 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning
Oct 16, 2023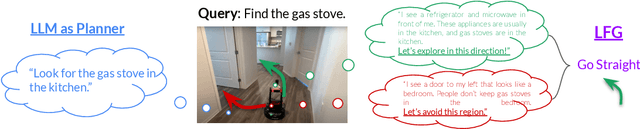

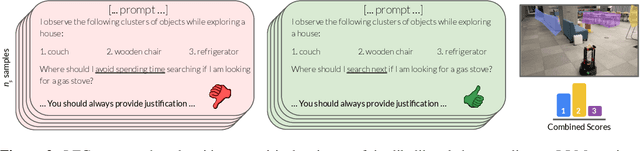
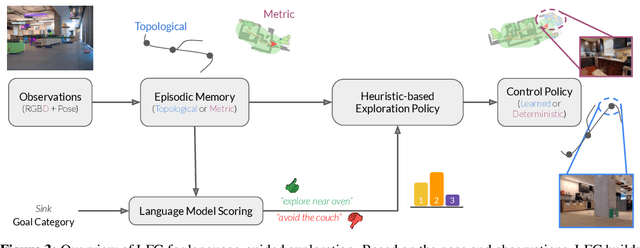
Navigation in unfamiliar environments presents a major challenge for robots: while mapping and planning techniques can be used to build up a representation of the world, quickly discovering a path to a desired goal in unfamiliar settings with such methods often requires lengthy mapping and exploration. Humans can rapidly navigate new environments, particularly indoor environments that are laid out logically, by leveraging semantics -- e.g., a kitchen often adjoins a living room, an exit sign indicates the way out, and so forth. Language models can provide robots with such knowledge, but directly using language models to instruct a robot how to reach some destination can also be impractical: while language models might produce a narrative about how to reach some goal, because they are not grounded in real-world observations, this narrative might be arbitrarily wrong. Therefore, in this paper we study how the ``semantic guesswork'' produced by language models can be utilized as a guiding heuristic for planning algorithms. Our method, Language Frontier Guide (LFG), uses the language model to bias exploration of novel real-world environments by incorporating the semantic knowledge stored in language models as a search heuristic for planning with either topological or metric maps. We evaluate LFG in challenging real-world environments and simulated benchmarks, outperforming uninformed exploration and other ways of using language models.
LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
Jul 10, 2022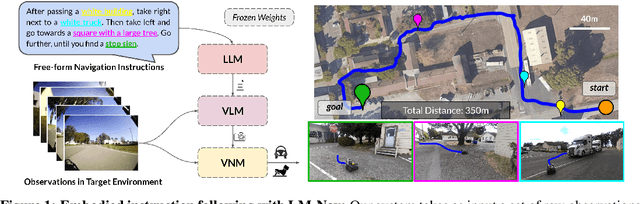

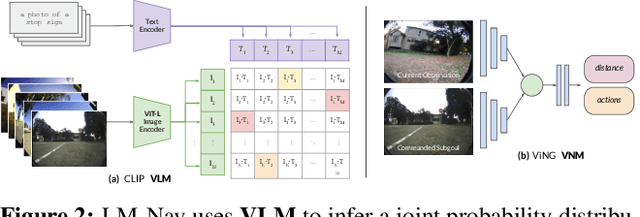
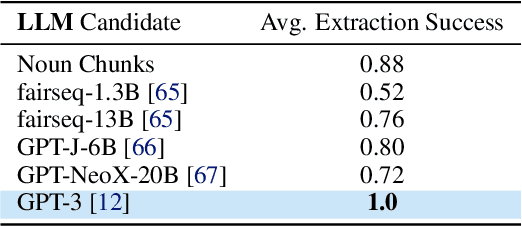
Goal-conditioned policies for robotic navigation can be trained on large, unannotated datasets, providing for good generalization to real-world settings. However, particularly in vision-based settings where specifying goals requires an image, this makes for an unnatural interface. Language provides a more convenient modality for communication with robots, but contemporary methods typically require expensive supervision, in the form of trajectories annotated with language descriptions. We present a system, LM-Nav, for robotic navigation that enjoys the benefits of training on unannotated large datasets of trajectories, while still providing a high-level interface to the user. Instead of utilizing a labeled instruction following dataset, we show that such a system can be constructed entirely out of pre-trained models for navigation (ViNG), image-language association (CLIP), and language modeling (GPT-3), without requiring any fine-tuning or language-annotated robot data. We instantiate LM-Nav on a real-world mobile robot and demonstrate long-horizon navigation through complex, outdoor environments from natural language instructions. For videos of our experiments, code release, and an interactive Colab notebook that runs in your browser, please check out our project page https://sites.google.com/view/lmnav
What data do we need for training an AV motion planner?
