 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end learning of keypoint detection and matching for relative pose estimation
Apr 02, 2021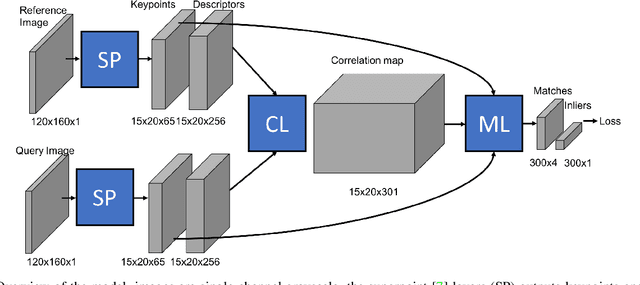
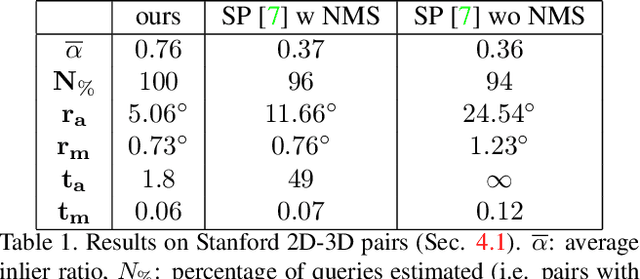
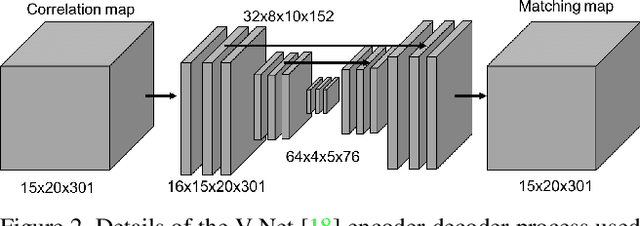

We propose a new method for estimating the relative pose between two images, where we jointly learn keypoint detection, description extraction, matching and robust pose estimation. While our architecture follows the traditional pipeline for pose estimation from geometric computer vision, all steps are learnt in an end-to-end fashion, including feature matching. We demonstrate our method for the task of visual localization of a query image within a database of images with known pose. Pairwise pose estimation has many practical applications for robotic mapping, navigation, and AR. For example, the display of persistent AR objects in the scene relies on a precise camera localization to make the digital models appear anchored to the physical environment. We train our pipeline end-to-end specifically for the problem of visual localization. We evaluate our proposed approach on localization accuracy, robustness and runtime speed. Our method achieves state of the art localization accuracy on the 7 Scenes dataset.
Joint Facade Registration and Segmentation for Urban Localization
Nov 25, 2018



This paper presents an efficient approach for solving jointly facade registration and semantic segmentation. Progress in facade detection and recognition enable good initialization for the registration of a reference facade to a newly acquired target image. We propose here to rely on semantic segmentation to improve the accuracy of that initial registration. Simultaneously we aim to improve the quality of the semantic segmentation through the registration. These two problems are jointly solved in a Expectation-Maximization framework. We especially introduce a bayesian model that use prior semantic segmentation as well as geometric structure of the facade reference modeled by $L_p$ Gaussian Mixtures. We show the advantages of our method in term of robustness to clutter and change of illumination on urban images from various database.