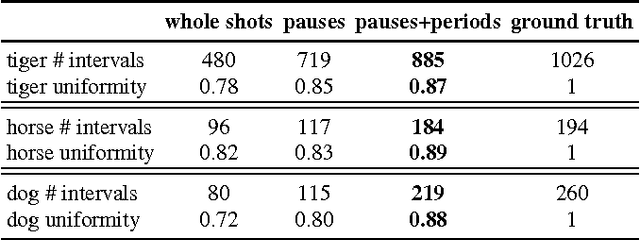
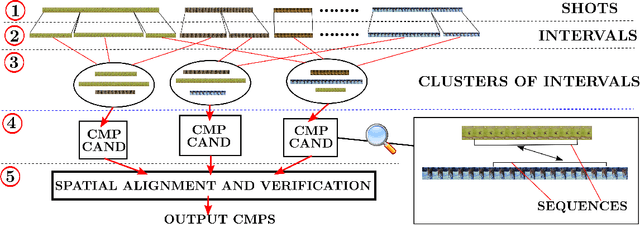
We propose an automatic system for organizing the content of a collection of unstructured videos of an articulated object class (e.g. tiger, horse). By exploiting the recurring motion patterns of the class across videos, our system: 1) identifies its characteristic behaviors; and 2) recovers pixel-to-pixel alignments across different instances. Our system can be useful for organizing video collections for indexing and retrieval. Moreover, it can be a platform for learning the appearance or behaviors of object classes from Internet video. Traditional supervised techniques cannot exploit this wealth of data directly, as they require a large amount of time-consuming manual annotations. The behavior discovery stage generates temporal video intervals, each automatically trimmed to one instance of the discovered behavior, clustered by type. It relies on our novel motion representation for articulated motion based on the displacement of ordered pairs of trajectories (PoTs). The alignment stage aligns hundreds of instances of the class to a great accuracy despite considerable appearance variations (e.g. an adult tiger and a cub). It uses a flexible Thin Plate Spline deformation model that can vary through time. We carefully evaluate each step of our system on a new, fully annotated dataset. On behavior discovery, we outperform the state-of-the-art Improved DTF descriptor. On spatial alignment, we outperform the popular SIFT Flow algorithm.
* 19 pages, 19 figure, 3 tables. arXiv admin note: substantial text overlap with arXiv:1411.7883
Articulated motion discovery using pairs of trajectories
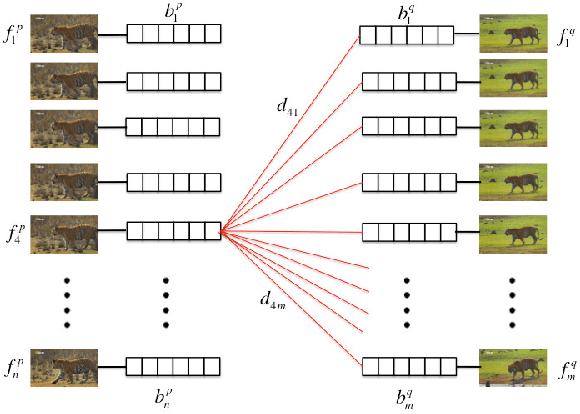
Apr 24, 2015
We propose an unsupervised approach for discovering characteristic motion patterns in videos of highly articulated objects performing natural, unscripted behaviors, such as tigers in the wild. We discover consistent patterns in a bottom-up manner by analyzing the relative displacements of large numbers of ordered trajectory pairs through time, such that each trajectory is attached to a different moving part on the object. The pairs of trajectories descriptor relies entirely on motion and is more discriminative than state-of-the-art features that employ single trajectories. Our method generates temporal video intervals, each automatically trimmed to one instance of the discovered behavior, and clusters them by type (e.g., running, turning head, drinking water). We present experiments on two datasets: dogs from YouTube-Objects and a new dataset of National Geographic tiger videos. Results confirm that our proposed descriptor outperforms existing appearance- and trajectory-based descriptors (e.g., HOG and DTFs) on both datasets and enables us to segment unconstrained animal video into intervals containing single behaviors.