May 26, 2021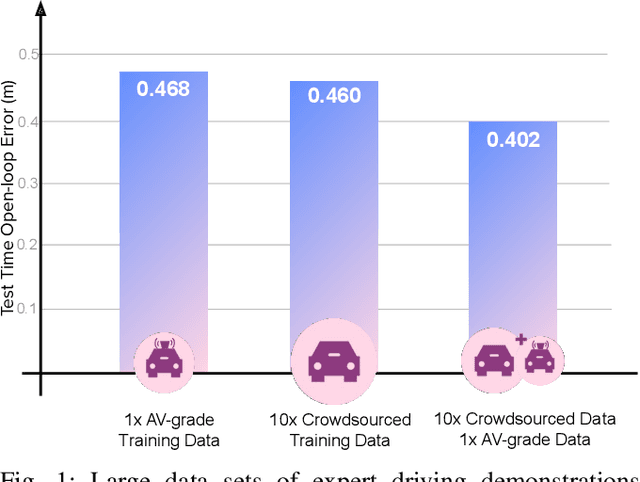
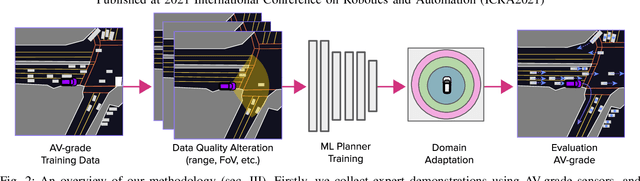
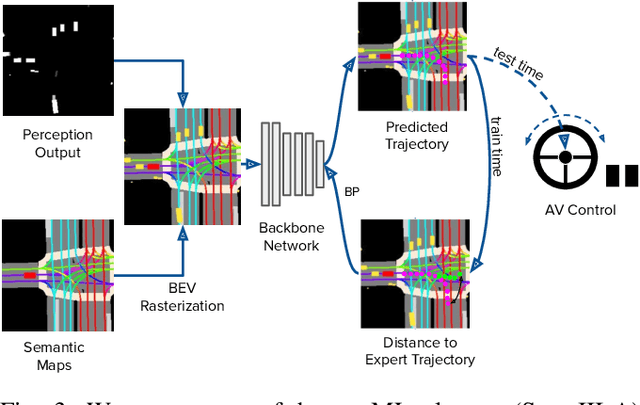
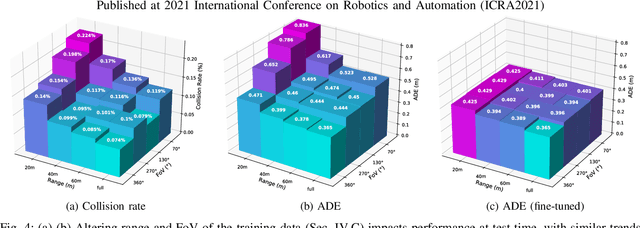
We investigate what grade of sensor data is required for training an imitation-learning-based AV planner on human expert demonstration. Machine-learned planners are very hungry for training data, which is usually collected using vehicles equipped with the same sensors used for autonomous operation. This is costly and non-scalable. If cheaper sensors could be used for collection instead, data availability would go up, which is crucial in a field where data volume requirements are large and availability is small. We present experiments using up to 1000 hours worth of expert demonstration and find that training with 10x lower-quality data outperforms 1x AV-grade data in terms of planner performance. The important implication of this is that cheaper sensors can indeed be used. This serves to improve data access and democratize the field of imitation-based motion planning. Alongside this, we perform a sensitivity analysis of planner performance as a function of perception range, field-of-view, accuracy, and data volume, and the reason why lower-quality data still provide good planning results.
SimNet: Learning Reactive Self-driving Simulations from Real-world Observations
May 26, 2021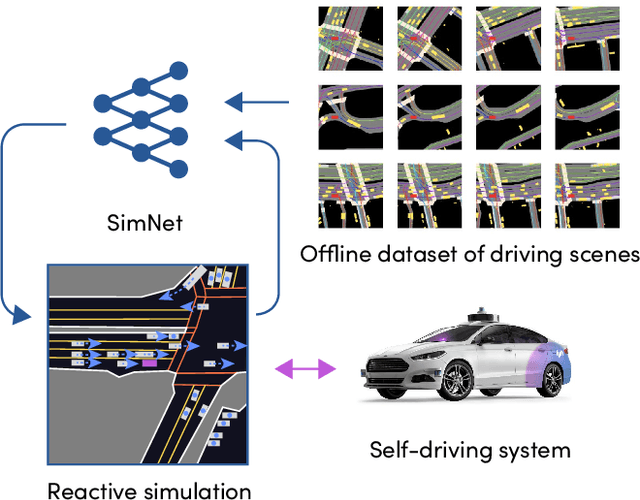
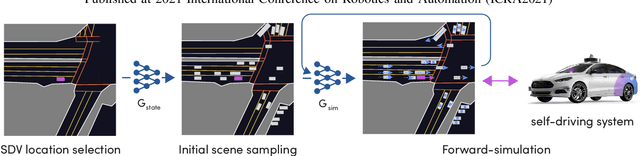
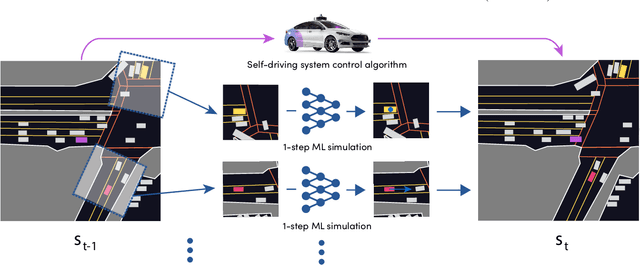
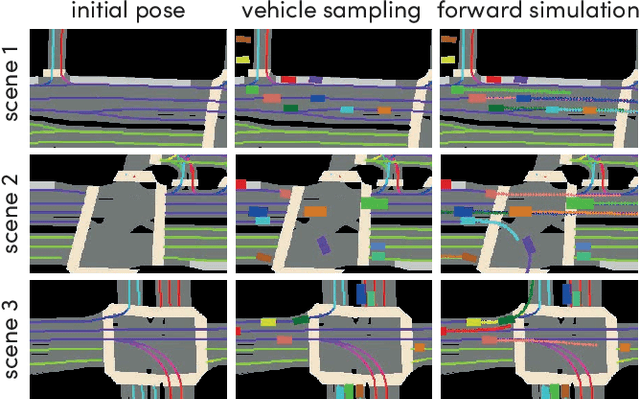
In this work, we present a simple end-to-end trainable machine learning system capable of realistically simulating driving experiences. This can be used for the verification of self-driving system performance without relying on expensive and time-consuming road testing. In particular, we frame the simulation problem as a Markov Process, leveraging deep neural networks to model both state distribution and transition function. These are trainable directly from the existing raw observations without the need for any handcrafting in the form of plant or kinematic models. All that is needed is a dataset of historical traffic episodes. Our formulation allows the system to construct never seen scenes that unfold realistically reacting to the self-driving car's behaviour. We train our system directly from 1,000 hours of driving logs and measure both realism, reactivity of the simulation as the two key properties of the simulation. At the same time, we apply the method to evaluate the performance of a recently proposed state-of-the-art ML planning system trained from human driving logs. We discover this planning system is prone to previously unreported causal confusion issues that are difficult to test by non-reactive simulation. To the best of our knowledge, this is the first work that directly merges highly realistic data-driven simulations with a closed-loop evaluation for self-driving vehicles. We make the data, code, and pre-trained models publicly available to further stimulate simulation development.
Model-Based Reinforcement Learning for Atari
Mar 05, 2019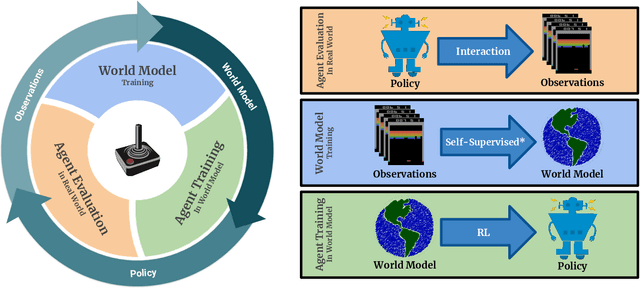
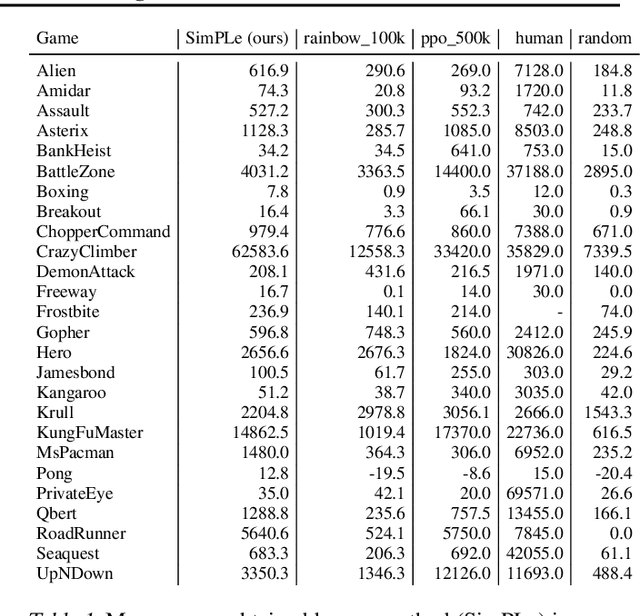
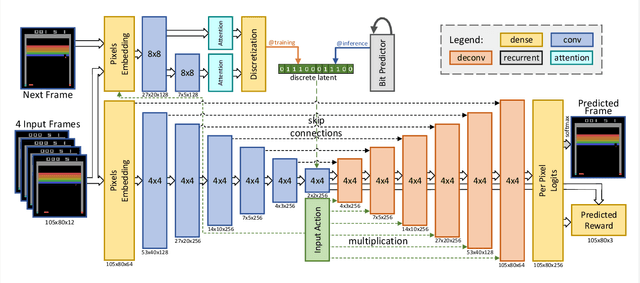
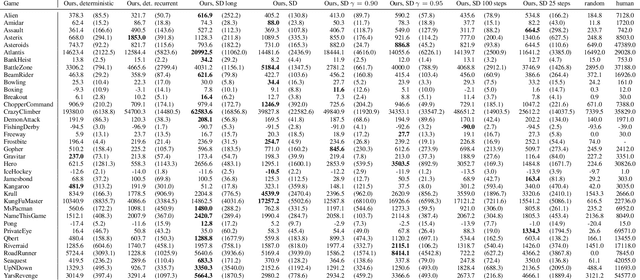
Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with orders of magnitude fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games and achieve competitive results with only 100K interactions between the agent and the environment (400K frames), which corresponds to about two hours of real-time play.